小米代文:用户意图复杂多变,如何构造小爱智能问答的关键技术?

分享嘉宾:代文博士 小米 高级算法工程师
编辑整理:高文龙 58同城
出品平台:DataFunTalk
导读:随着科技的不断发展,人工智能的运用在日常生活中越来越普遍,同时它对于我们的工作和生活方式产生着深远的影响。以小米的小爱同学为例,小爱已经搭载在小米手机、小米AI音箱、小米电视等众多小米生态链设备中,为人们的生活提供方方面面的便捷服务。本文会和大家分享下小米小爱智能问答系统,介绍小爱同学智能问答系统的关键技术及相关的业务形态。
主要围绕下面四点展开:
小爱同学智能问答系统背景介绍
图谱问答
检索问答
阅读理解
在小米公司的手机+AIOT的战略当中,小爱同学作为AIOT的入口,具有重要的作用。通过小爱同学,用户可以在智能家居、智能车载等场景当中享受到小爱同学带来的便捷生活服务。
目前搭载小爱同学的智能硬件包括手机、音箱、智能穿戴、智能车载、电视、儿童设备等,通过使用这些设备用户可以享受到6大方面的服务,包括内容、信息查询、互动、控制、生活服务、基础工具。
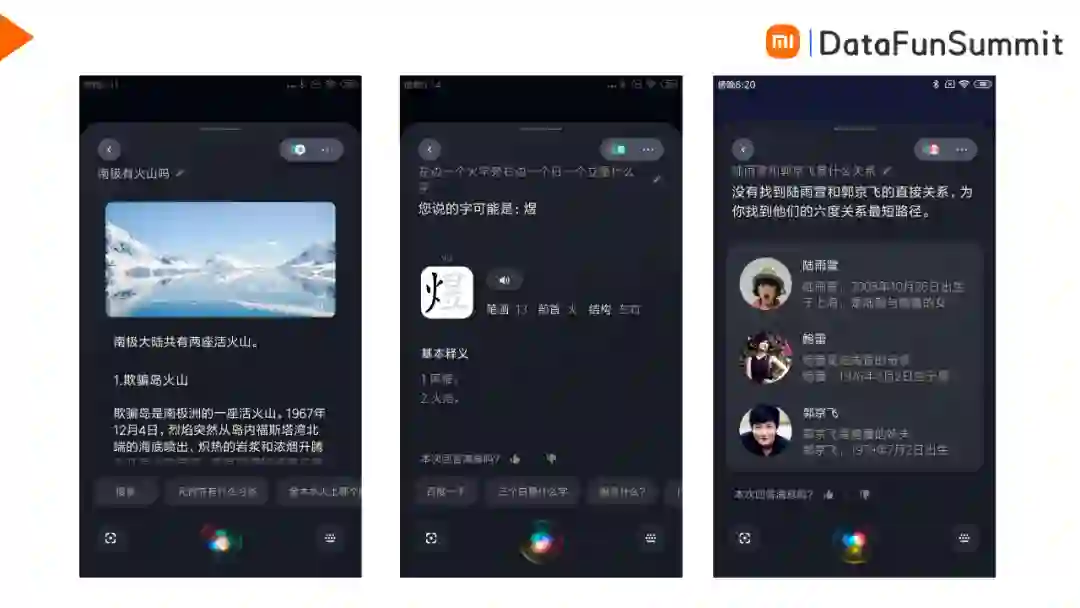
小爱同学具体的垂域功能有语音控制、音乐、闲聊、时间、智能问答等。例如,用户可以通过语音控制来指挥家里的小米电视、扫地机器人等;用户可以通过小爱音箱来享受音乐;用户可以和小爱同学进行对话以及查询服务等。在本次分享中介绍的智能问答系统,针对的是有客观事实性答案的Query,主要是用来满足用户信息查询类的需求,简单来说就是用户询问一个知识类的问题,系统会基于庞大的知识库来给出相应的答案。如下图所示为产品效果图,比如,当用户询问陆雨萱与郭京飞是什么关系时,系统会从图谱中找到两者的关系路径,向用户回答鲍蕾是陆雨萱的母亲,郭京飞是鲍蕾的妹夫,这样就展现出两者之间间接的关联关系,用户假如对其中的中间人物感兴趣,可以点进去进一步的浏览。
我们的智能问答系统主要包含三种问答模块,分别是图谱问答、检索问答和阅读理解问答。
下面,首先介绍基于知识图谱的智能问答,也就是大家所熟知的图谱问答。
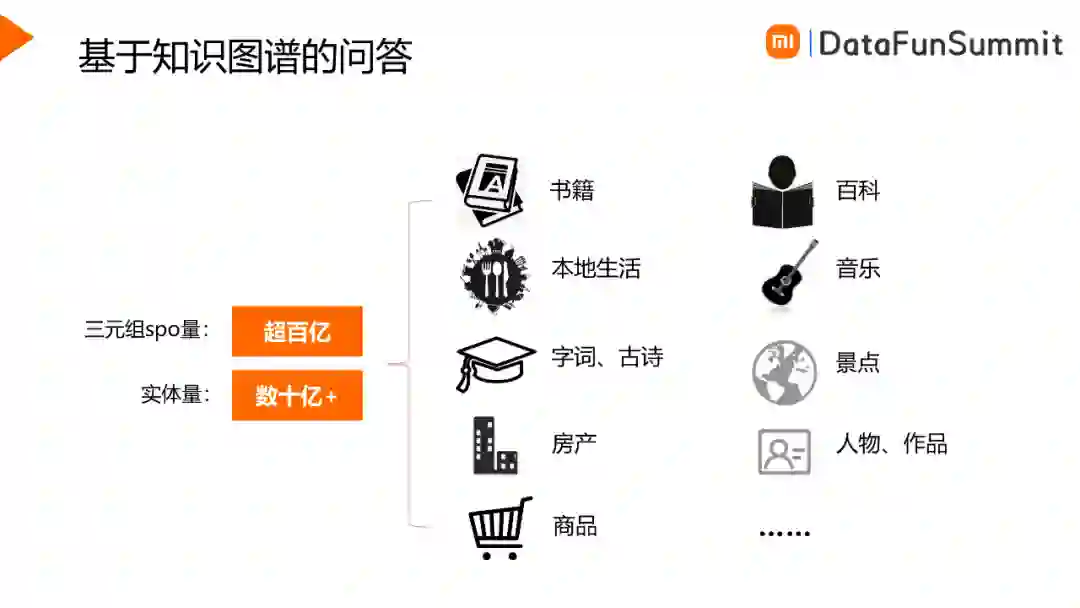
知识图谱是图谱问答的数据基础。小米AI实验室构建了超大规模的知识图谱,其中包含的领域很多,例如书籍、本地生活、古诗词、房产、商品、音乐、人物作品等。基于已构建的超大规模知识图谱,我们开展了以下几方面的研究并应用于线上:
基于模版的方法
跨垂域粗粒度的语义解析方法
基于路径匹配的方法
首先和大家介绍基于模板的方法。
1. 基于模版的方法
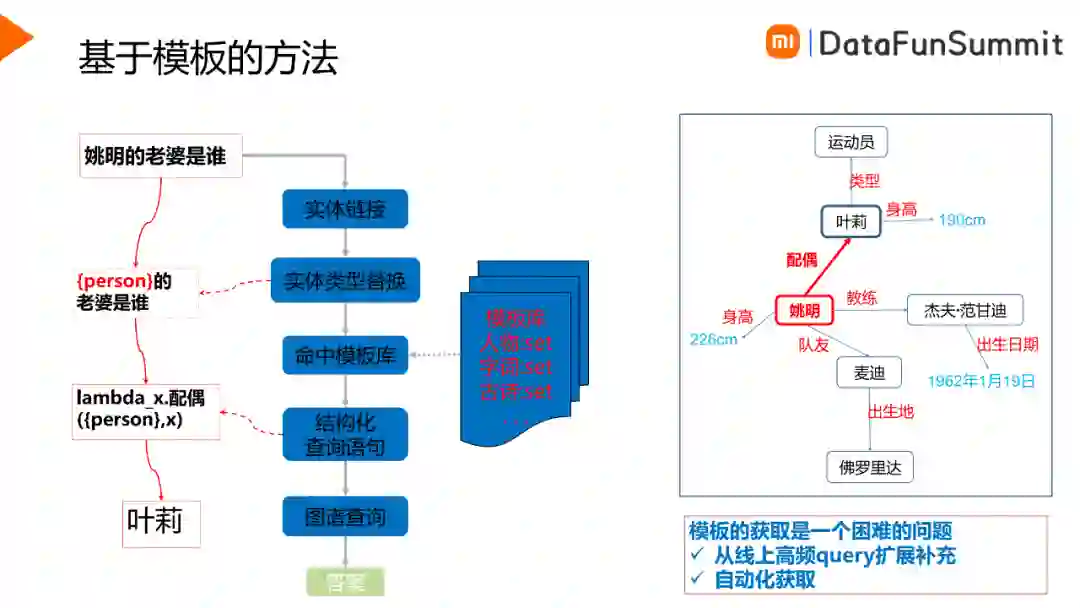
基于模板的方法相对比较简单,核心思想主要是在模板库中找到与用户Query最相似的模板,根据模板对应的解析从图谱中达到答案,以此来回答用户的问题。在这个过程中,模板获取是一个困难的问题,可以人工从线上高频Query进行扩展补充,另外也可以通过自动化的手段快速获取大批量的模板。

如上图所示,是一个快速获取批量模板的方法。例如有一个结构化的词条李白,词条当中有一个属性“所处时代”对应的取值为“唐朝”,如果一个问答对中的Query包含“李白”,Answer中包含“唐朝”,那么这个问答对很有可能询问的就是“所处时代”这个信息,因此就可以得到一个模板“xxx是什么朝代的”。依次类推遍历所有问答对数据,对模板进行频次统计,通过人工过滤就可以得到高质量的模板库。
线上用户所询问的问题不仅仅是简单的问题,很可能会附带一些约束,比如时间约束、位置约束、最大最小值查询的约束等。在我们的场景中,用户常问的问题属于世界之最的问题,例如用户不仅是想知道老虎的体重是多少,可能还想知道体重最大的猫科动物是什么。针对于世界之最的问题,我们的解决方案如下图所示:
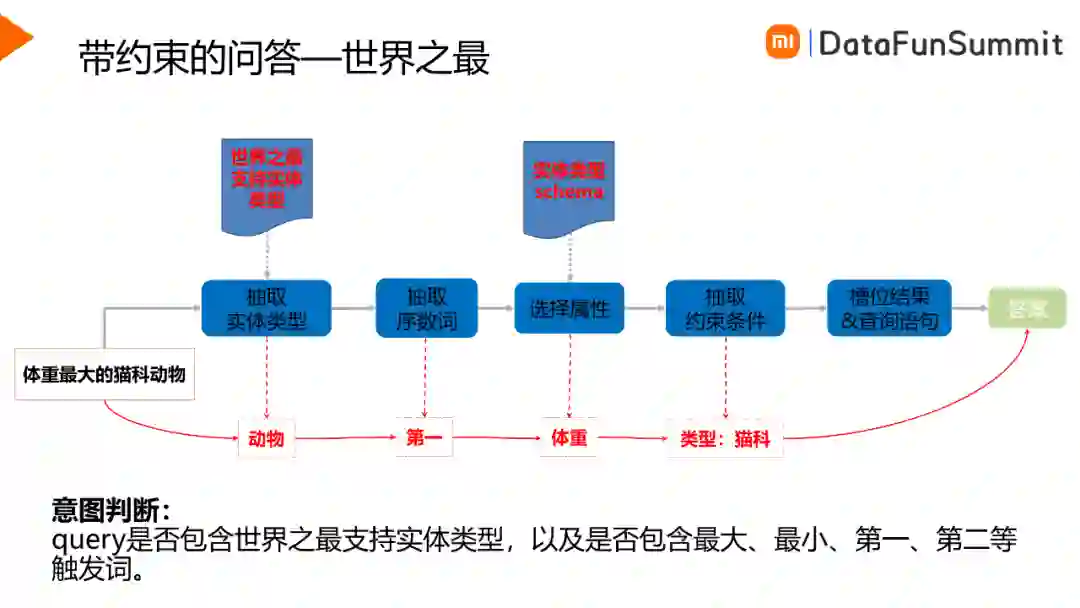
首先从用户Query中抽取实体类型,比如“体重最大的猫科动物”,实体类型就是动物,其次需要抽取出序数词,确定最大的,第二大的还是第三大的,然后需要确定询问的是动物哪方面的信息,以选择排序的属性字段,另外很多时候用户Query中可能会对实体类型加一些约束,比如在上图所示例子中,用户询问的是猫科类的动物,那么猫科类就是在动物上添加的约束,根据以上步骤便可提取出相关槽位并构造查询语句,从而从知识图谱中获取答案并返回用户。

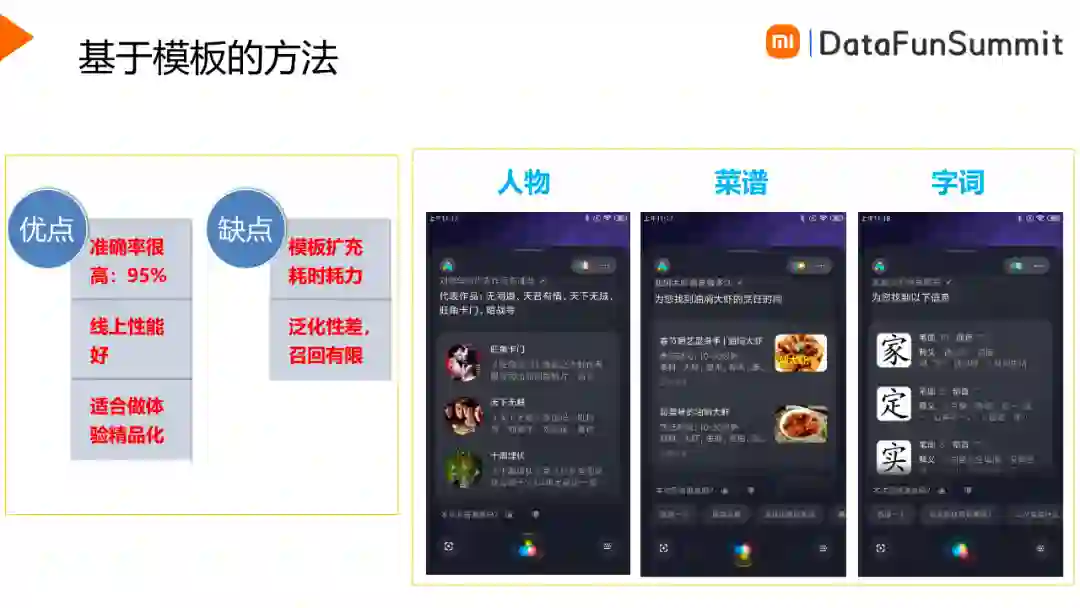
基于模板的方法准确率比较高,线上性能表现的较好,另外比较适合做体验精品化,如上图所示,通过结构化的解析,将结构化的字段向用户展示,给用户带来更好的体验。基于模板的方法缺点也比较明显,首先就是模板的扩充耗时耗力,需要大量人工处理,另外它的泛化性比较差,召回也相对有限。
2. 跨垂域粗粒度的语义解析方法
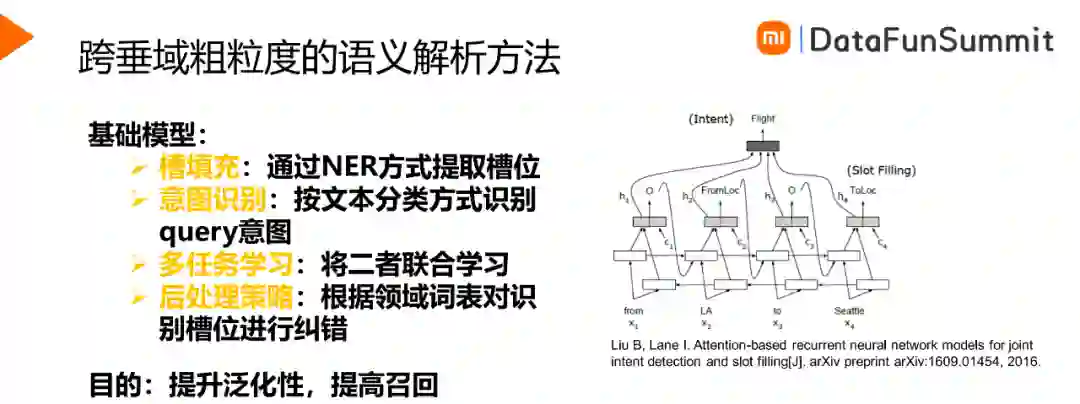
跨垂域粗粒度语义解析方法的基础模型是槽填充与意图识别的联合模型,如下图所示,通过时序网络对输入的token进行向量表示,向量通过CRF层得到对应的标签,另外可以得到表征句子的向量,用来对句子的意图进行分类。通过对这两个任务的联合学习,可以同时预测句子的意图与槽位,泛化性比较好,召回率也有所提升。
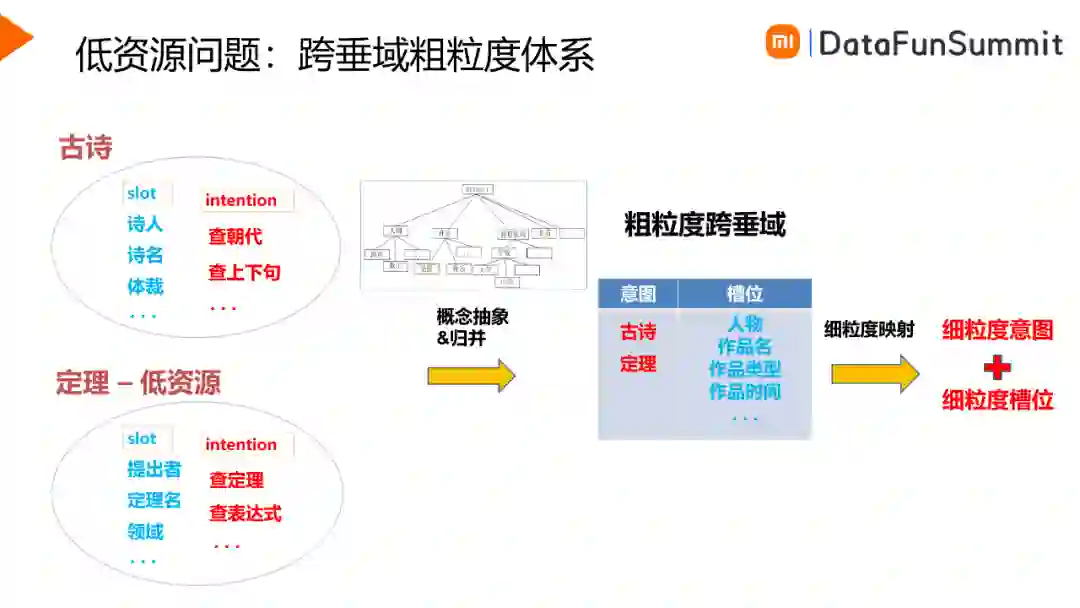
比如我们要建设古诗垂域,如上图所示,首先定义好古诗垂域下的意图与槽位,古诗相关的槽位包括诗人、诗名、体裁等,意图包含查朝代,查上下句等。根据定义好的体系,获取训练数据,之后可以进行意图/槽位联合模型的训练,最终在线上部署并生效。建立新的垂域需要进行重复的工作,另外在小垂域方面训练样本比较少,样本标注的成本相对较高,这是垂域建设面临的问题和挑战。为此我们提出了一种跨垂域粗粒度的体系,可以将意图槽位体系进行抽象与归并。假如我们要新建定理垂域,它的训练数据非常稀疏,那么我们可以对意图和槽位进行归并。比如,在槽位上,诗人与提出者都属于人物,那么我们就可以归并为人物。类似的,诗名和定理名可以归并为作品名。每个垂域独有的槽位可以直接继承下来。在意图上,直接使用两个垂类作为类别,得到粗粒度的意图体系。预测的时候,我们先得到粗粒度的意图和槽位结果,然后通过映射关系得到细粒度的意图和槽位,作为最终的解析结果。
3. 基于路径匹配的方法
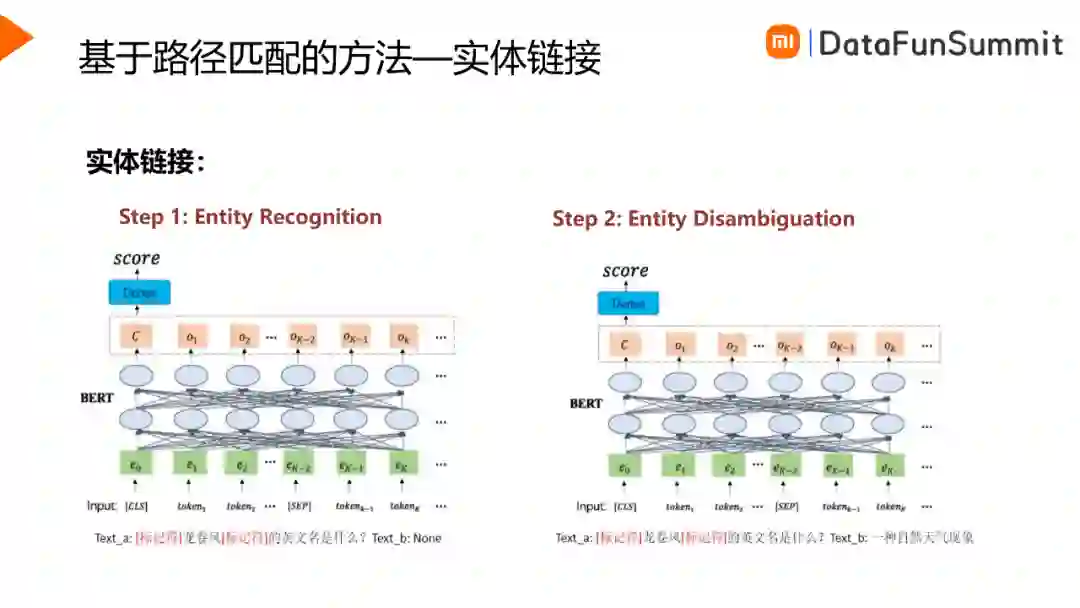
当用户Query更加复杂,比如需要进行多步推理才能获得答案时,前面方法也会失效,而基于路径的方法对复杂Query的解析更好。基于路径的方法不受模板约束,也不需要槽位抽取。它首先从图谱中挖掘一些候选的路径,根据候选的路径进行匹配排序,选取最有可能的路径回答用户的问题。这种方法主要包含以下三个步骤:实体链接、子图检索与子图匹配。
实体链接主要是从Query中寻找核心实体,如上图所示,对于Query“龙卷风的英文名是什么”,我们需要知道用户询问的核心是龙卷风。实体链接主要包含实体识别与实体消歧两方面。篇幅所限,本文不在实体链接上展开介绍。
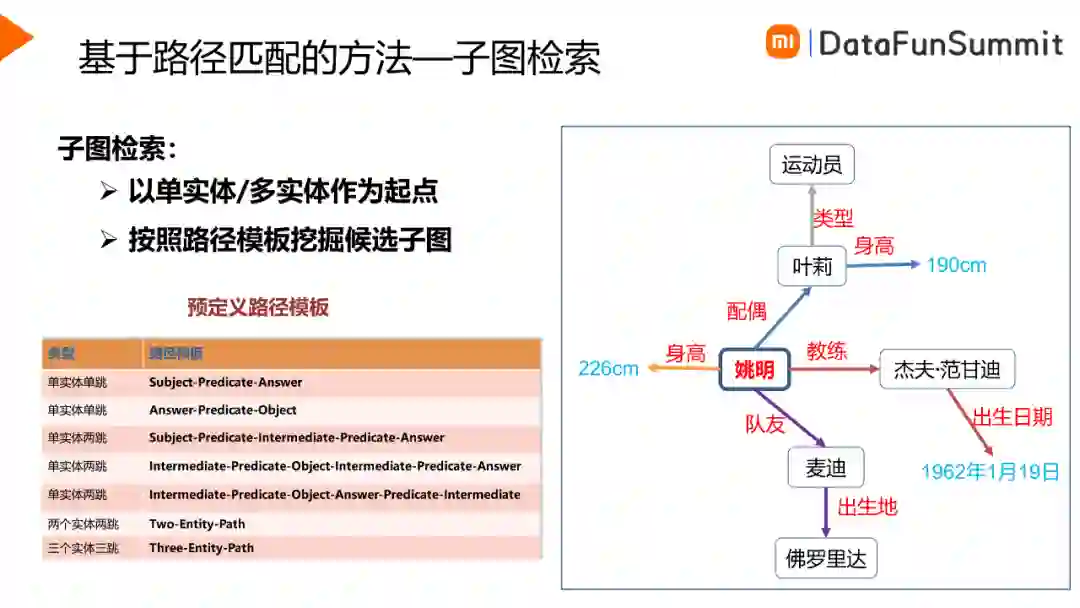
子图检索主要分为路径挖掘和约束添加两步。首先是路径挖掘,以实体链接步骤中所确定的单实体/多实体作为起点,根据定义的路径模板在图谱中挖掘候选子图。如上图所示,在“姚明”作为起点,可以得到的路径举例如下:。
单跳路径:select ?x where <姚明> <配偶> ?x
多跳路径:select ?y where<姚明> <配偶> ?x ?x <身高> ?y
常见的路径模板如上图表中所示,基本上覆盖了绝大部分的Query情形。
然后是约束添加。当Query中包含约束情形的时候,我们需要将这个约束添加在合适的位置。比如,当Query为“姚明的队友中谁的身高在200cm以上”时,就需要在路径“select ?x where<姚明> <队友> ?x ?x <身高> ?y”上添加约束,限制中间节点?y>=200cm。我们总结了两种约束类型:
过滤约束:当Query中包含数值时,我们将这个数值作为过滤约束添加到取值为数值的中间节点上。可以用来添加过滤约束的谓词,典型的有价格、距离、时间等。
排序约束:当Query中包含序数词(最大、第二高等)时,我们将这个虚数作为排序约束添加到取值为数值的中间节点上。
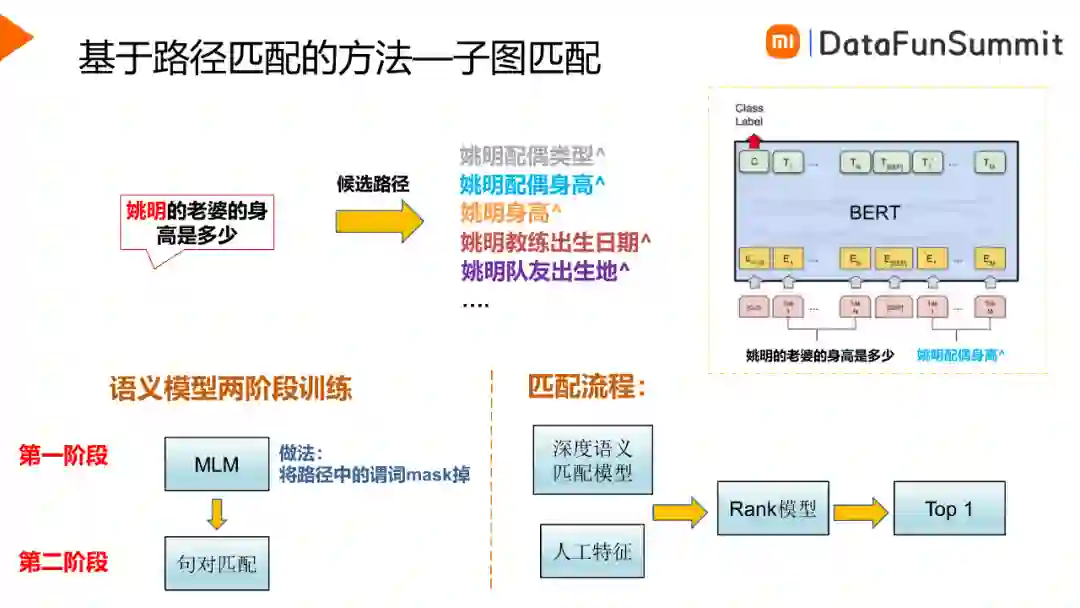
对上步骤得到的候选路径进行子图匹配,匹配时将子图转换为文本描述的形式,转换的时候只需要保留节点信息,要去掉中间节点,另外将答案节点以^代替。对于过滤约束,我们以“大于”、“小于”作为谓词;对于排序约束,我们以“排名”作为谓词。这样的话,子图匹配就变为了一个句对匹配的任务。如上图所示,句子一是用户的Query“姚明的老婆的身高是多少”,句子二是候选路径的文本描述形式:“姚明配偶身高^”,训练一个句对匹配的模型。路径匹配中的谓词是一个重要的因素,谓词决定后续路径的正确与否。因此模型训练分为两个阶段,首先是将路径中的谓词mask掉进行预训练,然后是进行句对匹配的fine-tuning训练。得到语义匹配模型之后结合人工特征进行重排序得到TOP1路径,并从图谱当中获取答案来回答用户的问题。
基于以上方案,我们在CCKS2020新冠知识图谱问答评测中获得了第三名,在CCKS2021生活服务知识图谱问答评测中获得第一名。
接下来介绍基于检索的问答形式。
基于检索的FAQ问答针对的是非结构化的Query,比如WHY、HOW、WHETHER类的问题等,对于这种非结构化的问题,难以通过结构化的解析来进行回答。因此通常是通过在问答库中搜索相似的问题来回答用户问题。
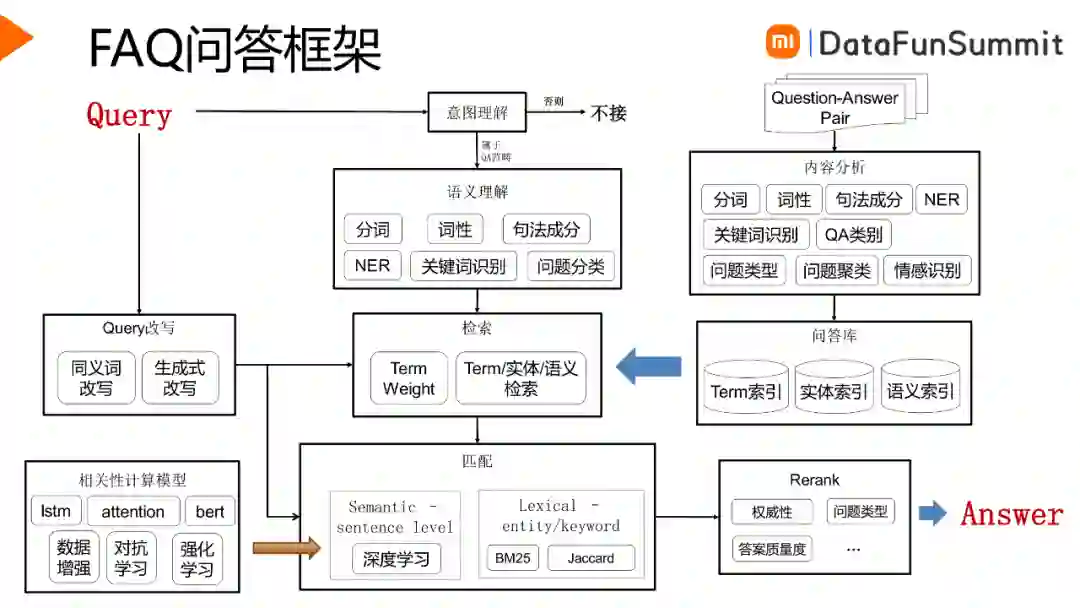
如图所示是一个FAQ问答框架,右半部分是线下工作,主要是问答库的线下建设。左半部分是线上的技术流程,主要包括意图理解、检索、语义匹配和重排序等步骤。这里,我们主要介绍检索和匹配这两个主要环节。
1. 检索

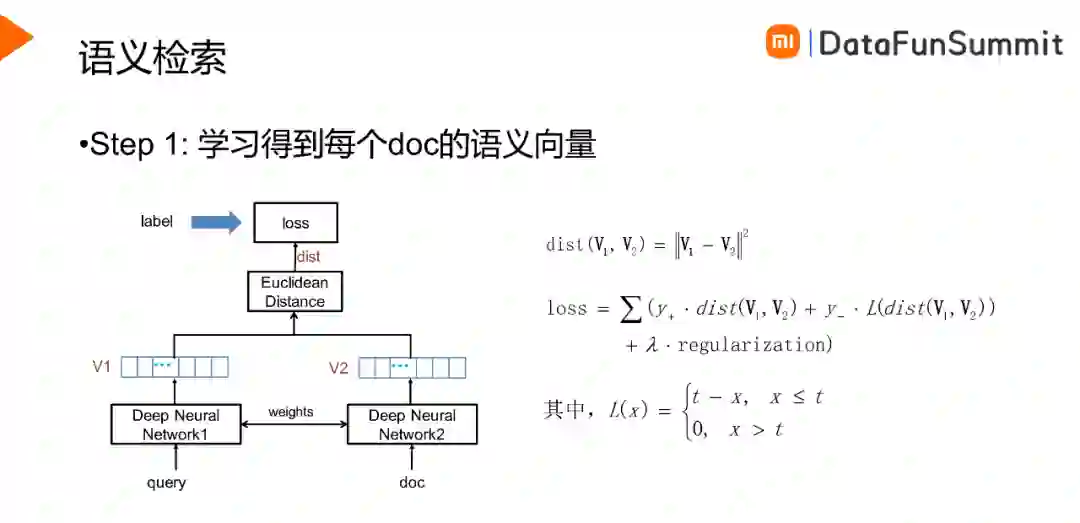
语义检索首先要得到每个doc的语义向量,其中doc指的是QA对中的相似Q。如上图所示,将Query与doc输入至孪生网络中得到两个句子的语义向量,希望正样本的距离越近,负样本的距离越大,在此监督之下对神经网络的参数进行学习。然后,我们综合考虑效果和性能,选择最合适的孪生网络,并用于推理得到全量QA数据的语义向量。在线上,搭建faiss语义检索服务,以docid作为key,语义向量作为value,寻找最近邻doc,并通过docid获取doc内容。
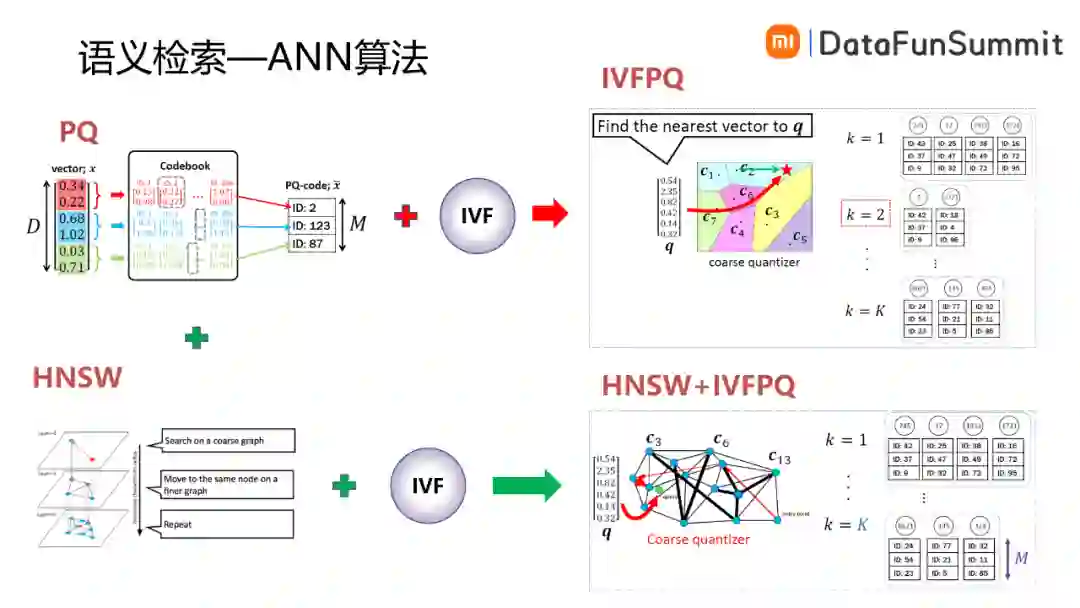
线上全量检索时,用户Query的语义向量与doc的语义向量一一进行匹配计算对服务的性能要求很高,另外加载全部的数据内存占用也比较大。研究者提出了很多ANN最近邻算法优化检索性能。如上图所示,IVF的思路是将doc向量进行聚类,找到与用户Query最近的类,然后在类内找到最近的语义向量,这样可以明显减少耗时,但无法解决语义向量占用内存高的问题。PQ则是牺牲一定的精度,将高维语义向量进行降维,获取更低的内存占用。将PQ与IVF联合可以得到IVFPQ,它首先找到与用户Query最近的类,将类内的语义向量进行降维,这样既可以降低内存占用,又可以提升性能。HNSW是一个分层的最近邻网络,越上层是越粗略的层,越下层是越细致的层。首先根据用户Query在最上层找到最近的节点,然后映射到下一层找到下一层中最近的点,依次类推得到最后的结果。它同样可以与IVF进行结合得到HNSW+IVFPQ的检索方式。
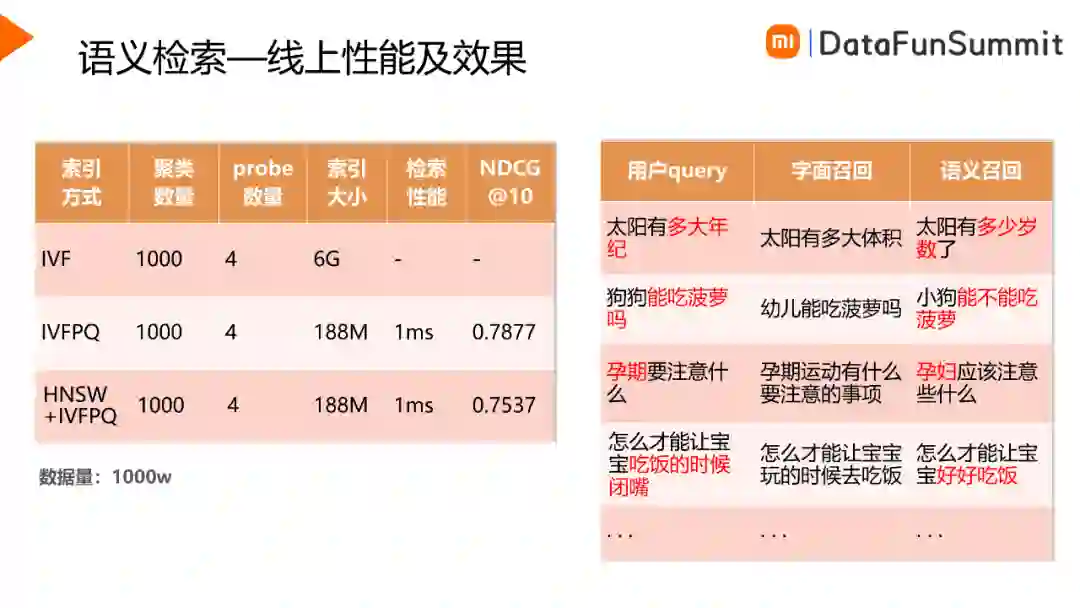
如下图所示是语义检索性能与效果的实验对比,在1000w的数据下,IVF检索的内存占用是6G,内存占用偏高。IVFPQ的内存占用下降到188M,检索耗时是1ms,HNSW+IVFPQ在内存占用与检索性能上相差不大,在效果上稍差,最终我们选用的是IVFPQ的检索方式。通过语义索引可以解决线上的一些badcase,例如“太阳有多大年纪”,term检索通道召回的可能是“太阳有多大体积”,通过语义检索可以召回“太阳有多少岁数了”。
2. 匹配
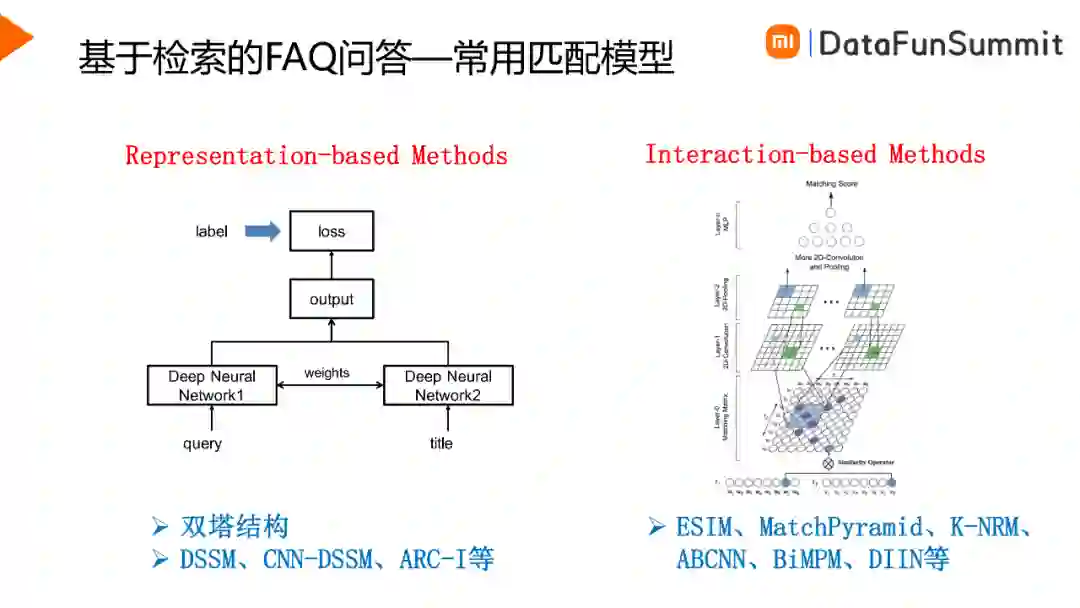
传统的匹配模型是通过字面匹配构建特征,然后通过机器学习模型计算得到句对的语义相似度。目前深度学习方法占据主流,主要有两种方法,一种是根据两个句子的向量联合对相似度进行表征的Representation_based Methods,如DSSM模型,另一种是对两个句子两两词之间的相关度进行表征的Intercation-based Methods,如ESIM等模型。使用大规模预训练语言模型进行句对匹配的方式,也是属于第二种类别。
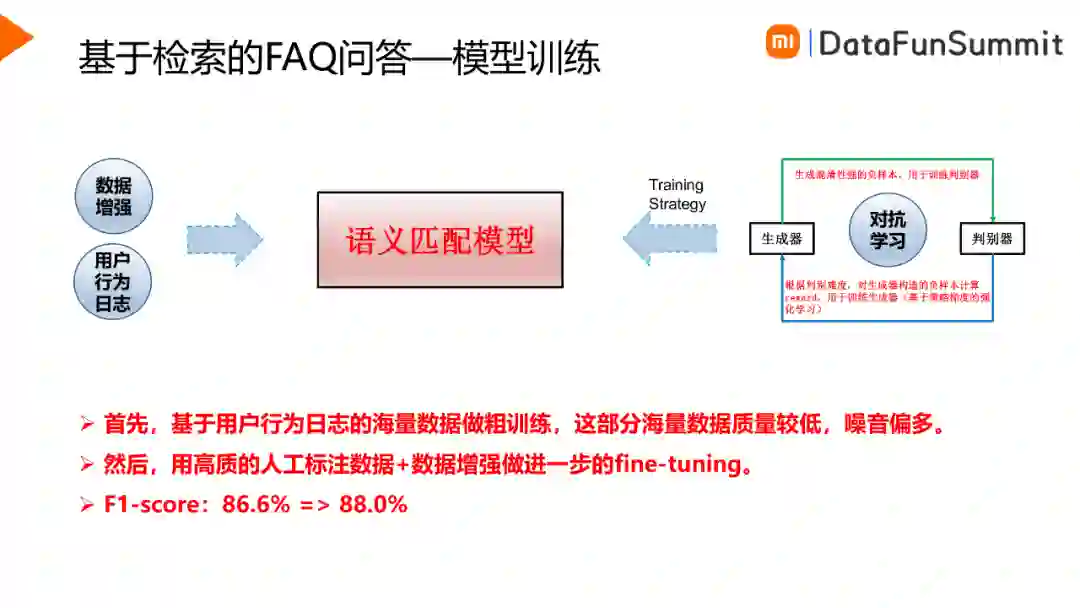
在进行语义匹配模型训练时,我们分为两个阶段来进行训练:
首先,基于用户行为日志做粗训练。用户行为可以是点赞点踩、停留时长等。基于用户的正/负向行为挖掘正/负样本,这样可以快速地挖掘得到大批量的训练样本,但是样本质量一般。
然后,用高质量的人工标注数据做进一步的训练。
另外可以尝试引入对抗学习方式,通过生成器生成一些难于判别的样本,用于判别器的学习。样本比较小时,对抗学习可以加速模型收敛,样本足够时,效果则没有那么明显。

高质量的人工标注数据对匹配模型的效果影响很大,所以我们尝试了通过数据增强来提升人工标注数据的样本量。如图所示,一对正样本Q1与Q2,可以分别找到Q1、Q2的相似性样本Q1’与Q2’,可以得到增强的结果Q1’与Q2。同样类似的方法可以构造负样本,以此提升语义匹配效果。
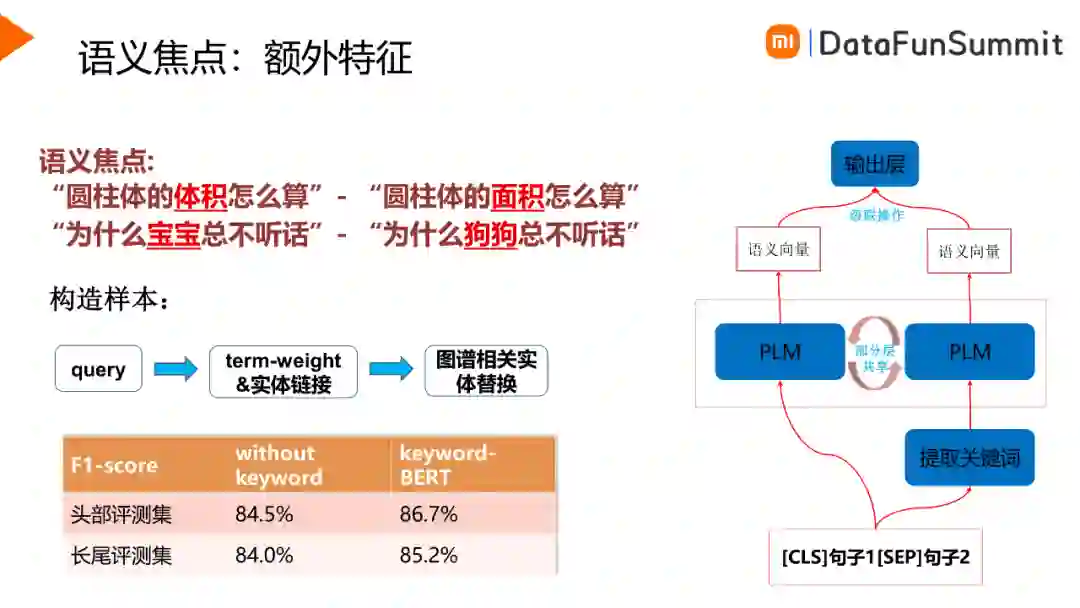
语义匹配方面会遇到语义焦点的问题,例如“圆柱体的体积如何计算”和“圆柱体的面积怎么算”,这两个句子只有核心词不一样,会容易造成模型误判,因此可以引入一些额外特征强化模型对核心词的学习。如上图所示,额外特征为提取的关键词,通过PLM对关键词进行表征,并与原句子的特征进行级联以计算相似度。
阅读理解模型使用的是基于span的阅读理解模型,由于阅读理解模型的可控性不够好,准确率难以适应业务需求,所以我们从业务出发限制了只在特定类型的query,并且图谱问答、检索问答召回不了的时候才考虑使用阅读理解技术召回。例如询问鲁迅姓什么,那么我们就以鲁迅的百科简介作为passage,从中提取答案片段。这样,这个模块的准确率才更能适应业务的需求。

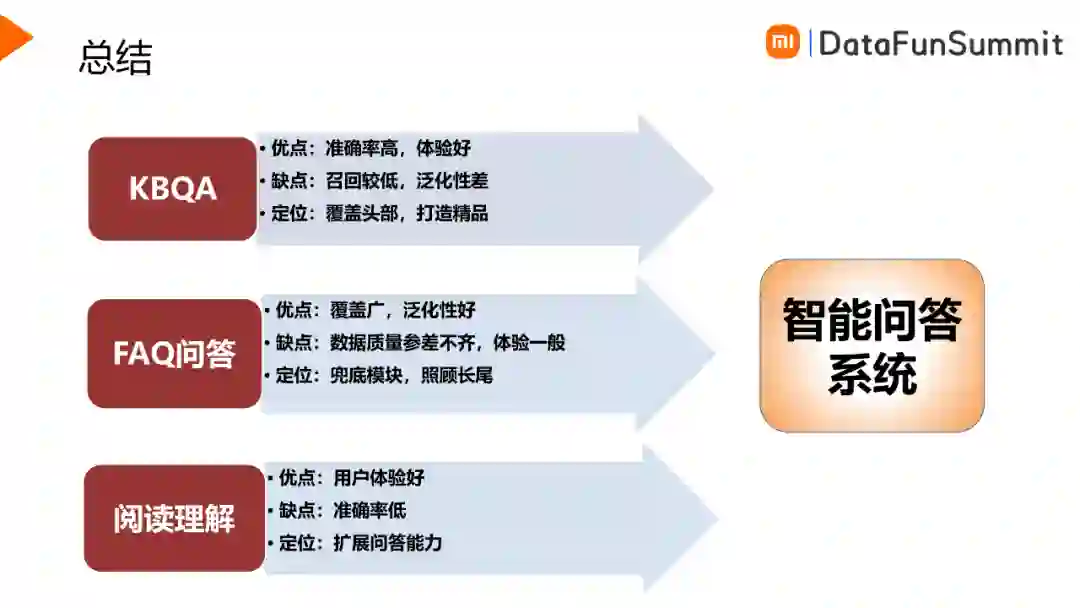
智能问答系统运用到三个形式的问答技术,分别是KBQA、FAQ与阅读理解。KBQA的优点是准确率高,体验较好,缺点是召回低,定位是覆盖头部,占据主要的流量。FAQ的优点是覆盖广,泛化性好,缺点是数据质量参差不齐,体验一般,定位是兜底模块,照顾长尾。阅读理解的优点是用户体验好,缺点是准确率低,定位是扩展问答能力。
今天的分享就到这里,谢谢大家。
分享嘉宾:

专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“问答” 就可以获取《专知自动问答资料合集》专知下载链接







