


分享嘉宾:陈河宏 阿里巴巴 算法工程师 编辑整理:李开琦 SHEIN 出品平台:DataFunTalk
**导读:**随着知识图谱技术的发展,其在电商、医疗、金融等领域得到了越来越广泛的应用。在过去的几年间,我们团队一直致力于探索知识图谱在新零售问答和直播场景的应用,提出了阿里小蜜新零售多模态知识图谱AliMe MKG(AliMe指图谱建设时期团队的名称阿里小蜜,MKG是多模态知识图谱的缩写)。本次报告将介绍过去一年多我们在多模态知识图谱方面的探索与实践工作,主要分为以下三个方面: * AliMe MKG的业务背景 * AliMe MKG的建设与应用 * 多模态知识挖掘技术探索
01
AliMe MKG的业务背景

众所周知,在电商平台上,直播带货已经是商家重要的卖货和营销手段。在淘宝直播平台上,除了少量的头部主播外,还有很多店播,也就是商家会自己开直播为自家的商品进行直播带货。但是商家自己开直播其实成本不低,例如需要招募主播、培养主播等,并且找主播相当于找代言人,如果主播发生负面事件,那么就存在店铺形象受损的风险。再者,主播也不能做到24小时直播带货。 因此,我们希望引入数字人主播来帮助商家解决以上问题,商家只要“一键开播”,就可以让我们的数字人主播为其进行直播带货。这样一方面帮助商家降低开直播的成本和风险,另一方面也可以实现24小时直播带货。这里右侧展示了我们和某美妆商家合作的数字人主播,该数字人可以自动进行商品的介绍、展示相应的商品图片和视频,这个能力主要通过我们的智能剧本系统来实现。 1. 智能剧本系统
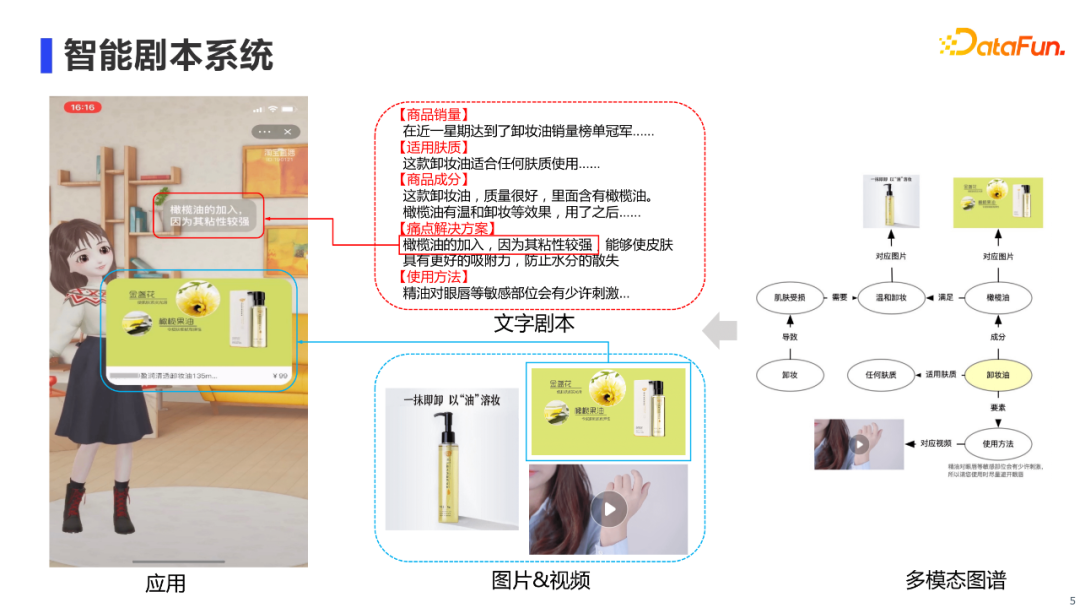
这里展示了我们的智能剧本系统,是如何支持数字人自动进行商品介绍、展示相应商品图片和视频的。最左边是数字人的直播画面,其中红框里展示的是数字人进行商品介绍的文字剧本,蓝框是看板,实时展示与剧本相关的图片和视频。中间是智能剧本系统提供给前台数字人的信息,包括文字剧本和相应的图片、视频,也就是一个多模态的剧本。而创作这个多模态剧本,需要在底层有一个多模态图谱来进行支持。这个背景促使我们去构建一个面向直播的多模态知识图谱。 2. 多模态知识图谱
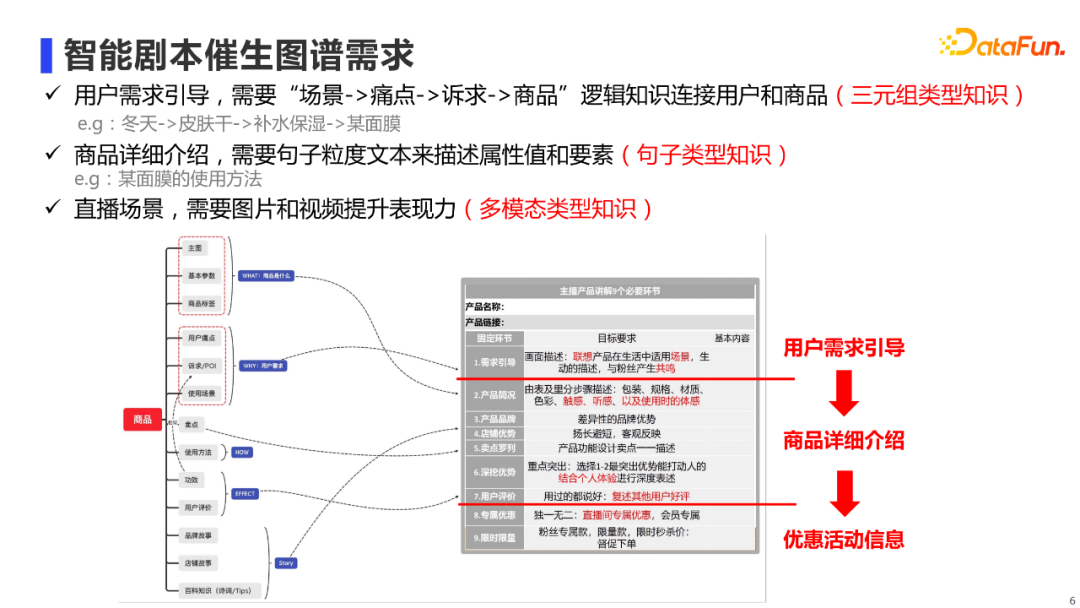
那么,直播场景下到底需要一个什么样的多模态知识图谱?我们可以先拆解一下主播是如何播报商品的。如右图所示,我们把主播讲解过程进行半结构化,可以看到,他们一般还是会遵循一定的套路。比如会先进行需求引导,也就是说用户一般在什么生活场景下,会遇到什么痛点,进而产生什么诉求,而我们的商品正好可以满足这个诉求。然后会对商品各方面进行详细介绍等。最后会提专属优惠、限时限量来引导下单。从这个流程中,我们就可以梳理出对图谱的结构化需求,如左图所示。概括来说,我们分为三大类: 第一类是三元组类型知识。主要需要“场景-痛点-诉求-商品”这样有逻辑性的知识,来对用户进行需求引导,也就是说他为什么要买这个商品。 第二类是句子类型知识。我们直播时需要对商品各方面进行详细介绍,而这种介绍需要句子粒度的信息,例如使用方法这个要素,需要有一段句子来进行介绍的。 第三类是多模态类型知识。在直播场景下,除了商品介绍,也需要有相应的商品和视频展示,从而提升数字人直播的表现力。 02
AliMe MKG的建设与应用
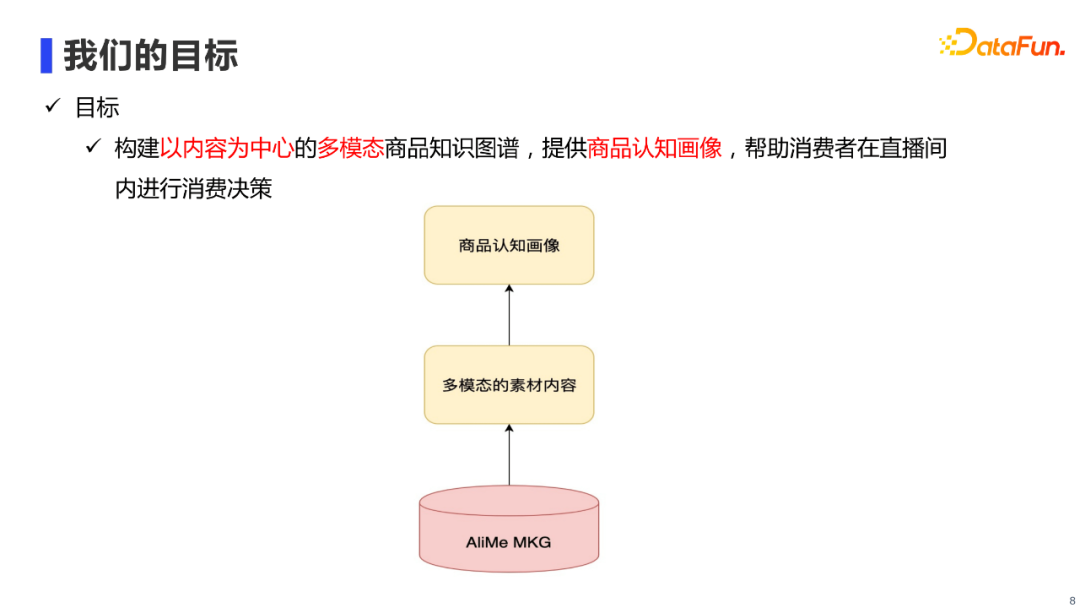
基于上文提到的业务背景,我们可以概括出AliMe MKG的建设目标:
主要是在底层建设以内容为中心的多模态商品知识图谱AliMe MKG,进而可以提供多模态的商品素材内容,最终在上层构建出一个多模态商品认知画像,帮助消费者在直播场景下进行消费决策。 1. AliMe MKG的演进过程
我们的多模态知识图谱建设并不是一蹴而就的,首先在2019年,我们在阿里店小蜜导购和问答场景下,率先建设了以三元组知识为基础的领域常识图谱;随后在2020年,团队开启了智能直播赛道,我们把知识图谱逐步扩展到包含句子知识和多模态知识的图谱。 2. AliMe MKG的主要特色
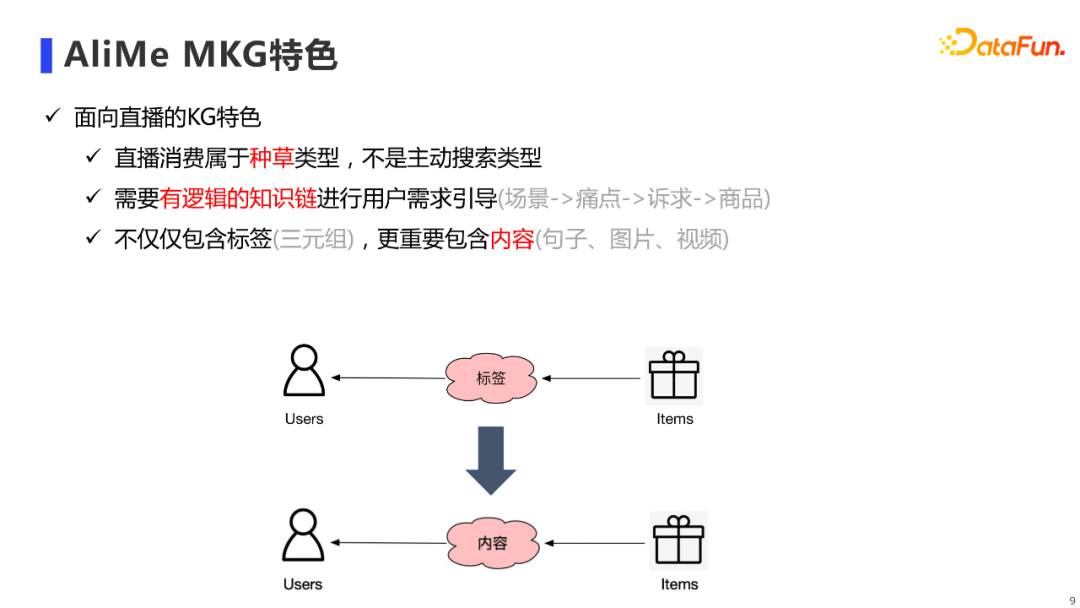
和其他知识图谱相比,AliMe MKG的特色主要可以归纳为三点: 第一是面向直播场景,其属于“种草”的场景,这要求我们能够对用户的需求进行主动引导;第二是需要构建有逻辑的知识链,来进行用户需求引导,例如阐明用户在什么生活场景下,会遇到什么痛点,进而产生什么诉求,而我们的商品正好可以满足这个诉求;最后一点是AliMe MKG不仅需要包含三元组,更需要包含内容,也就是说需要通过内容来连接用户和商品。 3. AliMe MKG的主要结构

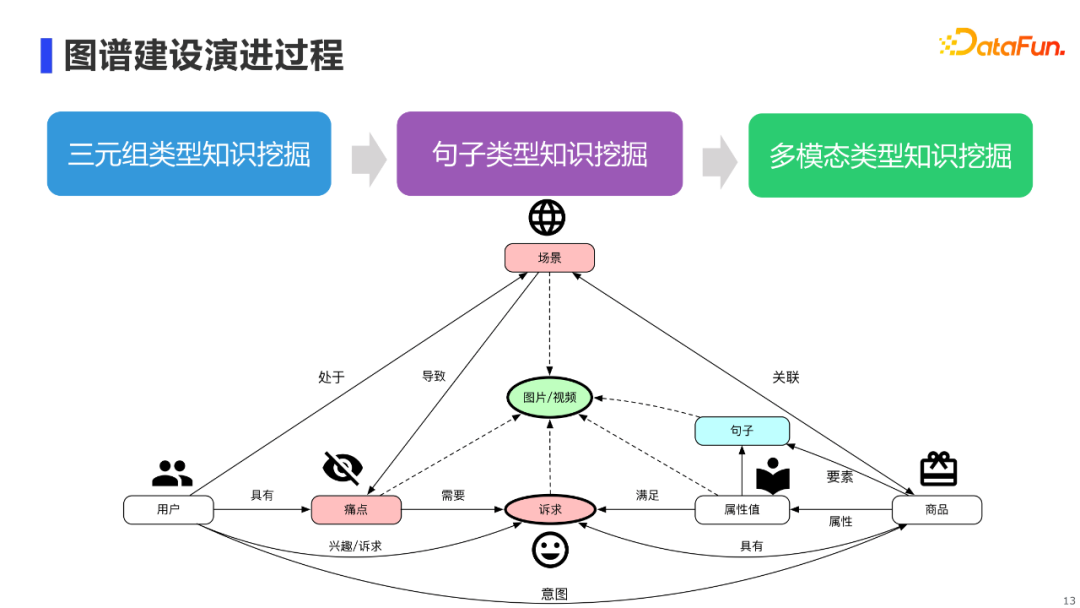
**AliMe MKG的核心结构如上图,图谱主要分为模式层和实例层。**我们在阿里商品中台提供的「用户」和带「属性值」的「商品」基础上,新增了三类节点。 首先,我们新增了「场景」、「痛点」和「诉求」节点(图中红色节点),通过构建场景化的逻辑三元组知识,将用户与商品连接了起来。拿实例层的例子来说,在冬天的场景下,用户往往会存在皮肤干的痛点,从而产生了补水保湿的诉求,某类成分为玻尿酸的面膜商品能够满足用户的诉求。 另外,我们还新增了「句子」节点(图中蓝色节点),以保存商品要素(e.g.使用方法、品牌故事)和属性值对应的句子知识。例如某面膜商品的使用方法,其对应的句子文本我们也会存储到句子节点中。 最后,我们也新增了「图片/视频」节点(图中绿色节点),通过图片/视频模态知识,对商品的属性值、用户的痛点和诉求等进行更具象化的描述。 接下来依次介绍AliMe MKG三种知识类型:三元组知识、句子知识和多模态知识具体的挖掘技术。 4. 三元组类型知识挖掘
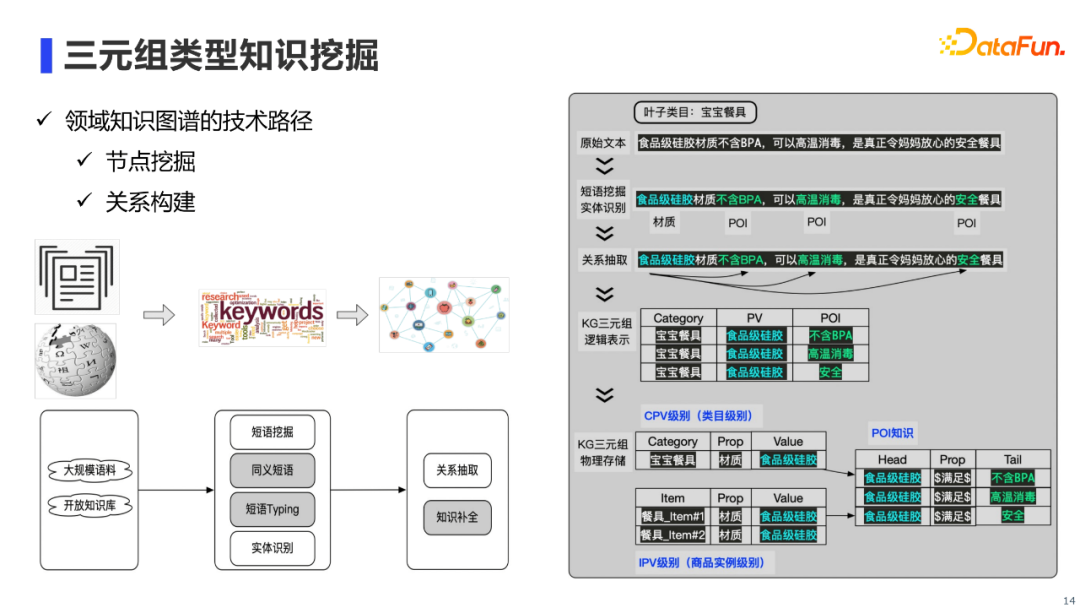
三元组类型知识的挖掘,概况起来主要是节点挖掘和关系构建技术。其中,节点挖掘主要通过短语挖掘和实体识别算法来实现,关系构建主要通过关系抽取算法来实现。
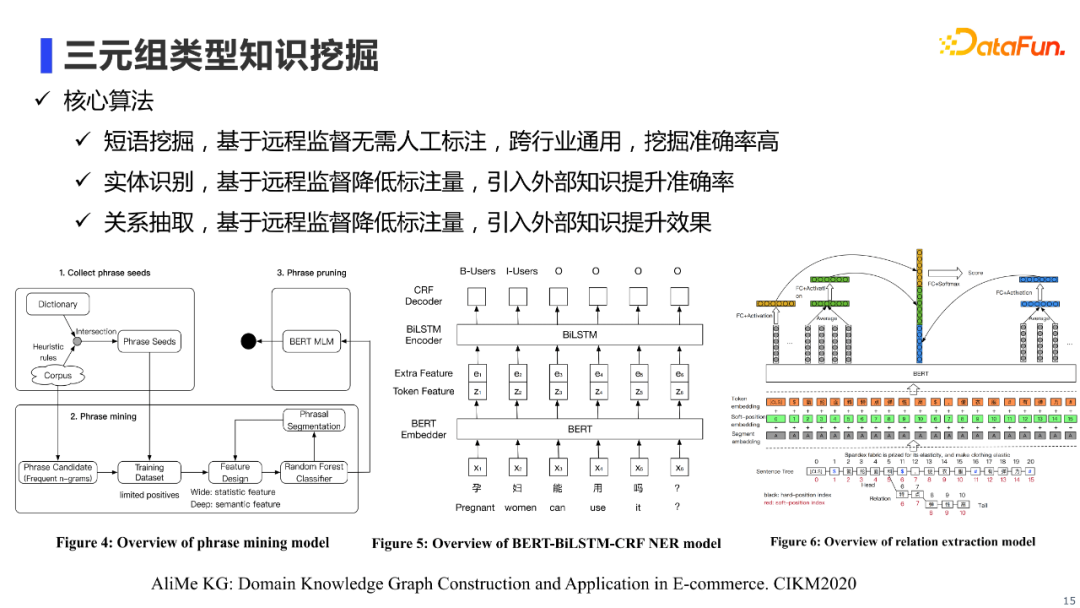
前面提到的三类算法,即三元组类型知识挖掘使用的核心算法,其主要特色是使用了远程监督方法来降低了人工标注量,同时引入外部知识提升了识别效果。具体算法细节我就不一一赘述了,感兴趣的朋友可以查阅我们的论文。 5. 句子类型知识挖掘
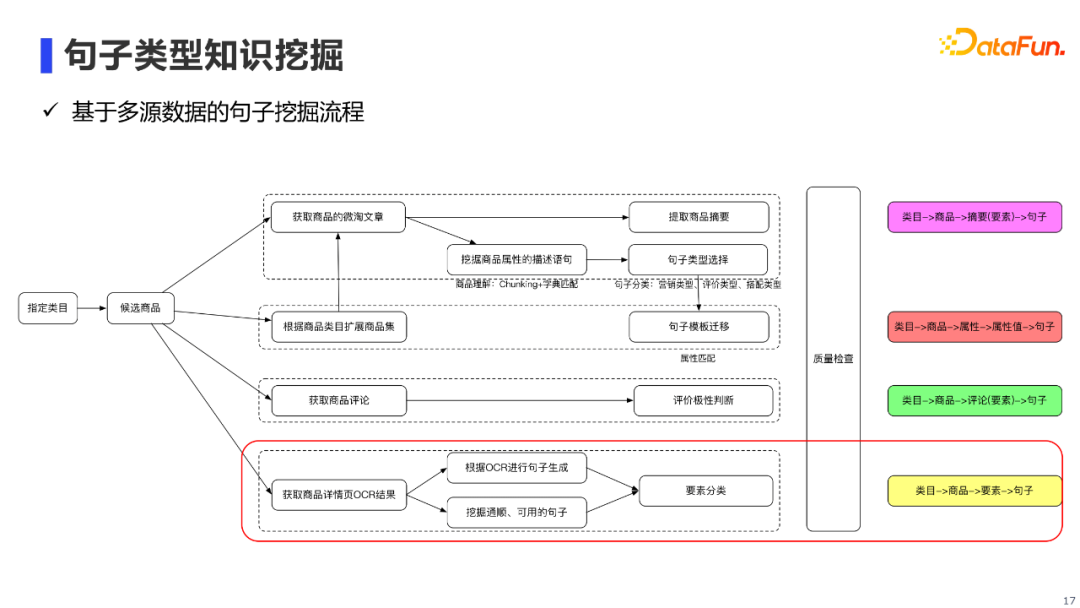
句子类型知识的挖掘还是比较复杂的,它需要从不同数据源中进行句子挖掘,以保证挖掘到的句子具有多样性。具体来说,我们主要会从三类数据源中进行句子挖掘: 第一类是阿里内部的商品微淘文章:我们一方面使用摘要算法,提取文章中描述的商品摘要;另一方面,我们也会针对文章中的句子,构建pipeline提取出能够描述商品属性的句子。 第二类是商品评论:我们主要使用极性分类器,提取商品的好评句子。 **第三类是商品详情页:**这里我详细展开说一下商品详情页的挖掘流程。
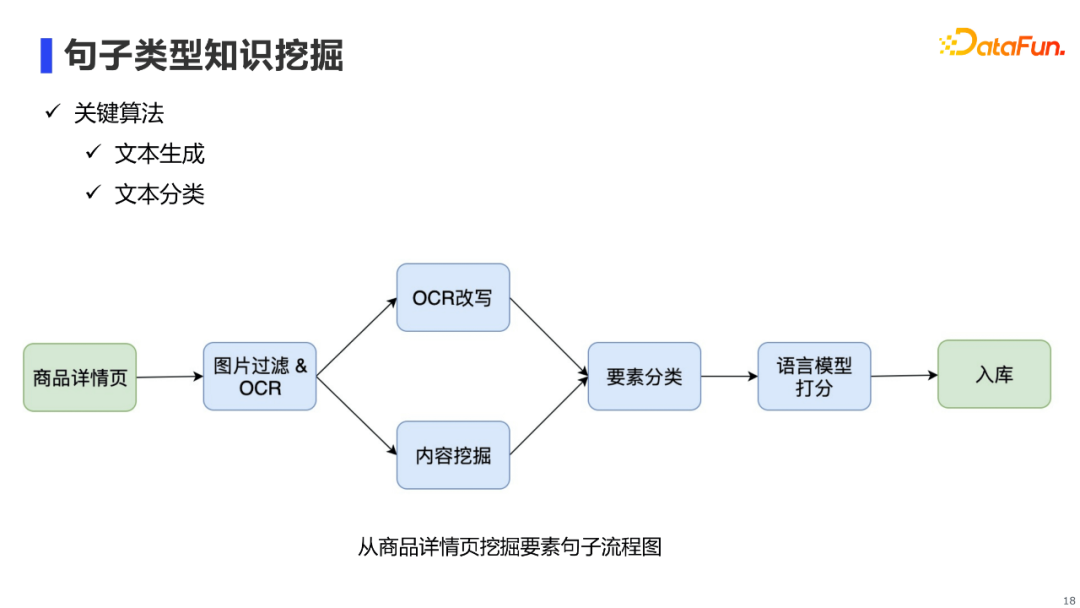
商品详情页的句子挖掘主要用到文本生成和文本分类算法。
首先,基于商品详情页(图片),我们利用OCR识别技术得到图片的OCR文本;然后,针对小段OCR文本,我们会通过文本改写模型进行OCR改写从而使句子保持连贯;针对大段OCR文本,我们通过内容挖掘pipeline,挖掘出连贯的句子。接着,通过要素分类器将句子进行归类,例如有的句子是「使用方法」,有的是「品牌故事」或描述商品某成分的「属性句子」。最后,通过语言模型对句子进行打分,从而过滤掉通顺流畅有问题的句子。 6. 多模态类型知识挖掘
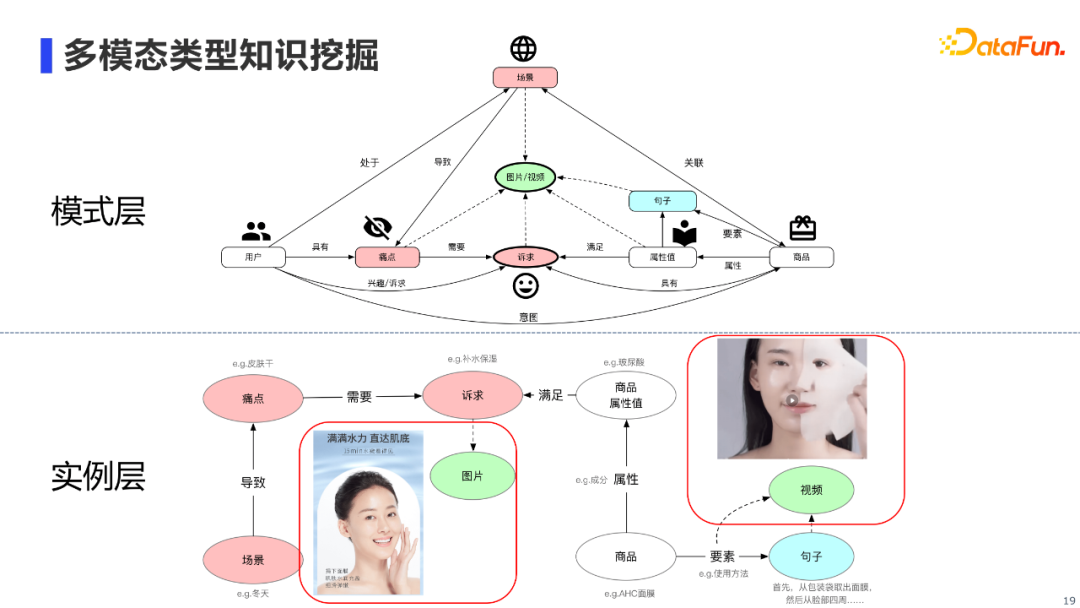
多模态知识挖掘,主要指实例层中红框标注的图片知识和视频知识挖掘。其中图片挖掘的数据源主要来自商品详情图,视频挖掘的数据源主要来自淘宝真人直播的视频片段。核心算法主要包括图文匹配技术及Video Grounding技术。
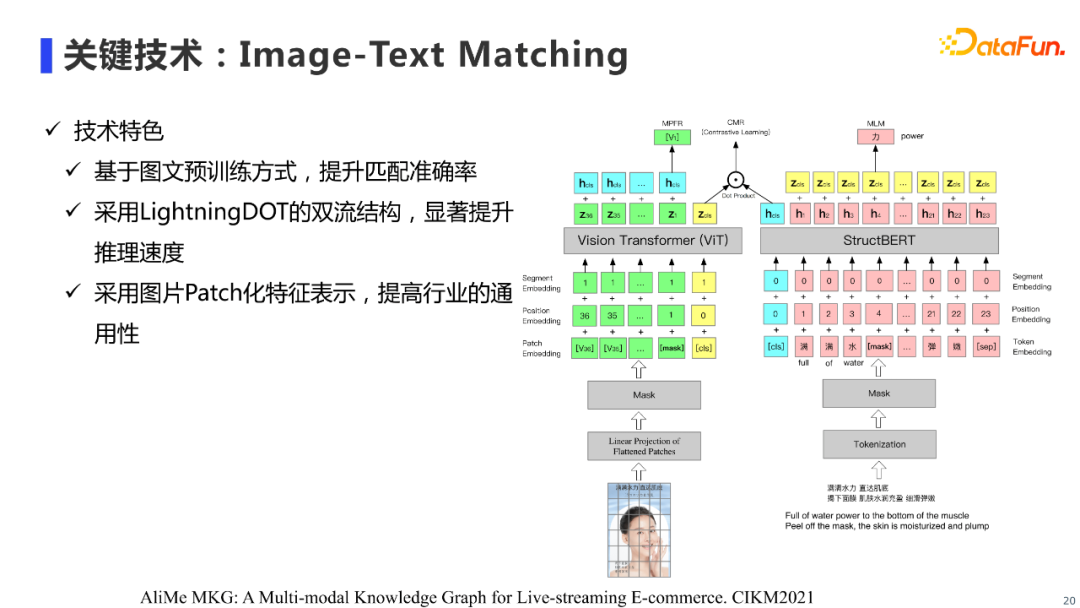
图片挖掘目前使用的是Image-Text Matching技术,图文匹配技术目前是多模态领域比较火热的一个任务,这里介绍我们去年探索的图文匹配模型。我们的模型结构是一个双流图文匹配结构,包括图片流和文本流,其中图片流使用Vit(Vision Transformer)进行图片编码,文本流使用阿里的StructBERT来进行文本编码。相对于单流结构,双流结构可以提供更快的推理速度。与此同时,我们使用图文预训练来提升图文匹配的效果。具体来说,我们的图文预训练任务包括三个任务: * 图文匹配对比学习任务(Contrastive Learning, CMR) * 图片特征回归任务(Masked Region Feature Regression, MRFR) * 文本MLM任务(Masked Language Model, MLM)
为了更好学习图文交互能力,参考LightningDOT模型,文本流和图片流编码器的最后一层会叠加其他模态编码器的[cls]位向量,再进行CMR和MRFR预训练任务。 模型输入主要分为文本输入和图片输入,对于文本输入的处理,学界和工业界都比较统一,和Bert的处理方式基本一致。而对于图片输入的处理,学术界也进行了较多的研究,概况来说主要有三种: * 使用目标检测器检测图片的区域,进而编码得到图片区域的特征(region feature)。 * 使用ResNet,直接提取图片的空间维度特征(grid feature)。 * 对图片进行patch分块,进而编码得到图片每个patch的特征(patch feature)。
具体在我们的任务中,我们发现使用图片patch特征,在模型性能和推理速度上都能取得较好效果,并且这种处理方式不依赖于额外的目标检测器,因此在行业通用性方面较其他方法也表现得更好。
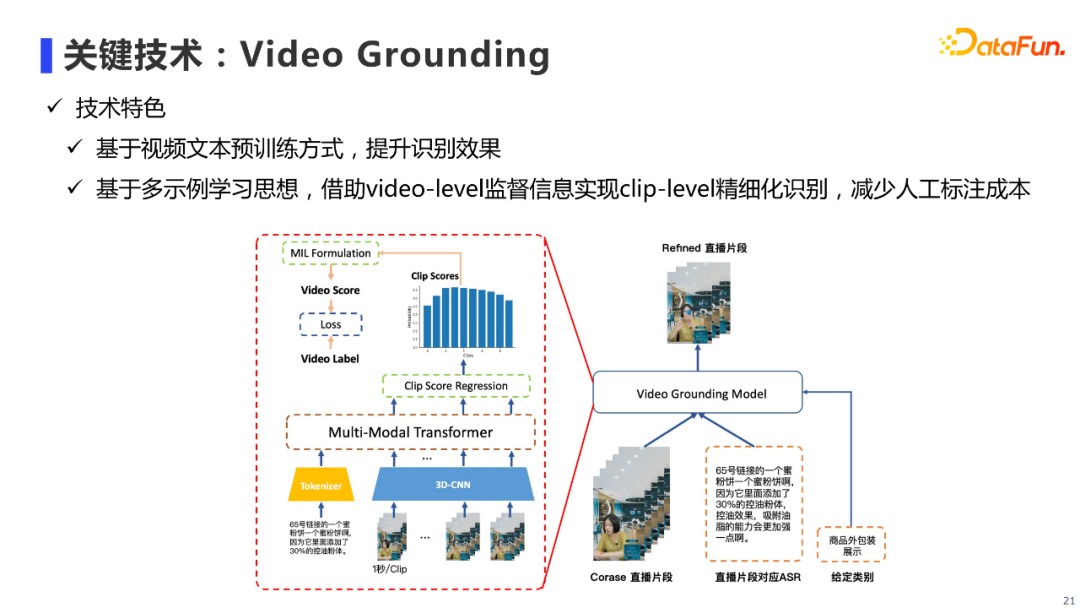
视频挖掘技术的核心算法是Video Grounding,指的是给定一个长视频片段及标签(e.g. 商品包装),从视频片段中提取出与标签有关的子片段,也就是需要进行clip级别的预测。我们使用真人直播片段及其对应的ASR文本,构成「视频-文本」对进行多模态预训练,来提升Video Grounding的效果。 具体来说,我们将直播片段分成以1秒为单位的若干个clip,并通过预训练过的3DCNN进行每个Clip的特征抽取,得到若干个视频clip的特征向量,然后和对应的ASR文本特征序列拼接起来,一同输入到单流Transformer中,进行多模态预训练。 在下游做Video Grounding任务时,我们会输入视频clip和ASR文本到经过预训练的Multi-Modal Transformer中进行多模态的特征交互,从而得到多模融合之后的视频clip序列特征,接着对这些特征回归出每个clip是否包含给定标签的概率。推理时,我们利用这些clip的概率进行视频片段的筛选。训练时,由于需要进行clip级别的预测,常规的做法需要对训练数据中视频的每一帧进行标注,人工标注成本是很大的。我们注意到对于视频片段中的每个clip,可以将其视为对应视频片段的一个Instance(示例),这样我们可以将Video Grounding任务转化为一个多示例学习(Multiple Instance Learning,MIL)问题。具体做法是对于每一个标签,我们可以将该标签所标记的全部视频作为正样本(Positive Bag),其他标签标记的视频作为负样本(Negative Bag)。然后将每个视频所有clip的概率,聚合成为该视频片段是否含有对应标签的概率,使用BCE损失函数指导模型学习。这样就通过视频级别的标签,学习到clip级别的信息,减少了人工标注成本。
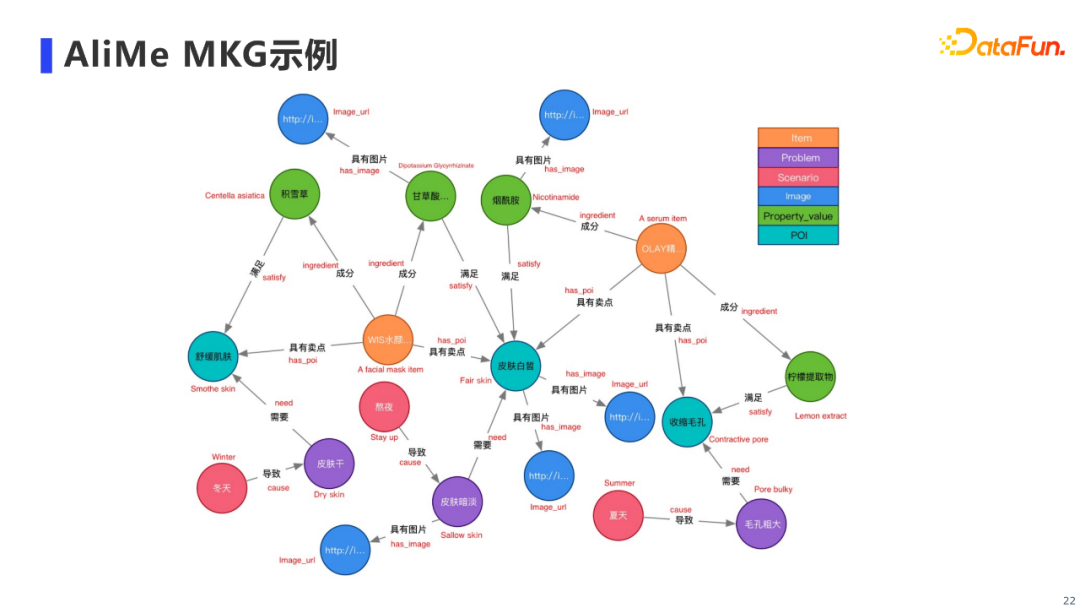

通过前面所述的方法,我们最终可以构建得到商品的多模态知识图谱,进而得到多模态的商品认知画像,包括了商品属性、与属性相对应的句子文本及图片和视频等知识。 7. AliMe MKG的应用

AliMe MKG在直播场景下主要有两类落地场景: * 数字人主播:即业务背景部分提到的「商品剧本播报」场景。 * 直播间智能小助理:我们在直播间也开发了一个智能小助理产品,AliMe MKG会在其中的「商品内容推荐」场景进行应用。
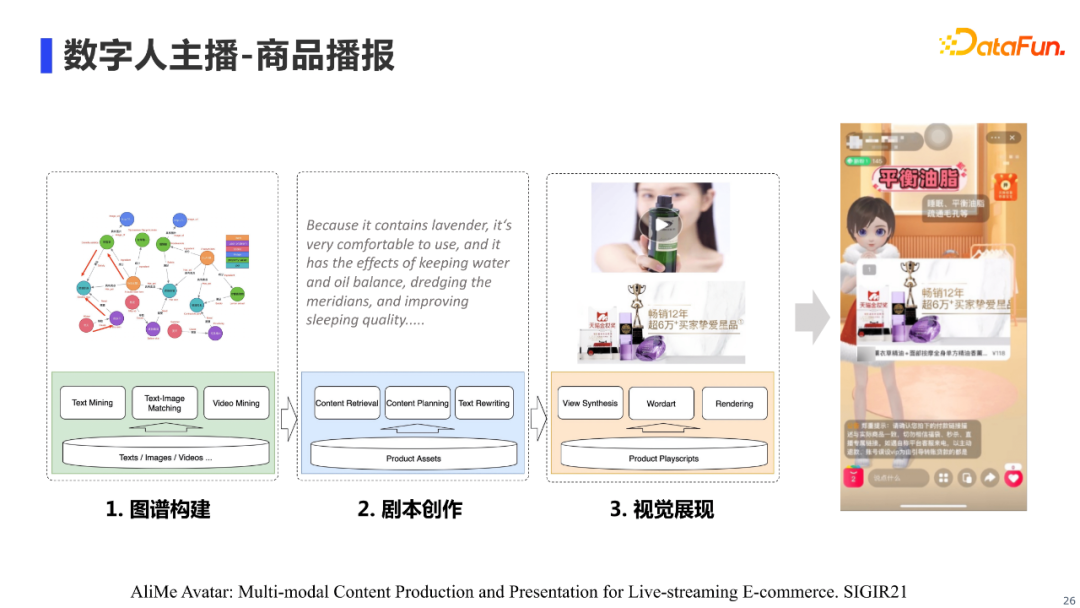
这里展示了AliMe MKG在数字人主播「商品播报」场景下应用的流程,本文主要focus在第一点图谱构建的工作上,第二点「剧本创作」和第三点「视觉展示」就不过多介绍了,感兴趣的朋友可以查阅我们团队在SIGIR和CIKM上发表的相关论文。

对于商品内容推荐的落地场景,我们主要考虑在直播间中,主播和听众之间是1vN的关系,即同一个主播在同一个时段内面对不同用户只能讲解同一种内容。然而,对于同一个时间段进入直播间的用户,他们的诉求可能是不尽相同,有人希望了解商品的用料材质,有人希望了解商品的使用方法。 因此,基于不同的用户画像,我们会为其推荐多模态图谱中不同的商品多模态内容,从而更好满足不同用户的诉求。 03
多模态知识挖掘技术探索
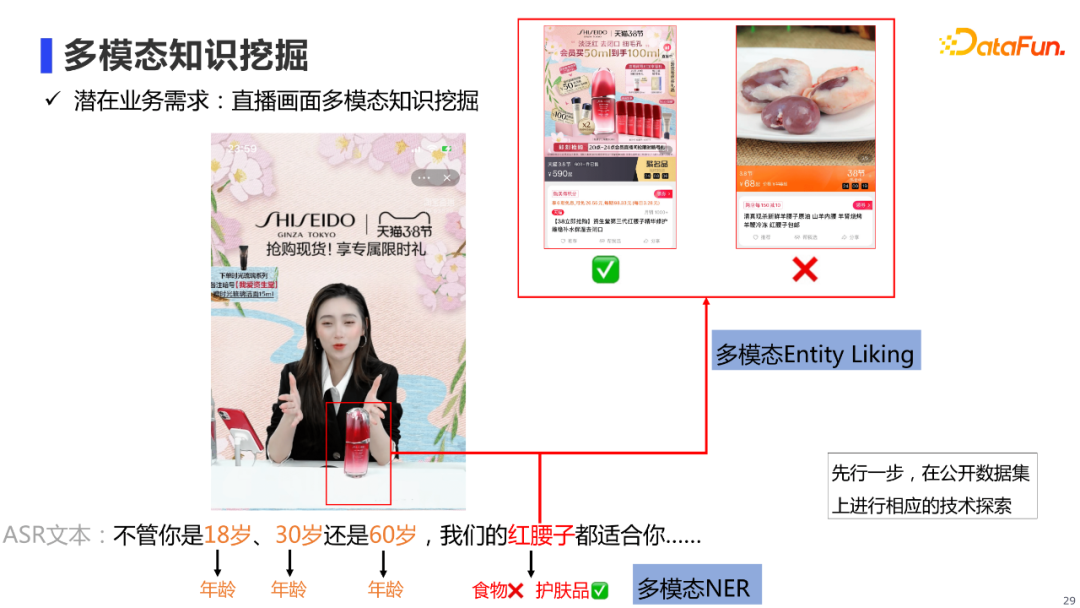
目前我们的多模知识图谱,主要从微淘文章、商品详情页、商品评论中进行知识挖掘,真人直播视频也只挖掘了比较粗粒度的视频片段。但其实真人直播的ASR文本中,也包含了很多有用的商品知识,可供我们进行知识挖掘,以扩充图谱的规模。例如,下面这段ASR文本,可以挖掘出商品的适用年龄和商品类别,一般这类知识,我们需要先进行NER,但是我们发现仅依靠文本的上下文,有时候会把红腰子的实体类型误分为食物而不是护肤品,而如果我们结合当前文本的直播画面,还是比较容易知道他指的是护肤品的,这里我们可以将其形式化成多模态NER任务。 同样,如果将红腰子这个实体链接到某个商品时,有时候也会有链指错误的问题,但是如果借助图片的话,我们也能很好地链接到左边这个商品,这里我们可以将其形式化为多模态Entity Linking的任务。针对这两类任务,我们目前也先行一步,在公开数据集上进行了相应的技术探索,下面我会分别针对这两个任务,介绍我们近期的工作。 1. 多模态NER
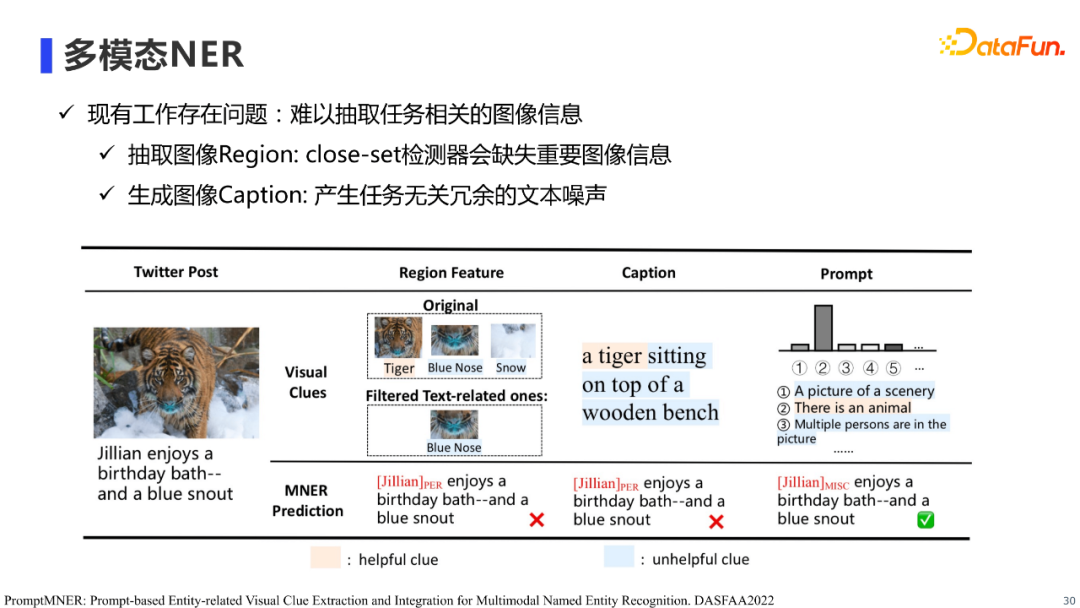
首先是多模态NER的工作,多模态NER主要指利用图片信息,增强文本NER的效果。这个任务的重点在于如何抽取有效的图片信息,以及如何将图片信息有效的融合到NER模型中。 现有工作主要使用两类方法进行图像信息抽取,第一类是使用目标检测器提取图片的Region特征并将其融入到文本中进行实体识别,这类方法的局限性在于受目标检测器标签有限性的影响,提取过程中可能会丢失重要的图片信息;第二类是生成图片Caption并将其融入到文本中进行实体识别,这类方法的局限性在于生成图片Caption过程中,会较易产生与任务无关的冗余的文本噪声。概况来说,现有方法并不能有效的提取图片信息。
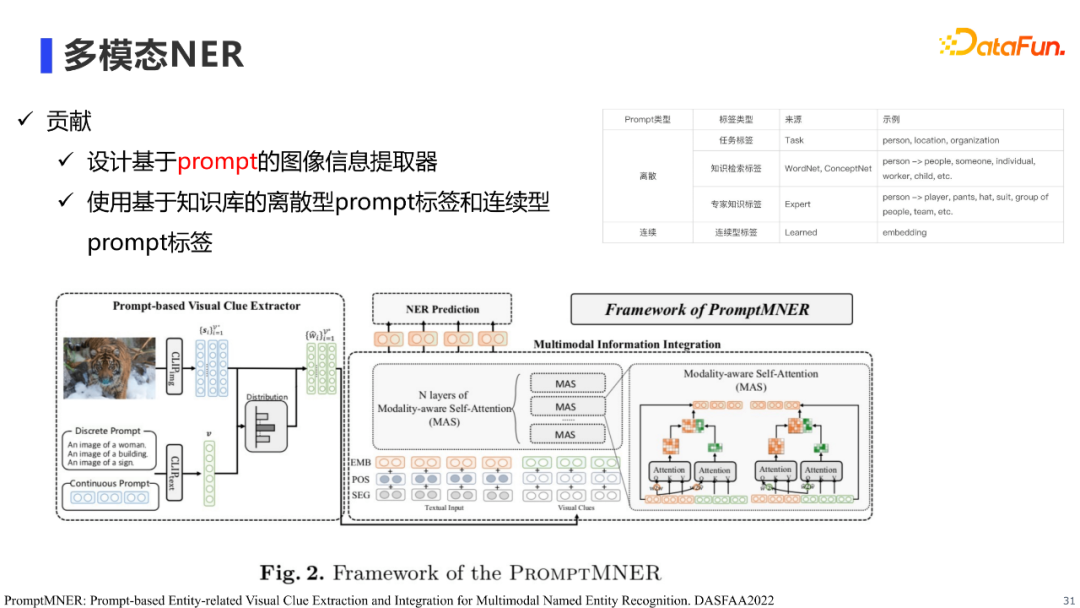
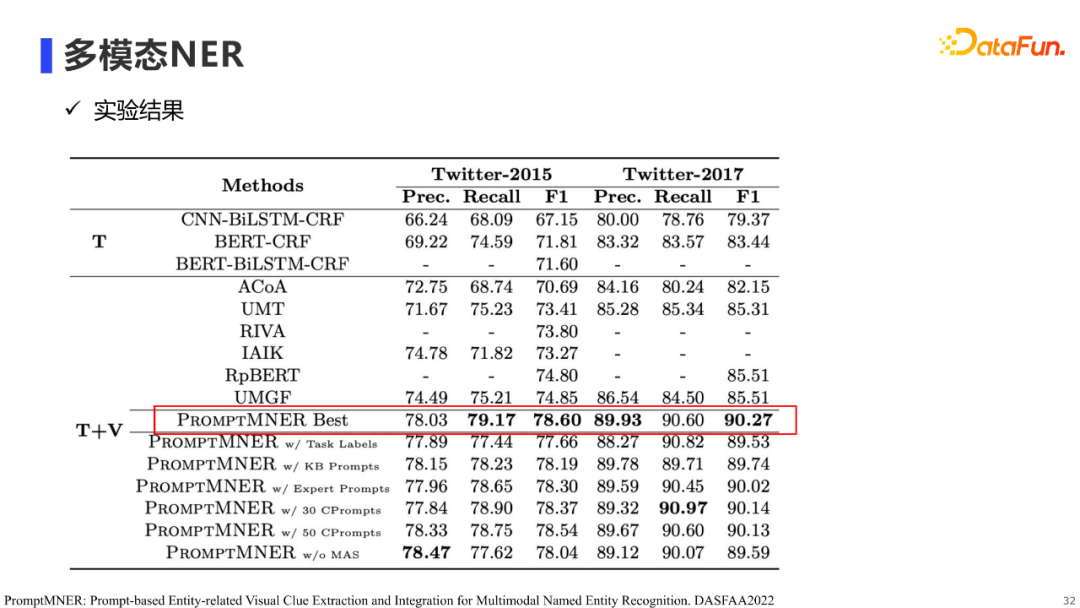
为了解决现有方法无法有效提取图片信息的问题,我们提出使用prompt进行图像信息提取,从而提升多模态NER的效果。 具体来说,我们首先借助知识库(e.g. WordNet, ConceptNet)半自动的构建和任务实体类型相关的图片object标签,以作为我们的prompt标签(e.g. woman, animal, building),然后构建prompt文本(e.g. An image of animal)输入到预训练的clip中,使用clip判断标签在图像中出现的程度,通过这种方法抽取NER任务相关的图像信息。在prompt标签的设计上,除了离散型prompt,我们也使用了连续型prompt标签。实验结果表明,我们的方法在公开数据集上达到了SOTA的效果。
2. 多模态Entity Linking

多模态Entity Linking是我们和复旦大学知识工场合作的一个工作,针对学界现有数据集存在的话题、实体类型及歧义现象较有限的情况,我们构建并开源了一个多样化的Entity Linking数据集,希望该数据集能有助于促进学界和工业界对Entity Linking工作的研究。
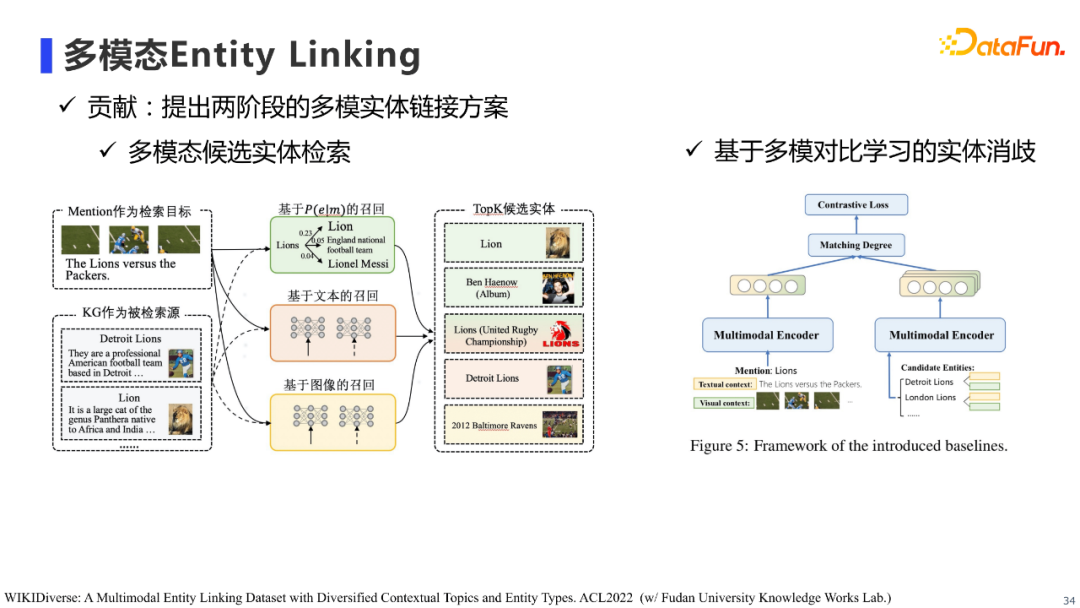
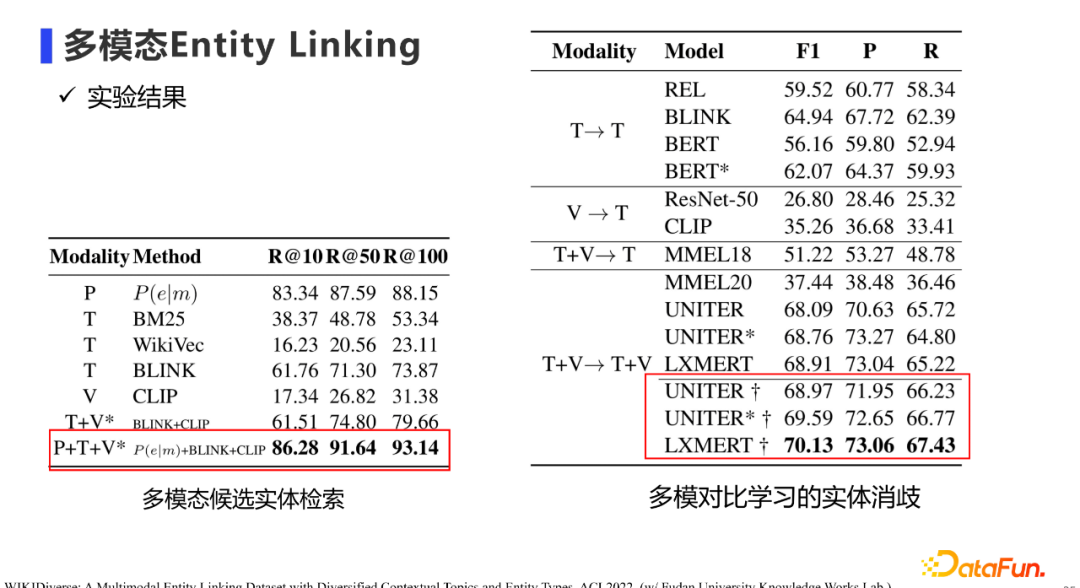
基于该数据集,我们提出两阶段的多模态实体链接方案: * 第一阶段是多模态候选实体检索:使用不同模态的多路召回进行实体检索,最终得到候选实体集。 * 第二阶段是基于多模态对比学习的实体消歧:使用多模态双塔模型,分别对待检索的Mention和候选实体进行编码,然后基于对比学习进行实体消歧的训练。
该方法在我们的公开数据集上,也取得不错的效果。
04
问答环节
Q:数字人有量化的业务指标吗?在业务上如何衡量剧本的有效性?
A:当前业务指标是相对于真人主播,数字人主播的成交转化率及转粉率。业务如何衡量剧本的有效性主要通过线上AB测试,观察不同版本剧本线上业务指标的变化来衡量其有效性。 Q:剧本上线前是否有人工审核环节?如何评价?
A:有人工审核的,这个审核主要是店家在审核。在实际应用时,店家开播前可以一键选择待播报的商品,选择后,我们的剧本系统会为每个商品自动生成剧本,然后我们也会提供后台界面,让店家可以检查剧本,如果觉得剧本哪部分不合适,自己便可以做相应的修改。 Q:如果商家对剧本做出修改,模型会因此进行更新或迭代吗?
A:会的。我们会将剧本分成不同的Schema,例如需求引导、产品概况、卖点罗列等,然后会从商家线上修改的行为中了解到哪部分需要重点优化,进而指导剧本优化的方向。 Q:除了业务指标外,剧本的技术指标是什么?
A:最开始做的时候是有离线技术指标的,主要通过人工对剧本进行三个方面的评测:一是剧本可靠性,剧本内的文本表述是否正确,比如说某商品成分是橄榄油,但如果剧本说的成分是薄荷油,那剧本可靠性的打分会变低;其次是剧本的多样性,主要集中在剧本文本表述的多样性;最后是生动性指标,主要指剧本在播报时相应可展示多少种图片及视频,让直播间展示的内容更加生动。但考虑离线评测的人力成本,并且我们在经过前期优化后,剧本质量也已经比较高了,所以目前主要看线上指标。 Q:我们的多模态图谱更新频率如何?在具体业务场景比如推荐场景下的使用是如何衡量图谱价值的?
A:模式层常识类的知识前期是按月更新,目前已经积累了一定的量级,能较好满足业务需求了,所以主要根据具体需求不定时的更新,实例层商品类的知识是每日更新的。在具体业务场景例如推荐场景下,主要看业务在使用图谱数据后,推荐的成交转化率是否能够得到提升,进而衡量图谱的价值。 今天的分享就到这里,谢谢大家。
