

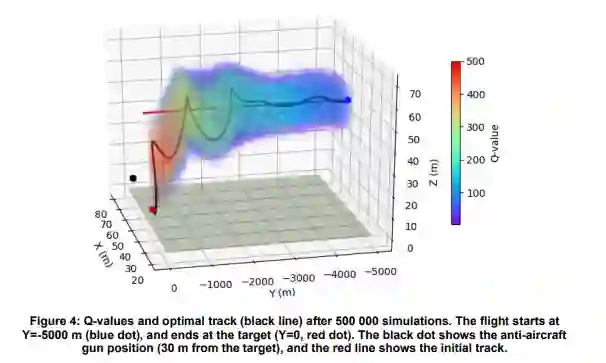
本文提出了一种方法,旨在优化穿越敌人高射炮火力范围的飞行路径。这适用于在完全或部分由高射炮控制的空域中移动的各种飞机、导弹和无人机。为此,使用了Q-learning--一种强化(机器)学习--试图通过反复的半随机飞行路径试验,找到避开高射炮的最佳策略。Q-learning可以在不直接模拟高射炮的情况下产生一条穿过敌人火力的最佳飞行路径。仍然需要对手的反应,但这可以来自于黑盒模拟、用户输入、真实数据或任何其他来源。在这里,使用一个内部工具来生成防空炮火。这个工具模拟了一个由火控雷达和卡尔曼飞行路径预测滤波器引导的近距离武器系统(CIWS)。Q-learning也可以用神经网络来补充--所谓的深度Q-learning(DQN)--以处理更复杂的问题。在这项工作中,展示了使用经典Q-learning(无神经网络)对一个穿越高射炮位置的亚音速飞行路线的优化结果。
成为VIP会员查看完整内容
相关内容

相关主题

相关VIP内容
相关资讯
相关论文