摘要
最近,我们见证了对抗性机器学习技术的快速发展,它破坏了底层机器学习模型的安全性,并导致了有利于对抗者的故障。最常见的对抗性机器学习攻击包括故意修改机器学习模型的输入,其方式是人类无法察觉的,但足以导致模型失败。对抗性例子最初是为图像设计的,也可以应用于自然语言处理(NLP)和文本分类。这项工作提出了一个研究和实施对抗性例子--以及防御机制--来对抗基于BERT的NLP分类器。用于测试拟议方法的数据集包括北约文件,现在已经解密,这些文件最初拥有不同的保密级别,由文件中嵌入的标签指定。BERT模型被用来根据这些文件的初始敏感性对其进行自动分类。虽然攻击者的目的是改变分类级别,但防御方致力于阻止这些企图。实验表明,对抗性文本实例可以误导模型,导致拒绝服务,当文件被识别为具有比实际更高的敏感性时,或者导致数据泄漏,当文件被解释为具有比实际更低的敏感性时。通过采取适当的防御措施,有可能抵制特定类型的对抗性攻击,但代价是降低模型的整体准确性。
引言
机器学习系统的广泛使用和成功使其成为攻击者越来越频繁的目标,他们的目标是滥用这些系统为自己谋利。这种现象导致了对抗性机器学习的发展[1],这是一个结合了机器学习和网络安全的领域,涉及到对智能系统可能的攻击以及对策的研究。因此,尽管机器学习在一般情况下能快速提供结果,而且准确性很高,但它并非没有风险,如果在没有充分的安全分析的情况下实施,后果可能是灾难性的。例如,特斯拉Model S 75自动驾驶系统可以通过隐藏高速公路标志或添加人类驾驶忽略的标记来进行操纵,从而导致,例如,转向错误的车道[2]。
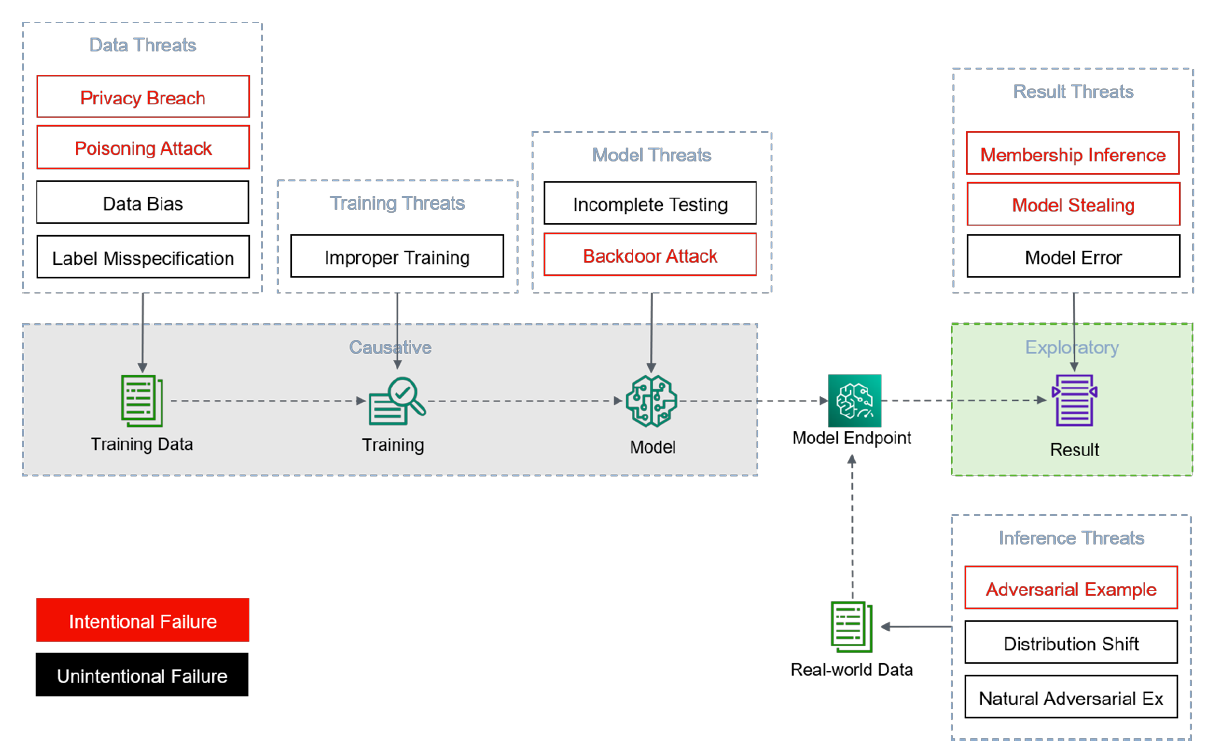
图1描述了机器学习系统的各个组成部分可能受到的攻击类型,按有意和无意的故障分组。机器学习的最大威胁之一是数据的完整性,表现为数据中毒。作为训练集一部分的数据,如果被破坏,会改变模型的学习能力,从而影响其性能。训练样本通常不涵盖所有可能的角落案例。一些没有被考虑的样本可能被模型错误分类,导致不正确的预测。提供其预训练模型的第三方服务通常只想提供查询访问,而不提供额外的信息。任何针对模型保密性的安全漏洞都会泄露敏感信息,可能会揭示和暴露出模型结构。一般来说,机器学习服务提供者希望对用作训练集的数据相关信息进行保密。成员推理攻击的目的是通过泄露训练集的一部分来损害数据隐私。