

人类使用多种感官来理解环境。视觉和语言是其中两个最重要的感官,因为它们使我们能够轻松地交流思想并感知周围的世界。近年来,人们对创建具有人类感官的视频-语言理解系统产生了浓厚的兴趣,因为视频-语言对可以模拟我们的语言媒介和具有时间动态的视觉环境。在这篇综述中,我们回顾了这些系统的关键任务,并突出了相关的挑战。基于这些挑战,我们从模型架构、模型训练和数据的角度总结了它们的方法。我们还对这些方法进行了性能比较,并讨论了未来研究的有前景方向。
视觉和语言构成了我们感知的基本组成部分:视觉使我们能够感知物理世界,而语言则使我们能够描述和讨论它。然而,世界不仅仅是静态图像,而是展现了随着时间推移,物体移动和交互的动态特性。通过时间维度,视频能够捕捉这些表征物理世界的时间动态。因此,为了赋予人工智能类人感知能力,研究人员一直在开发视频-语言理解模型,这些模型能够解释视频的时空动态和语言的语义,最早可以追溯到20世纪70年代(Lazarus, 1973; McGurk和MacDonald, 1976)。这些模型区别于图像-语言理解模型,因为它们具有解释时间动态的额外能力(Li et al., 2020)。
这些模型在各种视频-语言理解任务中表现出了令人印象深刻的性能。这些任务从粗粒度到细粒度评估视频-语言模型的理解能力。例如,对于粗粒度理解,文本-视频检索任务评估模型将语言查询与整个视频整体关联的能力(Han et al., 2023)。对于更细粒度的理解能力,视频字幕生成模型需要理解视频的整体和详细内容,然后用简洁的语言描述内容(Abdar et al., 2023)。视频问答中的细粒度理解仍然是一个困难的任务,模型需要识别细微的视觉对象或动作,并推断它们的语义、空间、时间和因果关系(Xiao et al., 2021)。
为了有效地执行这些视频-语言理解任务,视频-语言理解工作需要解决三个挑战。第一个挑战在于设计一个适当的神经架构来建模视频和语言模态之间的交互。第二个挑战是设计一个有效的策略来训练视频-语言理解模型,以便能够有效地适应多种目标任务和领域。第三个挑战是准备高质量的视频-语言数据来支持这些模型的训练。
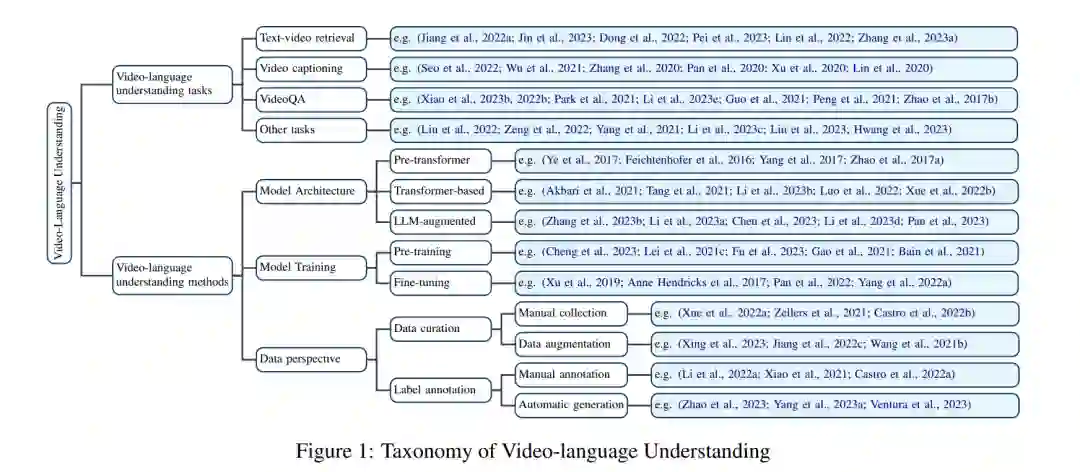
尽管近年来有少数工作试图综述视频-语言理解领域,但它们大多集中在某一个挑战上,例如,基于Transformer的架构(Ruan和Jin, 2022)和大语言模型(LLM)增强的架构(Tang等, 2023b)(第一个挑战),自监督学习(Schiappa等, 2023)和预训练(Cheng等, 2023)(第二个挑战),以及数据增强(Zhou等, 2024)(第三个挑战)。此外,其他一些工作也仅关注于某一个视频-语言理解任务,例如视频问答(Zhong等, 2022)、文本-视频检索(Zhu等, 2023)和视频字幕生成(Abdar等, 2023)。这种狭窄的关注与日益增长的共识相矛盾,即主张开发能够适应多种任务和领域的通用人工智能。在一个人机交互场景中,个人可能会反复就视频提出问题、搜索相关时刻并请求摘要。这种使用场景需要广泛的能力来理解视频和语言内容,而不仅仅局限于某个特定任务。此外,视频-语言理解系统的开发通常涉及一个多步骤过程,包括设计模型架构、制定训练方法和准备数据,而不是一个单一步骤的工作。因此,本文旨在提供一个全面且有意义的综述,以连接视频-语言理解的各个方面。我们的贡献如下:
- 我们总结了视频-语言理解的关键任务,并讨论了它们的共同挑战:模态内和跨模态的交互、跨领域适应以及数据准备。
- 我们从三个角度对视频-语言理解的研究工作进行了清晰的分类,即前述的三个挑战角度:(1)模型架构角度:我们将现有工作分为前Transformer、基于Transformer和LLM增强的架构来建模视频-语言关系。在后一类中,我们讨论了利用LLM优势来增强视频-语言理解的最新努力。(2)模型训练角度:我们将训练方法分为预训练和微调,以适应目标下游任务的视频-语言表示。(3)数据角度:我们总结了现有的策划视频-语言数据并对其进行标注的方法,以支持视频-语言理解模型的训练。
- 最后,我们提供了我们的展望并提出了未来研究的潜在方向。 视频-语言任务
**文本-视频检索
文本-视频检索任务是根据语言查询搜索对应的视频(文本到视频),或相反地根据视频搜索语言描述(视频到文本)。在实际应用中,返回整个视频可能并不理想。因此,视频片段检索(VMR)应运而生,旨在根据用户查询准确定位视频中的相关时刻。VMR需要更细致和细粒度的理解,以捕捉视频中的不同概念和事件,从而定位特定时刻,而不是像标准文本-视频检索那样捕捉整体主题。
**视频字幕生成
视频字幕生成是为视频生成简洁的语言描述的任务。一个视频字幕生成模型接收视频作为输入,并可选地接收从视频音频转录的语言文本。通常,模型会为整个视频生成一句话的字幕,或者生成一段更详细的摘要。
**视频问答(videoQA)
视频问答是基于问题q和视频v预测正确答案的任务。视频问答有两种基本类型,即多选视频问答和开放式视频问答。在多选视频问答中,模型会提供若干候选答案,并选择其中的正确答案。开放式视频问答可以被定义为分类问题、生成问题或回归问题。基于分类的视频问答将视频-问题对与预定义词汇集中答案相关联。基于生成的视频问答不受词汇集限制,模型可以生成一系列表示答案的词元。基于回归的视频问答通常用于计数问题,例如计算动作的重复次数或视频中某个物体的数量。
**视频-语言理解任务之间的关联
这些任务构成了视频-语言理解能力的三个基本测试平台(参见附录A中的示例)。在图2中,我们提供了一个层次结构,描述了它们视频-语言理解程度的逐级提升。在基础层次上,文本-视频检索全局地将整个视频与文本内容关联。在中等层次上,视频字幕生成比检索任务更困难,因为它需要选择性地将视频中的实体和事件映射到语言模态。在最高层次上,视频问答探索视频和语言内容的关系以生成适当的输出。每个层次的视频-语言理解任务都有一个对应的版本,要求更推理或更细粒度的理解,例如,推理视频问答(Xiao等, 2021;Li等, 2022a)与视频问答,密集视频字幕生成(Zhou等, 2018b)或视频章节生成(Yang等, 2023b)与视频字幕生成,视频片段检索(时间定位)与文本-视频检索。这些更推理或更细粒度的任务提出了更多挑战,并在当前研究中朝向人类智能核心的方向发挥着越来越重要的作用(Fei-Fei和Krishna, 2022)。

视频-语言理解的模型架构
解决模态内和跨模态交互的挑战是设计视频-语言理解模型架构的关键目标,这些架构可以分为前Transformer架构和基于Transformer的架构。具有显著零样本能力的LLM(大语言模型)的出现,促使了LLM增强架构的设计,这些架构表现出对各种视频-语言理解任务的跨领域适应能力。
**前Transformer架构
在Transformer架构普及之前,视频-语言理解模型主要依赖于传统的神经网络架构,例如卷积神经网络(CNN)用于视频特征提取,循环神经网络(RNN)或长短期记忆网络(LSTM)用于语言处理。这些架构主要处理模态内的特征提取和表示学习,但在处理跨模态交互方面存在局限。
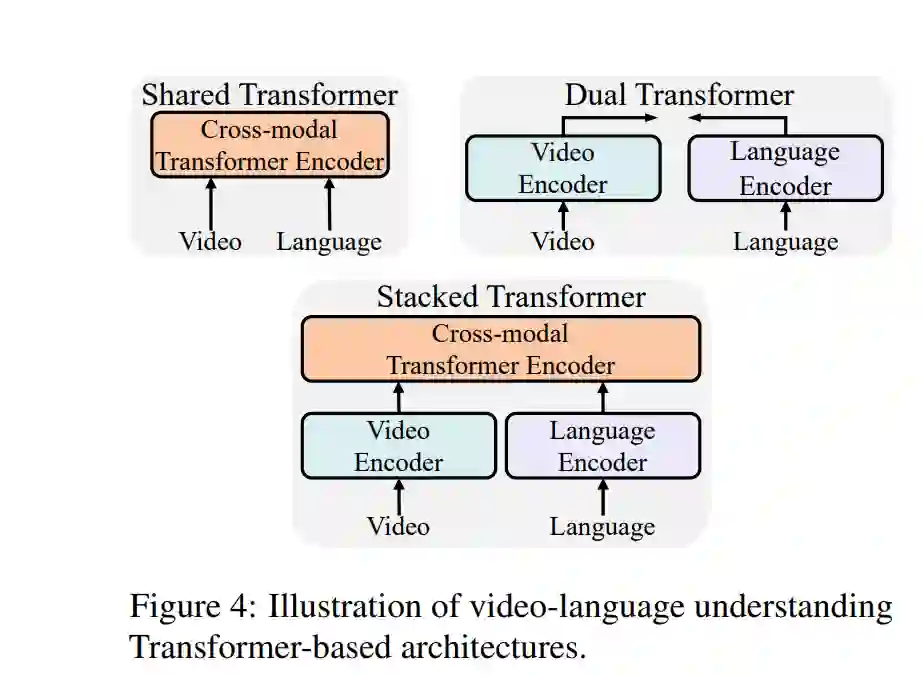
**基于Transformer的架构
Transformer架构以其自注意力机制在处理长距离依赖和并行计算方面的优势,成为视频-语言理解的主流选择。基于Transformer的模型,如ViLBERT、VideoBERT等,通过联合编码视频和语言模态,实现了更有效的跨模态交互。这些模型能够捕捉视频的时间动态和语言的语义关系,从而提升视频-语言任务的性能。
**LLM增强架构
大语言模型(LLM)的崛起,如GPT-3,展示了强大的零样本和少样本学习能力,使得它们能够处理多种任务。LLM增强架构将LLM的优势引入视频-语言理解,通过在各种视频-语言任务中利用LLM的跨领域适应能力,进一步提高了模型的通用性和性能。这些架构不仅能够处理视频和语言的复杂交互,还能够在不同任务和领域间自适应。 总结而言,视频-语言理解模型架构的设计不断演进,从早期的前Transformer架构,到基于Transformer的架构,再到如今的LLM增强架构,每一步都旨在更好地解决模态内和跨模态交互的挑战,推动视频-语言理解能力的提升。
结论
在本文中,我们综述了视频语言理解这一广泛的研究领域。特别地,我们对相关的视频语言理解任务进行了分类,并从模型架构、模型训练和数据等角度讨论了有意义的见解。我们对每个角度进行了深入分析,最后总结了有前景的未来研究方向。我们希望我们的综述能够促进更多的研究,致力于构建能够全面理解动态视觉世界并与人类进行有意义互动的有效人工智能系统。