KoPL: 面向知识的推理问答编程语言
关注我们
了解更多知识图谱前沿信息
总体介绍
问答系统是自然语言处理领域的一个重要研究方向。一方面,图灵测试的场景本身就是问答。如果我们有了和人一样智能的问答系统,那么就相当于通过了图灵测试。因此问答相关研究始终受到人工智能学者的重视。从知识工程、推理机、专家系统,到搜索引擎,智能助手甚至机器人,问答系统贯穿了人工智能的整个发展历程。另一方面,问答作为人类最自然的交互方式,有非常广泛的应用需求。在信息浩如烟海的互联网时代,问答系统可以帮助用户快速并准确地获取信息,让人们的生活更加便利,甚至可以部分地替代人工劳动,例如替代人工客服对客户进行自动回答,更加高效经济地解决现实问题。
如图1所示,在早期的研究中,研究者主要关注单个关系型知识,即问题中仅涉及单个三元组,如“勒布朗·詹姆斯的父亲是谁”,只需要在知识资源中进行检索和匹配,就可以得到答案。这一类问答被称为简单问答。然而在很多情况下,问题不能通过检索和匹配直接得到答案,而是需要处理多跳关系、集合操作、属性比较等情况。例如问题“布朗尼·詹姆斯和他的父亲谁更高”,需要找到布朗尼·詹姆斯的父亲,并比较两个人的身高属性。这类针对复杂问题的问答任务称为推理问答。处理这些复杂问题要求计算机实现知识的表示和推理,并且能够处理Wikidata等结构化知识和Wikipedia等百科资源。
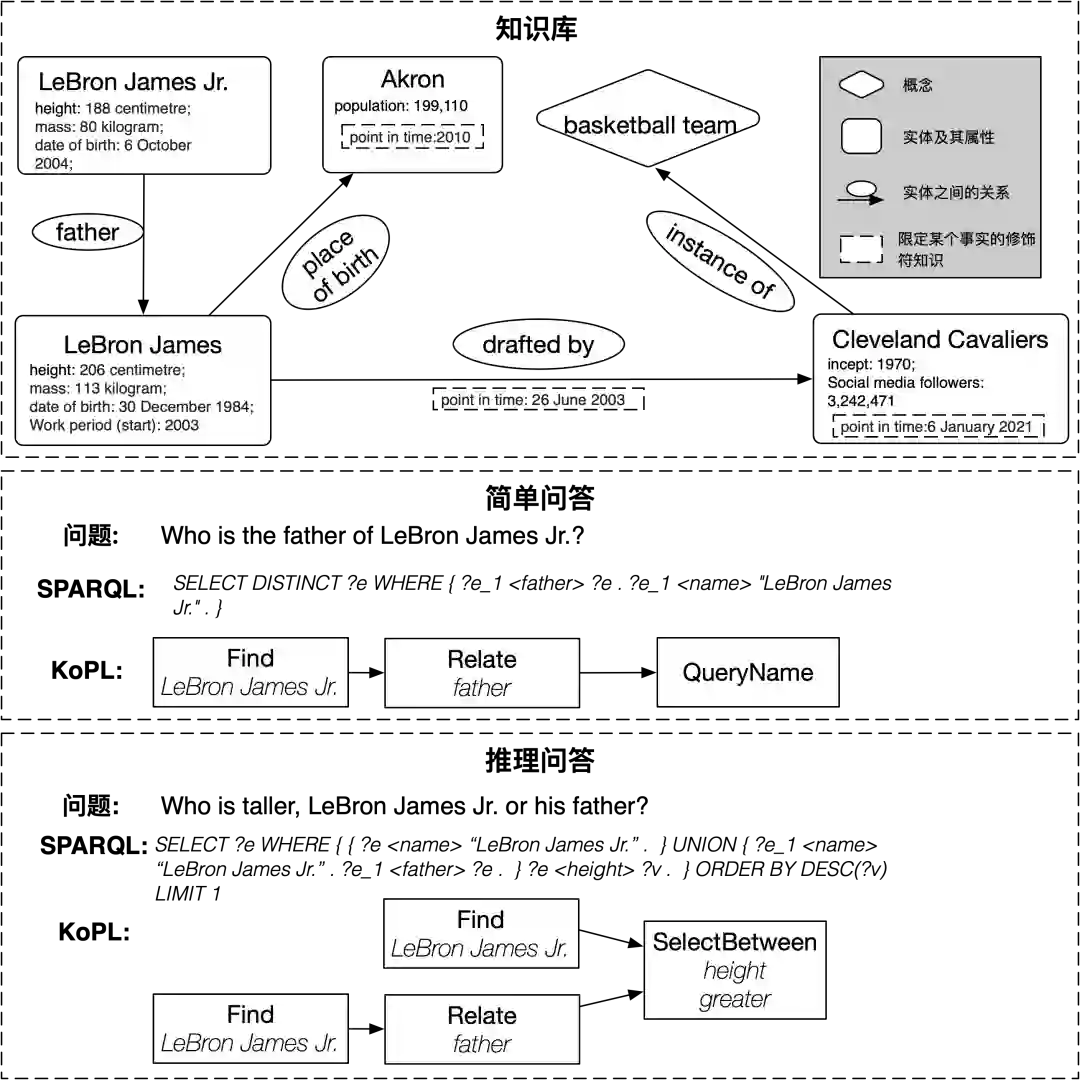
图 1 推理问答及对应的KoPL表示
1. 提供显式、透明的推理过程。不同于SPARQL将查询图和知识库进行图模式匹配来得到答案,KoPL将复杂问题转化为推理函数的组合,以代表推理过程,具有显式和透明的特点。
2. 易于理解,便于人机交互。如图2所示,KoPL程序以流程图的形式呈现给用户,推理过程清晰明了,对于推理错误的部分可以更加容易地修改。如只需把QueryRelationQualifier函数的第二个参数”followed by”修改为”follow”,就可以得到正确的KoPL程序。

图 2 KoPL更易于理解,便于用户进行修改。修改过程用红色标出。
3. 面向知识库、文本等不同形式的知识,可扩展性强。KoPL是一个为面向知识的复杂推理问答而设计的编程语言,不仅局限在知识库问答。目前开源的KoPL工具包中已实现对任意知识库的支持,未来,我们会将KoPL扩展为同时支持知识库和文本的推理问答工具。
KoPL特色
(一)面向多种知识元素
(1)实体 (entity),表示一个独一无二的事物,如图3中的勒布朗·詹姆斯 (LeBron James);
(2)概念 (concept),一组具有相同特征的实体组成的集合,如图3中的篮球队 (basketball team);
(3)属性 (attribute),表示实体的属性信息。由属性键和属性值两部分组成,属性值有字符串、数字、日期和年份4种类型。如身高(height)是一个属性,206厘米(206 centimetre)是对应的属性值;
(4)关系 (relation),表示两个实体之间的关系。特殊地,实体通过 instance of 关系链接到相应的概念上,概念之间通过 subclass of 关系来组织成层次结构。如父亲(father)和出生地(place of birth)都是关系;
(5)属性型事实 (literal fact),表示一个实体属性信息的三元组,由(实体,属性键,属性值)组成。如(勒布朗·詹姆斯,身高,206厘米)是一个属性型事实;
(6)关系型事实 (relational fact),表示两个实体间关系的三元组, 由(实体,关系,实体)组成。如(勒布朗·詹姆斯,出生地,阿克伦)是一个关系型事实;
(7)修饰型事实 (qualifier fact),对一个关系型或属性型的三元组进行进一步的修饰,包含一个修饰键(qualifier key)和一个修饰值(qualifier value)。由(三元组,修饰键,修饰值)组成,如((勒布朗·詹姆斯,被挑选,克利夫兰骑士队),时间,2003年)是一个修饰型事实。
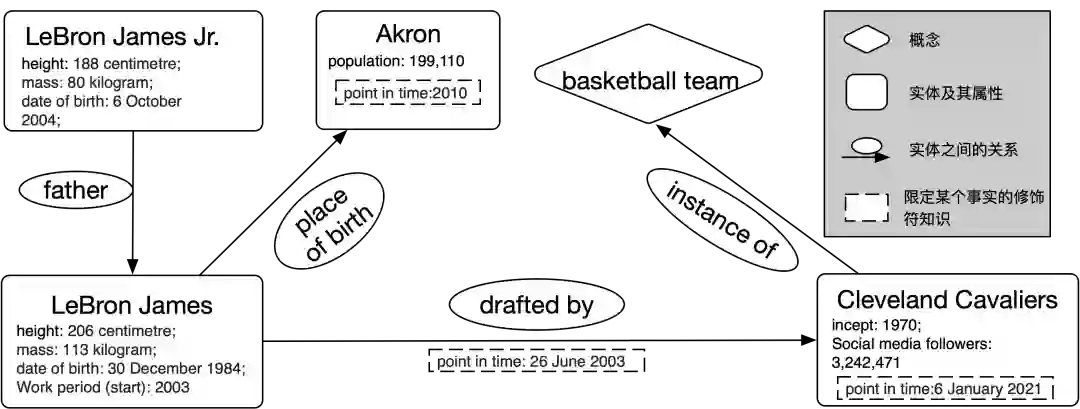
图 3 知识元素
(二)覆盖多种知识操作
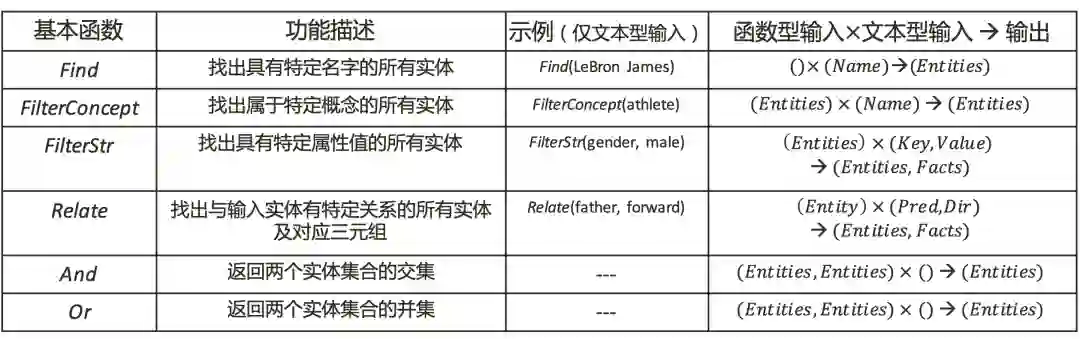
图 4 部分知识操作函数
(三)支持多种问答类型
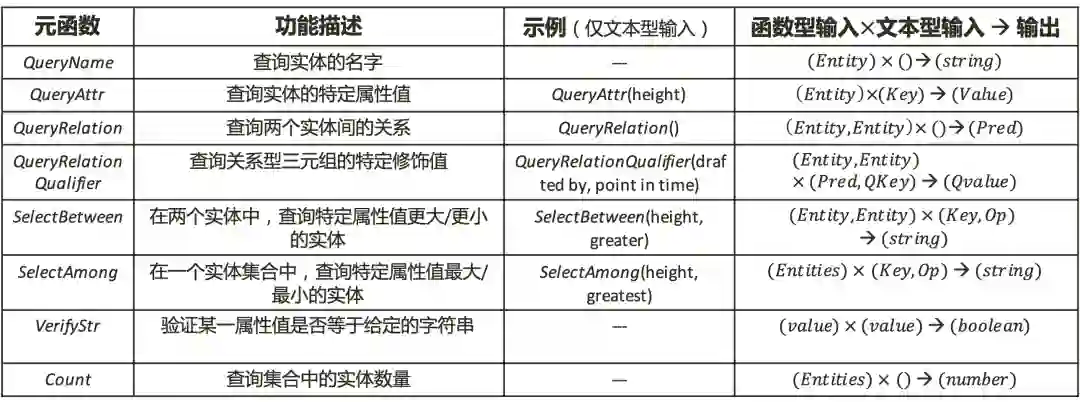
图 5 部分查询函数
(四)提供透明的推理过程
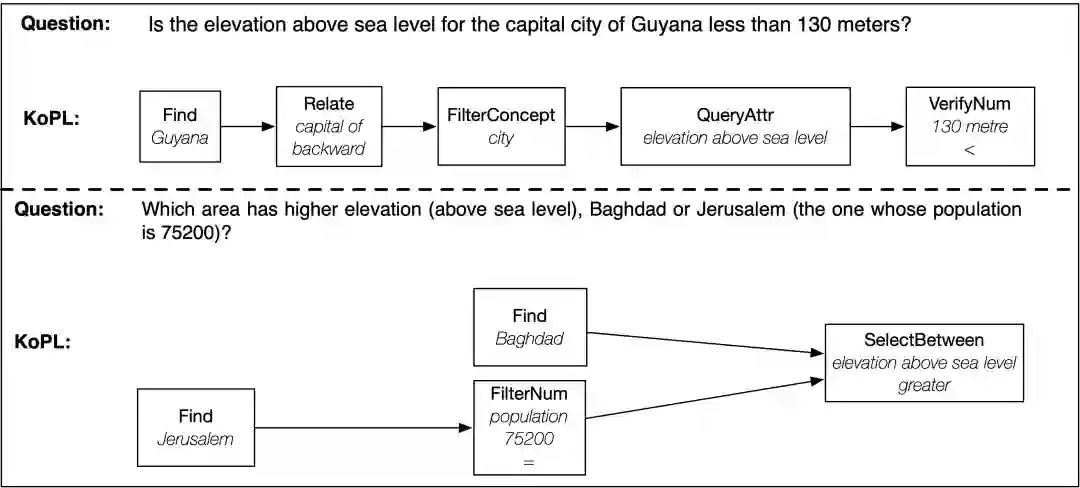
图 6 KoPL提供透明的推理过程
KoPL开源工具包
KoPL主页:
https://kopl.xlore.cn

KoPL工具包:
https://github.com/THU-KEG/KoPL

上手教程

接下来,我们在程序中加载知识库,创建可以在这个知识库上执行的引擎,调用KoPL的基本函数,就可以实现面向知识的推理问答编程。图9是一个具体的例子,实现对“布朗尼·詹姆斯和他的父亲谁更高?”这个复杂问题的推理问答,KoPL程序给出了正确的答案: 勒布朗·詹姆斯!

图 9 KoPL使用样例
结语和扩展
研发团队
指导老师
李涓子:清华大学计算机系教授,
http://keg.cs.tsinghua.edu.cn/persons/ljz/
侯磊:清华大学计算机系助理研究员,
https://www.cs.tsinghua.edu.cn/info/1113/3938.htm
开发团队
曹书林:清华大学计算机系博士生,
https://github.com/ShulinCao
史佳欣:清华大学计算机系博士生,
https://github.com/shijx12
姚子俊:清华大学计算机系硕士生,
https://github.com/TranSirius
吕鑫:清华大学计算机系博士生,
https://github.com/davidlvxin
聂麟骁:清华大学计算机系硕士生,
https://github.com/Flitternie
逄凡:清华大学计算机系工程师,
https://github.com/pf95
吴茜凤:清华大学计算机系工程师,
https://github.com/beeho
参考文献
[1] Wikidata: a free collaborative knowledgebase. Denny Vrandečić, Markus Krötzsch. Communications of the ACM 2014.
[2] Freebase: a collaboratively created graph database for structuring human knowledge. K. Bollacker, Colin Evans, Praveen K. Paritosh, TimSturge, J. Taylor. SIGMOD 2008.
[3] Dbpedia - a large-scale, multilingual knowledge base extracted from wikipedia. Jens Lehmann, Robert Isele, Max Jakob, Anja Jentzsch, D. Kontokostas, Pablo N. Mendes, Sebastian Hellmann, M. Morsey, Patrick van Kleef, S. Auer, C. Bizer. Semantic Web 2015.
[4] HOTPOTQA: A Dataset for Diverse, Explainable Multi-hop Question Answering. Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William W. Cohen, Ruslan Salakhutdinov, Christopher D. Manning. EMNLP 2018.
[5] KQA Pro: A Large-Scale Dataset with Interpretable Programs and Accurate SPARQLs for Complex Question Answering over Knowledge Base. Jiaxin Shi, Shulin Cao, Liangming Pan, Yutong Xiang, Lei Hou, Juanzi Li, Hanwang Zhang, Bin He. Arxiv 2020.
[6] Program Transfer and Ontology Awareness for Semantic Parsing in KBQA. ShulinCao, Jiaxin Shi, Zijun Yao, Lei Hou, Juanzi Li, Jinghui Xiao. Arxiv 2021.
[7] 从图灵测试到智能信息获取. 中国人工智能学会通讯第6卷第1期.