

《近期大推理模型(如DeepSeek-R1与OpenAI o1)通过扩大推理过程中的思维链(CoT)长度,显著提升了性能表现。然而,这些模型倾向于生成过长的推理轨迹,其中常包含冗余内容(如重复定义)、对简单问题的过度分析,以及对复杂任务推理路径的浅层探索。这种低效性为训练、推理及实际部署(如基于代理的系统)带来了严峻挑战,尤其在token经济性至关重要的场景中。
本综述系统梳理了当前提升大推理模型效率的研究进展,重点关注这一新范式下的独特挑战。我们总结了低效性的常见模式,分析了从预训练到推理全生命周期中提出的优化方法,并探讨了未来潜在的研究方向。为支持领域发展,我们同步维护了一个实时GitHub仓库,追踪最新研究成果。希望本文能为后续探索奠定基础,并激发这一快速发展领域的创新。
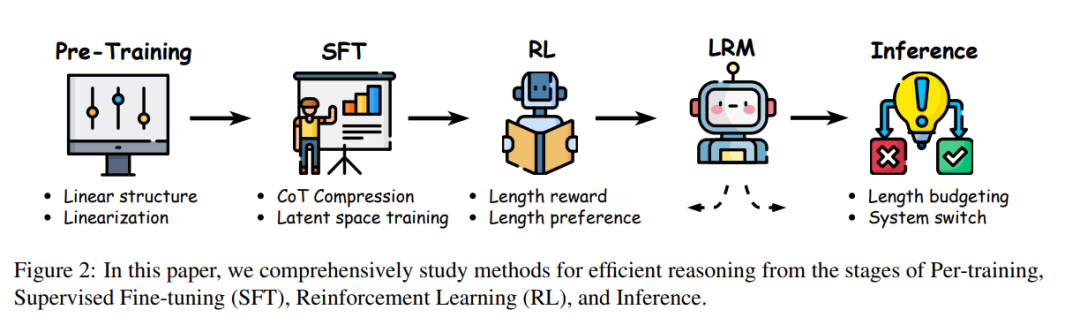
**
**
**1 引言
“简洁是智慧的灵魂。”
——威廉·莎士比亚 大型语言模型(LLMs),如 DeepSeek V3(Liu et al., 2024a)、Qwen 2.5(Yang et al., 2024a)、LLaMA 3(Dubey et al., 2024)和 GPT-4o(Hurst et al., 2024),已在广泛任务中展现出卓越能力(Chang et al., 2024; Zhao et al., 2023; Kasneci et al., 2023; Zhu et al., 2024)。这些模型的运作方式类似于 系统1思维(Frankish, 2010; Kahneman, 2011; Li et al., 2025e),即快速、直觉化、自动化的决策过程。然而,复杂推理任务(如高等数学(Lightman et al., 2023; Besta et al., 2024; Ahn et al., 2024)和形式逻辑(Huang and Chang, 2022; Pan et al., 2023))需要更审慎、结构化的分析。 为应对这些挑战,一类新型模型应运而生——大型推理模型(LRMs),包括 DeepSeek R1(Guo et al., 2025)、OpenAI-o1/o3(Jaech et al., 2024)和 QwQ(Team, 2024)。这些模型通过显式生成中间推理步骤(即 思维链(CoT)(Wei et al., 2022))来提升性能,最终得出答案。与LLMs的快速启发式推理不同,LRMs展现出类似 系统2思维(Evans, 2003; Kannengiesser and Gero, 2019)的审慎分析能力。 然而,这一能力伴随代价:LRMs的推理过程往往更慢、更冗长。如图1所示,对于一道小学数学题,QwQ-32B 生成的 token 数量远超 Qwen2.5-32B-Instruct(基于系统1的模型)。此外,统计分布显示,LRM模型 QwQ-32B 的输出长度显著大于LLM模型 Qwen2.5-32B-Instruct。这一现象自然引出一个关键问题: 除了推理性能,我们如何让LRMs的推理更高效,从而最大化每个token的智能?
在LRM时代,我们主张 “效率是智能的精髓”。正如智者懂得何时停止思考、做出决策,一个聪明的模型也应知道何时终止不必要的推演。智能模型应优化 token经济——即有目的地分配token、跳过冗余、优化求解路径。它不应机械遍历所有可能的推理路径,而应像战略大师一样,以精准的平衡兼顾成本与性能。
**1.1 综述结构
本综述系统梳理了LRMs高效推理的最新进展,并按LLM生命周期阶段分类(图2)。图3展示了本文涵盖的高效推理方法分类体系。全文结构如下: 1. 第2节 探讨LRM时代推理低效的模式与挑战。 1. 第3节 介绍推理阶段的高效推理方法。 1. 第4节 阐述通过监督微调(SFT)内化简洁推理的技术。 1. 第5节 分析强化学习(RL)中控制推理长度的策略。 1. 第6节 讨论模型架构与训练范式的固有高效性。 1. 第7节 展望各阶段待突破的未来方向。
**1.2 定位与贡献
近期多项综述研究了大型推理模型的发展。Besta et al.(2025)和Zeng et al.(2024a)聚焦LRM训练方法,而Li et al.(2025e)提供了更全面的领域概览。为聚焦深层问题,Chen et al.(2025b)研究了长思维链推理并归类现有范式;Ji et al.(2025)则探索了LRM的测试时扩展。然而,现有研究均未专门讨论LRMs推理效率这一关键挑战——它直接影响模型部署、扩展与实际应用。 对于早期LLMs,Zhou et al.(2024)综述了高效推理方法。但LRMs的高效推理是一个新兴且独特的研究挑战,其核心在于冗长且不可控的推理token生成。传统加速推理方法(如模型量化与剪枝(Polino et al., 2018; Xiao et al., 2023a; Xia et al., 2023; Wang et al., 2019; Ma et al., 2023; Cheng et al., 2024)及分布式推理系统(Patel et al., 2024; Hu et al., 2024a; Zhong et al., 2024; Lin et al., 2024a))虽能降低延迟与计算成本,但本文聚焦于推理过程本身的效率优化,而非通用推理加速。 综上,本综述的核心贡献如下: * 区别于泛泛概述LRMs,我们聚焦高效推理这一新兴关键议题,提供深度定向分析。 * 归纳推理低效的常见模式,并阐明大型模型效率优化的独特挑战。 * 系统回顾提升推理效率的最新进展,涵盖从预训练、监督微调、强化学习到推理的端到端LRM开发流程。
