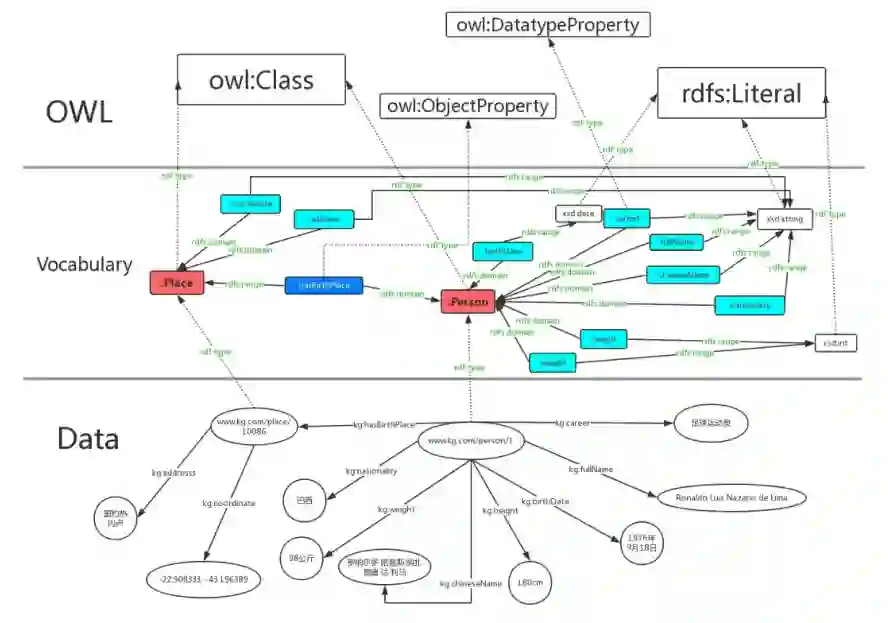
基于知识图谱的行业问答系统搭建分几步?
构建过程主要分为:知识体系搭建、知识抽取、知识融合、知识储存和检索、知识推理、知识问答等六步。
第一步:知识体系构建
采用什么样的方式表达知识,其核心是构建一个本体对目标知识进行描述:
在这个本体中需要定义出知识的类别体系;
每个类别下所属的概念和实体;
某类概念和实体所具有的属性以及概念之间、实体之间的语义关系;
-
同时也包括定义在这个本体上的一些推理规则。
第二步:知识获取
知识获取可分为结构化和半结构化数据源中的知识抽取和非结构化文本中实体的知识抽取 。
-
结构化和半结构化数据源中的知识抽取:因为数据噪声少,这类数据源的信息抽取方法相对简单,经过人工过滤后能够得到高质量的结构化三元组。这是目前工业界常用的技术手段。
-
非结构化文本中实体的知识抽取:因为涉及到自然语言分析和处理技术,难度较大。但是互联网上更多的信息都是以非结构化文本的形式存在,而非结构化文本的信息抽取能够为知识图谱提供大量高质量的三元组事实,因此是构建知识图谱的核心技术。这目前也是学术研究的重点
-
基于传统逻辑规则的方法进行推理:研究热点在于如何自动学习推理规则,以及如何解决推理过程中的规则冲突问题; -
基于表示学习的推理:采用学习的方式,将传统推理过程转化为基于分布式表示的语义向量相似度计算任务。这类方法优点是容错率高、可学习,缺点也显而易见,即不可解释,缺乏语义约束。


深蓝学院倾心打磨了《知识图谱理论与实践》课程,由于受疫情影响,我们基于以往6期的知识图谱线下课程,迭代精品线上课程。本课程将理论基础与实践相结合,让你实现基本知识图谱的问答系统~



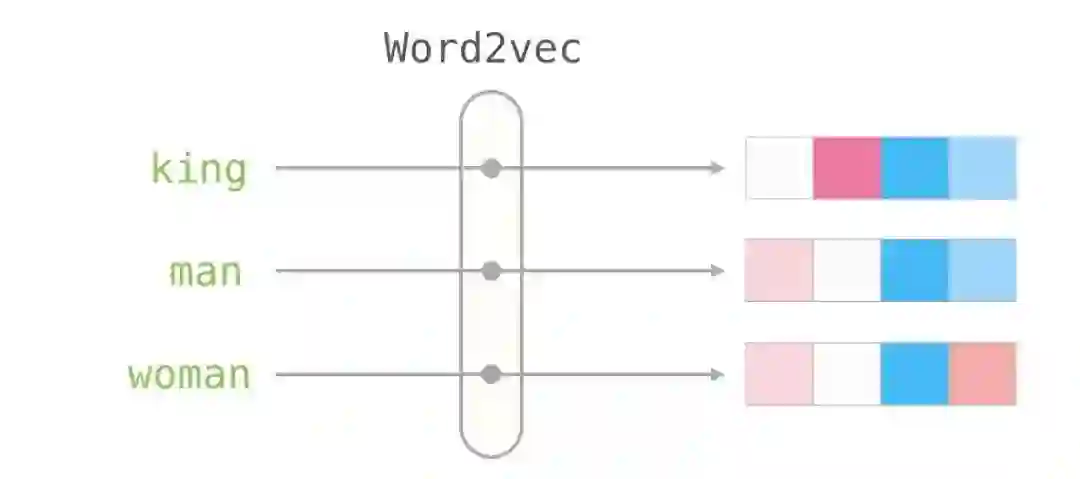
词向量表示模型
学习如何实现Word2Vec词向量表示,使用以及训练自己的Word2Vec模型,了解 Fine - turning 过程以及 hierarchical softmax 和 negative sampling 的优化策略。
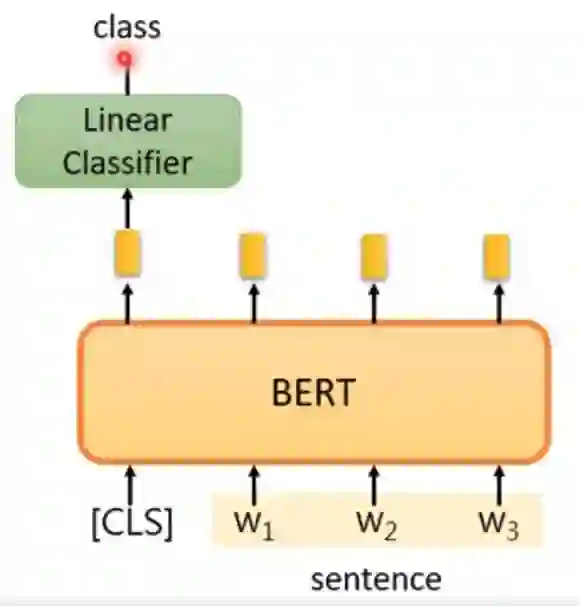
基于 Bert 的文本分类
首先详细介绍 Bert 代码中的 BertEmbeddings 类、 BertEncoder 类和 BertPooler 类这3个模块的实现,然后讲解如何将 Bert 用于构建文本分类器,并以 CoLA 标准数据集为例,用 Bert 实现判断给定句子是否语法正确的任务,最后给出对于不同数据集,如何在不改变代码框架基础上,实现不同的数据预处理。
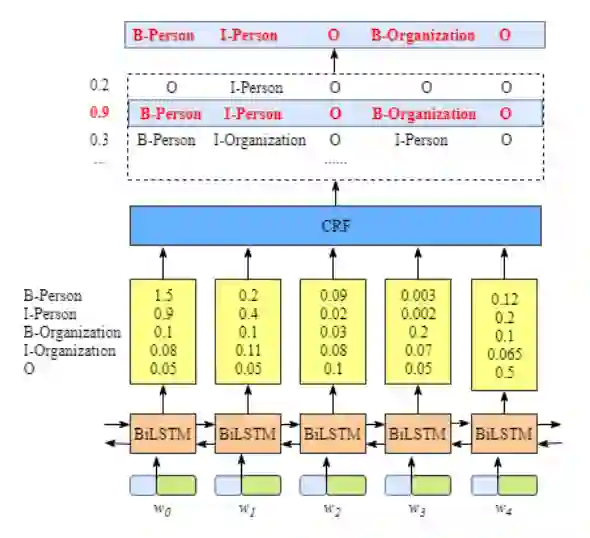
基于 LSTM + CRF 的命名实体识别
学习如何使用 PyTorch 实现 LSTM + CRF 序列标注模型,完成快递信息抽取任务的命名实体识别,在基本模型的基础上,完成 BiLSTM + CRF 模型。在实践过程中,大家可以对比 CRF 模型与 BiLSTM + CRF 模型在命名实体识别任务的表现。
基于 CNN 与 multi - head selection 的实体关系抽取
利用 CNN 表示句子级特征,进而进行实体关系的分类,对比位置向量对模型提升的效果;进一步讲解基于 multi - head selection 的关系分类,及其在语言与智能技术竞赛中数据集上的 Pytorch 实现。

D2RQ关系数据库转 RDF
首先讲解将关系型数据转成 RDF 的多种方式,比如直接映射、R2RML映射、D2RQ映射,然后重点讲解D2RQ如何将关系型数据库当作虚拟的 RDF 图数据库进行访问的。
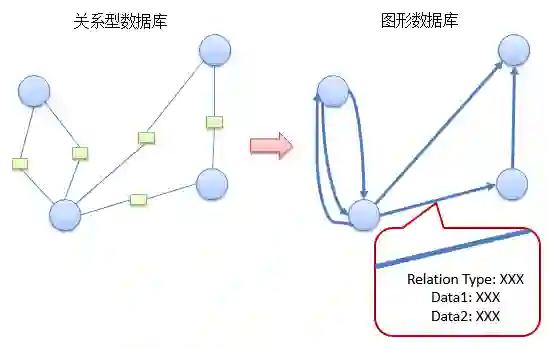
图数据库 Jena
介绍图数据库 Jena 的基本使用方法,学习知识图谱本体构建,掌握如何将关系数据库( MySQL )中的表转换成图数据库中的 RDF 三元组。
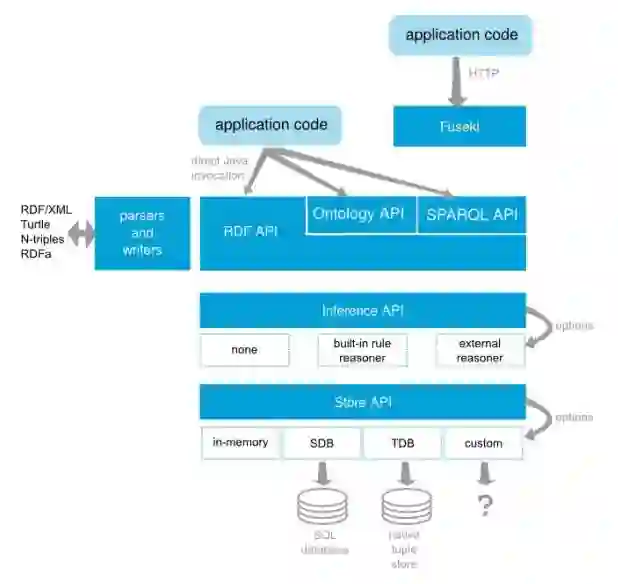
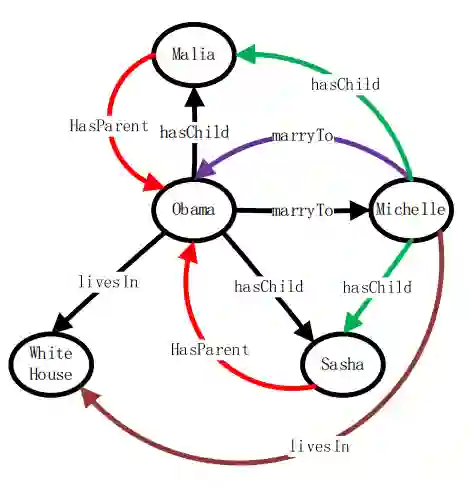
基于规则的推理
基于 Jena 数据库,讲解规则的语法以及规则文件的配置,最后通过 SPARQL 查询,查询数据库中的喜剧演员名单。
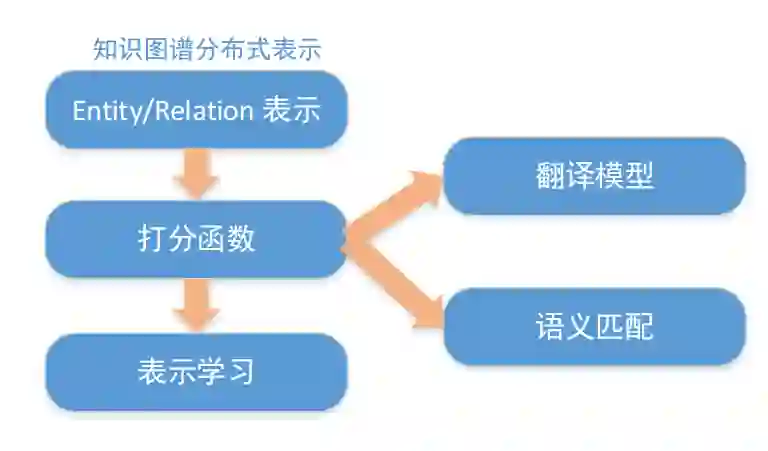
基于分布式表示的推理
学习如何实现知识图谱分布式表示模型 TransE ,讲解 TransE 的关键模型的代码实现。

基于知识图谱的医药领域的问答系统
熟悉知识图谱应用的开发流程。对于医药领域的问答系统,将教给大家从数据爬虫开始,通过本体构建、RDF生成、问句解析、 SPARQL查询以及答案生成等步骤搭建完成的问答系统。

扫码添加深蓝学院-子书
备注【图谱】,快速通过好友哦!





