【伯克利博士论文】硬件感知的高效深度学习,154页pdf

摘要
神经网络(NNs)的准确性已经在广泛的问题中得到了显著的提高,通常是通过高度过参数化的模型实现的。尽管这些最先进的模型具有准确性,但它们的庞大规模使其无法部署到许多资源受限的应用程序中,如实时智能医疗保健监测、自动驾驶、音频分析和语音识别。这就给实现普适深度学习带来了一个问题,它需要低能耗、高精度的实时推理和有限的计算资源。
要实现能实现实时约束和最佳精度的高效NN,需要1)NN架构设计、2)模型压缩方法和3)硬件引擎设计的协同优化。以前追求高效深度学习的工作更多地关注于优化代理指标,如内存大小和FLOPs,而硬件规格实际上在决定整体性能方面起着重要作用。此外,由于设计空间非常大,在以往的文献中,上述三个方面往往是单独的、经验的优化,使整个设计过程耗时且次优。
本文首先系统地研究了一种广泛应用的标准模型压缩技术——量化方法。我们没有使用启发式设计或昂贵的搜索,而是利用Hessian信息来解决混合精度量化问题,我们提出的Hessian- aware量化(HAWQ)方法在不同的网络和数据集上实现了最先进的性能。我们进一步使整个管道全自动(HAWQV2),并探索了不同任务(QBERT)上量化(ZeroQ)的不同方面。
基于我们的系统量化方法,我们将硬件规格和部署纳入设计空间(HAWQV3)。该神经结构被纳入协同设计(CoDeNet),并被自动搜索(HAO)。最后,通过引入基于教师的分段蒸馏馏(ETA),提高了HW-SW自动化协同设计管道的整体效率。总之,我们在本文中的工作展示了从传统的神经网络设计到硬件感知的高效深度学习的进化步骤。我们相信,这将进一步加速在资源有限的设备和现实应用中部署先进的神经网络。
引言
随着最先进的深度学习模型的参数大小和计算量急剧增长,在不同的硬件平台上高效部署这些模型变得越来越重要。在特定的硬件资源和约束条件下,1) 模型压缩,2) 神经结构设计/搜索,3) 硬件优化是获得可行解的主流方法。模型压缩包括量化、修剪、知识蒸馏和因式分解等方法,其目的是对预先训练好的模型进行压缩,包括模型大小和计算量。随着当前硬件对低精度计算的支持,量化已经成为解决这些挑战的流行过程。从另一个角度来看,NAS算法试图寻找一个有效的神经结构,然后从零开始训练它。相比之下,硬件优化总是在神经结构和模型压缩方法固定之后进行。尽管有这些优点,但为了充分利用该系统,实现硬件感知的高效深度学习,在本文中我们试图解决的问题有三个。
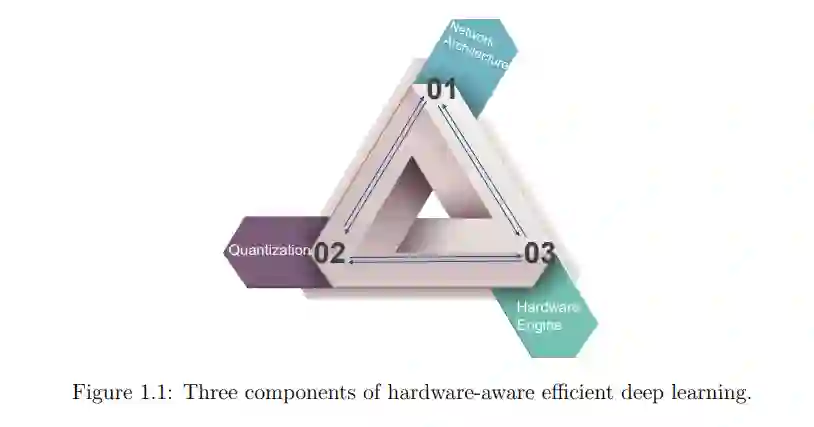
首先,我们要注意的是,实现高效深度学习的三个组成部分并不相互正交。如图1.1所示,特定神经体系结构的性能实际上与模型压缩方法和硬件规格高度相关。例如,在具有适当配置的FPGA板上,具有4位量化的ResNet50可以比具有8位量化的ResNet50运行得更快。但是在只支持8位整数的GPU上,8位量化ResNet50可以达到与4位ResNet50相同的速度,同时能够获得更高的精度。在本文中,我们的目标是实现硬件感知的高效深度学习,我们综合考虑了这三个方面,并试图在它们之间的权衡中获得最佳点。
其次,之前的工作试图优化代理指标,如模型大小和神经网络模型的FLOPs,假设这些理论指标与实际有效指标(如延迟、吞吐量和能耗)高度相关。然而,有人指出,代理指标在特定情况下可能具有误导性。为了避免次优解的出现,本文利用已开发的硬件引擎或模拟器直接优化实际指标。
最后,综合考虑神经网络架构、模型压缩和硬件设计,可以形成一个非常大的搜索空间。以关节空间的一小部分为例,混合精度量化允许神经网络的每一层选择特定的量化位宽,这导致位宽配置的搜索空间呈指数级大。考虑到搜索空间的大小,以前的方法通常是启发式的,这需要领域知识和人工努力,或者是耗时的,这需要强大的计算资源来执行搜索过程。
在本文中,我们通过应用Hessian分析和整数优化等优化方法,以及基于学习的技术,如延迟和精度模拟器,以及块知识蒸馏,使我们的方法自动化和高效。本文提出的方法能够在解决上述问题的同时取得良好的性能。例如,通过我们的混合精度量化,我们在各种模型上实现了10倍的压缩比,只有大约1%的精度下降(请参阅第6章和第7章)。此外,作为我们使用HW-SW联合设计的一个例子,我们的4位/8位混合精度模型在Pascal VOC上得到67.1 AP50,只有2.9 MB大小,比Tiny-YOLO小21倍,但精度更高10%(如第12章)。
在本文中,我们首先介绍了在第二章中我们用来定义硬件感知的高效深度学习的指标。在第三章中,我们展示了应用硬件感知的高效深度学习的动机。然后我们将我们的工作分为两行,第一行展示了我们在系统量化方面的进展,第二行描述了我们在图1.1中自动和共同探索三个设计空间的技术。具体来说,第四章介绍了量化的概念和相关工作,第五章到第八章介绍了我们的工作HAWQ, HAWQV2, Q-BERT, ZeroQ,第九章给出了结论。第十章介绍了软硬件协同设计的研究方向和已有的研究成果。我们在第11章到第14章展示了我们的作品HAWQV3, CoDeNet, HAO和ETA,并以第15章作为结论。最后,在第16章中,我们回顾了我们工作的重要性,并讨论了未来可能的方向。


专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“E154” 就可以获取《【伯克利博士论文】硬件感知的高效深度学习,154页pdf》专知下载链接





