
机器如何创造逼真的图像?这是个有意思的问题。深度学习算法的发展为这个问题的解决带来了机会。南洋理工大学Chuanxia Zheng博士论文系统性来回答这个问题。论文的目的是展示在解决各种视觉合成和生成任务方面的研究贡献,包括图像翻译、图像补全和场景分解。非常值得关注。
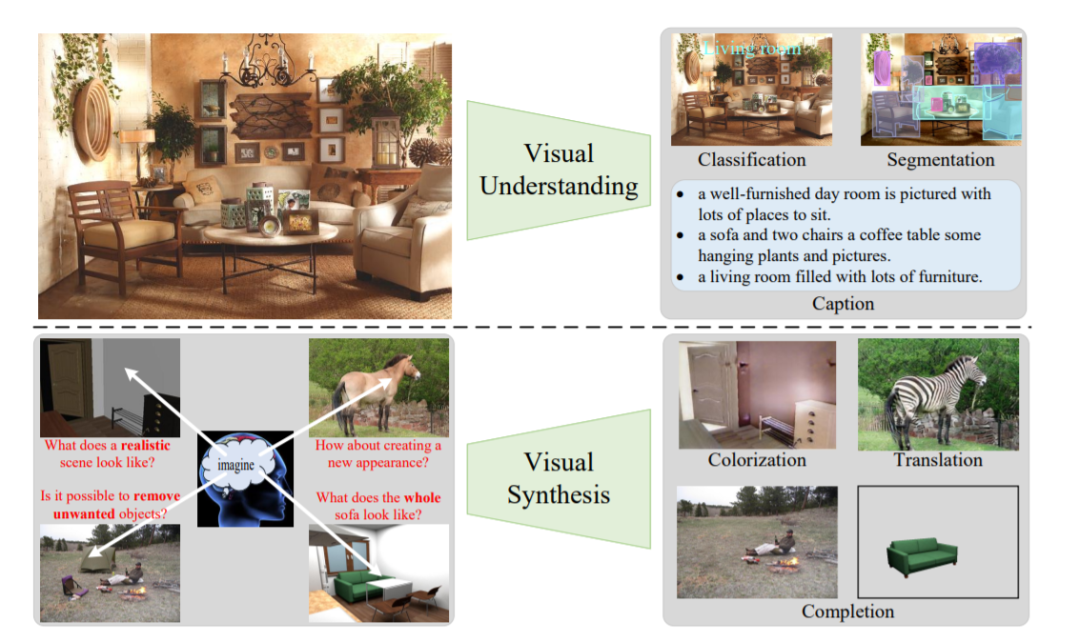
本文是对目标的整体展示。在第一行,我们首先展示了一般的视觉理解任务,由于大量的视觉数据和深度学习网络,这些任务在图像分类、实例分割和图像字幕等方面取得了快速的进展[64]。在这篇论文中,我们试图探索相反的方向,视觉合成,在那里我们促使模型想象和生成新的逼真的图像,通过估计数据分布。

ChuanXia Zheng是南洋理工大学计算机科学与工程学院的博士生,导师是at-Jen Cham和Jianfei Cai。研究兴趣涵盖计算机视觉和机器学习。目前的工作重点是场景理解,特别是图像生成、补全和翻译、3D场景理解和补全,目标是构建智能机器,能够重建一个近乎真实的世界。https://www.chuanxiaz.com/

本文的目的是展示我们在解决各种视觉合成和生成任务方面的研究贡献,包括图像翻译、图像补全和场景分解。本论文共五篇论文,每一篇论文都提出了一种新的基于学习的方法来合成内容可信且外观逼真的图像。每一项工作都证明了所提出的方法在图像合成方面的优越性,并对其他任务如深度估计做出了进一步的贡献。
第一部分描述了改变视觉外观的方法。特别地,在第二章中,我们提出了一个合成到真实的翻译系统来处理真实世界的单图像深度估计,其中只使用合成图像深度对和未配对的真实图像进行训练。该模型通过利用低成本但高度可重用的合成数据,为现实世界的评估任务提供了一个新的视角。在第三章中,重点是一般的图像到图像(I2I)翻译任务,而不是狭义的合成到现实的图像翻译。提出了一种新颖的空间相关损失方法,该方法简单、高效、有效地保持了场景结构的一致性,同时支持较大的外观变化。自相似的空间模式被用作定义场景结构的一种手段,这种空间相关的损失只用于捕捉图像中的空间关系,而不是域外观。广泛的实验结果表明,在多个I2I任务中,包括单模态、多模态甚至单图像翻译,使用这种内容损失可以得到显著的改进。此外,这种新的损失可以很容易地集成到现有的网络架构中,因此具有广泛的适用性。
第二部分介绍了为屏蔽区域生成语义上合理内容的方法。与第一部分中单纯修改局部外观不同,本文提出了两种方法来为给定的图像创建新的内容和逼真的外观。在第四章中,我们引入了一个新的任务,叫做多元图像补全,即生成多种多样的似是而非的结果,而不是像以前的作品那样,对这个高度主观的问题只进行单一的“猜测”。在本章中,我们提出了一个新颖的概率原则框架,该框架在这一新任务中取得了最先进的结果,并成为后续工作的基准。然而,我随后观察到,基于卷积神经网络(CNN)的体系结构通过许多堆叠层模拟了长期依赖关系,在这些层中,孔洞逐渐受到邻近像素的影响,从而产生一些工件。为了缓解这个问题,在第5章中,我建议将图像补全作为一个无方向的序列到序列的预测任务,并在第一阶段部署一个转换器来直接捕获编码器中的长期依赖关系。至关重要的是,一个带有小且不重叠接受域(RF)的限制性CNN被用于令牌表示,这允许转换器显式地建模在所有层中具有同等重要性的远程上下文关系,当使用较大的RF时,不会隐式地混淆邻近的令牌。在多个数据集上的大量实验表明,与以往基于CNN的方法相比,该方法具有更好的性能。
第三部分将识别学习和最新的生成建模结合到一个整体场景分解和完成框架中,在这个框架中,一个网络被训练成将场景分解为单个对象,推断其潜在的遮挡关系,此外,想象最初被遮挡的对象可能看起来像什么,而只使用单个图像作为输入。在第6章中,我们的目标是对场景进行更高层次的结构分解,自动识别物体并为被遮挡的区域生成完整的形状和逼真的外观,而不需要像在第二部分中那样使用人工掩蔽。为了实现这一目标,我们提出了一种新的流程,通过多次迭代将实例分割和场景完成两项任务交织在一起,以分层的方式求解对象。该系统比目前的先进方法有了显著的改进,并能实现一些有趣的应用,如场景编辑和重组。
综上所述,本文介绍了一系列通过改变外观、想象语义内容、自动推断不可见的形状和外观来合成真实感图像的工作。
目录内容:
1 Introduction
- 1 Changing Visual Appearance: Image-to-Image Translation
- 2 Synthetic-to-Realistic Translation
- 3 Spatially-Correlative Loss for Various Image Translation Tasks
II Generating Semantic Content: Image Completion
- 4 Pluralistic Image Completion
- 5 Image Completion via Transformer
III Modeling Shape and Appearance: Completed Scene Decomposition
- 6 Visiting the Invisible
- 7 Conclusion and Future Directions 133


