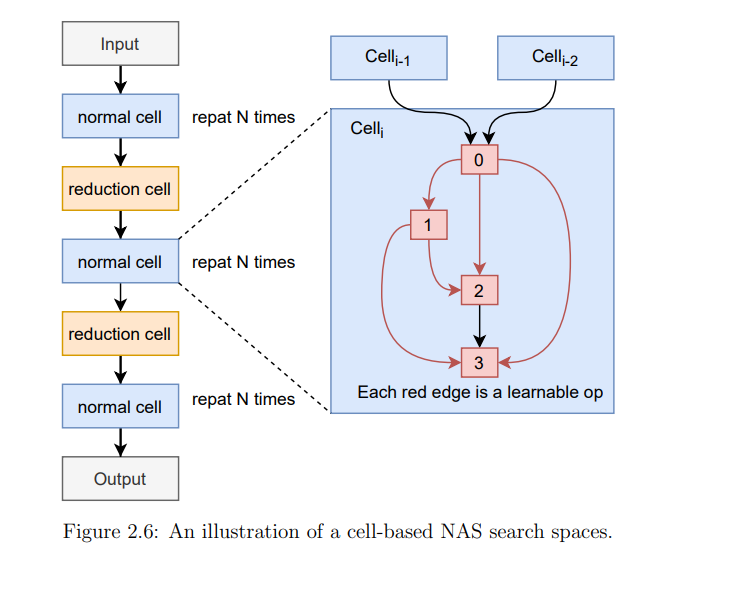
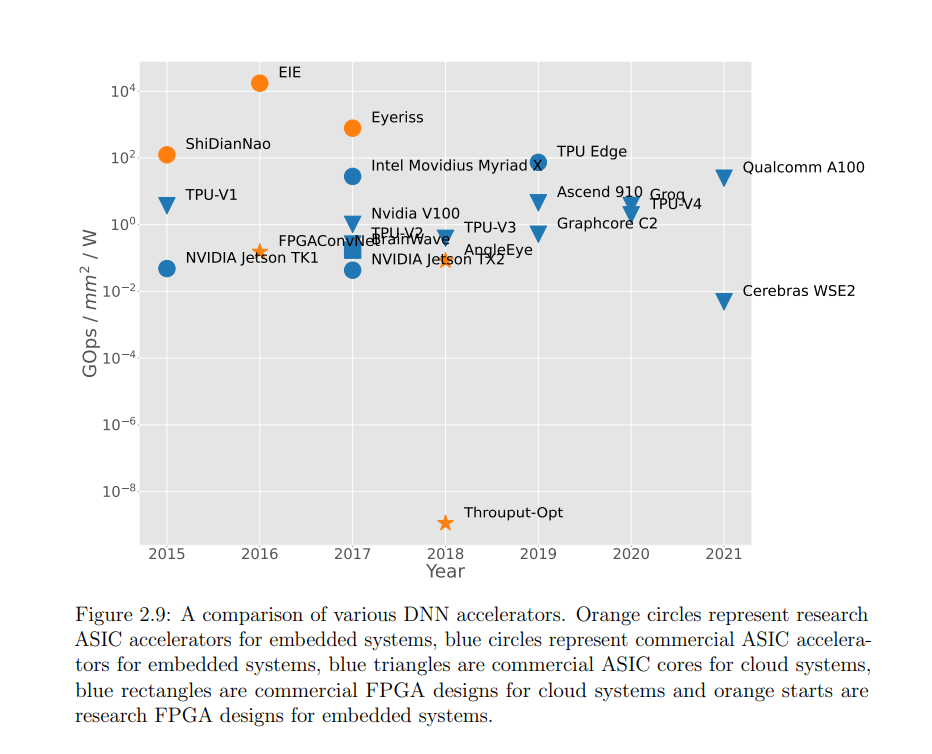
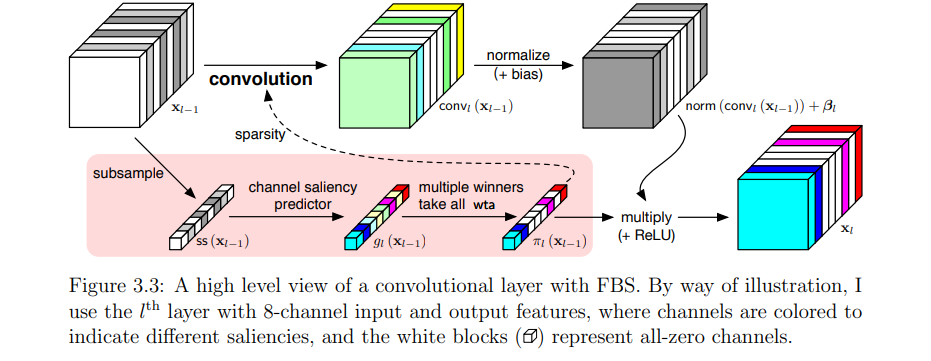
**深度神经网络(DNN)在许多领域都提供了最先进的性能,但这一成功是以高计算和内存资源为代价的。**由于DNN推理在边缘和云系统上都是一种流行的工作负载,因此迫切需要提高其能效。改进的效率使dnn能够在更大范围的目标市场中使用,并有助于提高性能,如果今天经常受到功率限制。本文采用软硬件协同设计的方法,提高了不同硬件平台上深度神经网络推理的性能。我首先展示了一些降低DNN运行时成本的软件优化技术。总的来说,我证明了模型大小可以减少34倍。不同风格的神经网络压缩技术的组合可以在缩小内存足迹方面提供成倍的收益。这些技术适用于在内存敏感的边缘设备上运行DNN推理。利用运行时和依赖数据的特征信息,我开发了一种动态剪枝策略,其性能明显优于现有的静态剪枝方法。所提出的动态剪枝不仅减少了模型大小,而且减少了GPU的乘累加操作数量。我还介绍了一种新的量化机制,该机制被调整为适合模型参数的自然分布,这种方法减少了DNN推断所需的位操作总数。然后,本文专注于使用自定义硬件加速DNN。构建了一个名为Tomato的框架,它在FPGA设备上生成多精度和多算法硬件加速器。软硬件联产流程从高层神经网络描述中部署硬件加速器,利用FPGA器件的硬件可重构性支持灵活的每层量化策略。然后,我证明了自动生成的加速器在延迟和吞吐量方面比最接近的基于FPGA的竞争对手至少高出2到4倍。为ImageNet分类生成的加速器以每秒超过3000帧的速度运行,延迟仅为0.32ms,使其成为延迟关键、高吞吐量的云端推理的合适候选。最后,我展示了自动化机器学习技术如何通过硬件感知来改进,以为新兴类型的神经网络和新的学习问题设置产生高效的网络架构。硬件感知的网络架构搜索(NAS)能够发现更节能的网络架构,并在图神经网络等新兴神经网络类型上实现显著的计算节省。在8个不同的图数据集上与7个人工和NAS生成的基线相比,所提出的低精度图网络架构搜索提高了大小-精度的帕累托前沿。此外,我演示了硬件感知的NAS可以应用于多任务多设备少样本学习场景。在具有各种硬件平台和约束的流行的少样本学习基准中,所提出的方法的性能明显优于各种NAS和人工基准。在5路1样本Mini-ImageNet分类任务上,所提方法在减少60%计算量的情况下,比最好的人工基线在准确率上提高了5.21%。