作者丨科技猛兽编辑丨极市平台 极市导读 本文提出一种语言增强的 CLIP 方法 (Language augmented CLIP, LaCLIP) ,通过语言重写来增强 CLIP 的训练。LaCLIP 的核心思路是利用 LLM 重写每条文本,以此作为数据增强。这些重写的文本在句子结构和词汇方面表现出多样性,同时保留了原始的关键概念和含义。
本文目录
1 使用语言重写改进 CLIP 训练
(来自谷歌,MIT) 1 LaCLIP 论文解读 1.1 CLIP 中的文本输入缺少有效的数据增强 1.2 CLIP 的训练目标 1.3 多样化的文本对生成策略 1.4 大规模的文本重写 1.5 使用增强的文本数据训练 CLIP 模型 1.6 实验设置 1.7 Zero-Shot 分类实验结果 1.8 Few-Shot 分类和 Linear Probing 实验结果
太长不看版
本文研究的是对比语言-图像预训练 (Contrastive Language-Image Pre-training, CLIP) 的训练过程,它使用成对的图像和文本数据来训练视觉模型。CLIP 模型使用对比损失函数进行训练,这个损失函数通常依赖于数据增强来防止过拟合。但是,在 CLIP 的训练范式中包含图片和文本,而数据增强总是应用于图片,文本输入在整个训练过程中保持不变。作者认为 "文本输入缺少有效的数据增强" 这个问题限制了文本和图像的对应关系。 因为,本文提出一种语言增强的 CLIP 方法 (Language augmented CLIP, LaCLIP) ,通过语言重写来增强 CLIP 的训练。LaCLIP 的核心思路是利用 LLM 重写每条文本,以此作为数据增强。这些重写的文本在句子结构和词汇方面表现出多样性,同时保留了原始的关键概念和含义。在训练期间,LaCLIP 随机选择原始文本或重写版本中的一个作为文本数据增强。作者在 CC3M, CC12M, RedCaps 和 LAION-400M 这四个数据集都做了实验,证明这样做可以显着提高 CLIP 模型的迁移性能,尤其是 ImageNet zero-shot 精度。
1 使用语言重写改进 CLIP 训练
论文名称:Improving CLIP Training with Language Rewrites
论文地址:
https//arxiv.org/pdf/2305.20088.pdf
- 1 LaCLIP 论文解读:
1.1 CLIP 中的文本输入缺少有效的数据增强
对比语言-图像预训练 (Contrastive Language-Image Pre-training, CLIP) 的主要作用是从成对的图像和文本数据中学习可以迁移的特征。CLIP 的训练过程中有两点式可以扩展到:数据和算力。首先,大规模的视觉语言配对数据支持 CLIP 进行有效的训练。其次,CLIP 对语言和图像联合嵌入使其对算力的要求也具有缩放性。因此,对比语言-图像预训练的 CLIP 学习到的特征在各种下游任务中始终优于其他纯视觉预训练方法,比如如 SimCLR[1]或者 MAE[2]。 CLIP 方法属于对比学习,其通常依赖于数据增强 (Data augmentation) 来防止模型过拟合。但是在 CLIP 的预训练过程中,数据增强通常大多被应用给图片部分。相比之下,文本输入在整个训练过程中被忽略,缺乏任何形式的数据增强。这就导致了各种数据增强之后的图片,总是与相同的文本输入对应。这种不对称性带来了两个问题:
- **图像编码器从语言侧只接收到了有限的监督信号:**这是因为相同的图像始终与相同的单词配对。所以语言侧为图像侧提供的指导信息比较少。
- **文本编码器在每个 Epoch 中反复遇到完全相同的文本:**增加了文本过度拟合的风险,并显着影响最终训练出的图片编码器的 Zero-Shot 的迁移性质。
所以说了这么半天,其实就是想表达给文本输入以合适的数据增强策略是至关重要的。那么现有的针对文本的数据增强[3]策略有:Replacement 或者 Masking 等等,大多都是词汇级别的处理。这些方法对丰富文本结构的影响有限。目前,缺乏对语言信息的重写策略,可以有效地增强句子,同时保留关键概念和含义。CLIP 的训练迫切需要这种策略来确保最佳的性能。 另一方面,LLM 在自然语言任务中表现出卓越的性能,超过了人类的能力。受这些进步的启发,本文作者自然地探索了利用 LLM 给定文本来生成的不同重写的版本的潜力。开源的 LLaMA 模型[4]尽管缺乏使用指令进行微调,具有出色的上下文内学习 (In-Context Learning, ICL) 的能力,从而能够在有限的上下文中进行预测。LLaMA 可以为整个数据集生成多样化和丰富的文本重写,来作为本文的数据增强。
1.2 CLIP 的训练目标
在 CLIP 的训练过程中,首先给定 个配对的图文对 ,并使用数据增强对图像进行预处理。然后使用图像编码器 和文本编码器 来提取图像和文本特征。图像和文本的特征用来计算 InfoNCE 的损失,其中成对的图像和文本是正样本对,未配对的图像和文本被视为负样本。训练的损失函数可以表示如下: 式中, 是第 个图像-文本对, 代表对图像的数据增强操作, 是使用点积来计算距离的方式, 是温度系数。 在上式中,标准的 CLIP 损失函数只对图像应用了数据增强 ,而在整个训练过程中保持文本输入不变。本文建议使用文本数据增强 ,并将其作为文本编码器 的输入。
1.3 多样化的文本对生成策略
作者探索了不同生成文本对的策略:
- **使用 Chatbots 做重写:**作者从图像-文本数据集中随机抽取文本,并使用 ChatGPT[5]和 Bard[6]这两个网站,给一个 Prompt 比如:"Rewrite this caption of an image vividly, and keep it less than thirty words:" 来生新的文本。这个过程如图1所示。LLM 生成的文本保持原始文本的本质信息,确保了语义不会改变。但同时又很好地改写了其风格和细节。
图1:使用 ChatGPT 帮助构建文本数据增强:先采样一些文本数据集,再给 ChatGPT 一个 Prompt,比如:Rewrite this image caption 来指导它生成多个增强的文本数据。这些生成的数据保持主要对象不变,只改了句式和结构
- **MSCOCO 采样:**许多现有的图像字幕数据集都可以获得同一图像的多个文本描述,比如 MS-COCO[7] 数据集。在这个数据集中,每个图像都与5个不同的文本描述相关联,这些文本描述已被人类工作者仔细注释。从这个数据集中,作者随机选择图像的子集。对于每个选定的图像,我们选择一个描述作为输入文本,另一个作为输出文本。
- **人类重写:**作者从各种图像-文本数据集中随机抽取几个图像-文本对。为了确保多样化和多样化的文本变化,作者聘请人工注释者并根据相应观察图像中描述的内容重写字幕来完成。
 图1:使用 ChatGPT 帮助构建文本数据增强:先采样一些文本数据集,再给 ChatGPT 一个 Prompt,比如:Rewrite this image caption 来指导它生成多个增强的文本数据。这些生成的数据保持主要对象不变,只改了句式和结构
图1:使用 ChatGPT 帮助构建文本数据增强:先采样一些文本数据集,再给 ChatGPT 一个 Prompt,比如:Rewrite this image caption 来指导它生成多个增强的文本数据。这些生成的数据保持主要对象不变,只改了句式和结构经过上面所有的过程就可以得到4中文本数据增强策略:ChatGPT,Bard, COCO, 和人类版本。对于每一种策略,作者从配对图片-文本对中随机采样出16个原始文本并使用该策略生成新的文本,这些新的文本数据为 CLIP 提供了多样化的,更加全面的训练过程。 ChatGPT 方法得到的文本示例如下 (使用 "Source" 来表示从图像-文本数据集中采样的输入文本,并使用 "Target" 来表示每种策略生成的输出文本): Source: white and red cheerful combination in the bedroom for girl. Target: A bright and lively white-and-red color scheme in a girl's bedroom, creating a cheerful ambiance. Source: vintage photograph of a young boy feeding pigeons. Target: A charming vintage photograph capturing a young boy feeding a flock of pigeons in a bustling city square. Source: businessman with smartphone sitting on ledge by the sea. Target: Serene coastal view as a businessman sits on a ledge by the sea, using his smartphone.
1.4 大规模的文本重写
由于 ChatGPT 或 Bard 等闭源模型的 API 的昂贵的价格,为数亿文本生成重写是不切实际的。因此,作者也使用了开源模型 LLaMA。作者使用 LLAMA 的 In-Context Learning (ICL) 的能力重写图像-文本数据集中的每个文本输入。具体方法如下: 给定一个要重写的文本。作者做以下3步:
- 给定一个 Prompt,通知 LLM 重写图像描述的任务。
- 从上一节中得到的输入输出图文对中采样3组,每一组使用 "=>" 记号隔开。
- 给定需要重写的文本样本,然后是 "=>" 符号。
通过结合以上的3个部分,作者为 LLaMA 创建了一个全面的 Prompt,引导其有效生成多样化的重写的文本。 以上过程可以用下图2表示。左侧框里面的内容是输入给 LLaMA 的 Prompt,蓝色表示 Prompt 的输入,绿色表示 Prompt 的输出。最后1行 "=>" 的左侧代表要扩展的文本,右侧框代表了 LLaMA 生成的新文本。
1.5 使用增强的文本数据训练 CLIP 模型
CLIP 方法的关键是文本增强函数,它可以通过一个简单的随机抽样过程轻松实现,作者从原始文本或生成的重写之一中随机选择文本样本,如下式所示: 式中, 是样本 的第 个重写。为简单起见将原始文本表示为 。CLIP 训练的目标函数变为: 上式与式1的唯一区别是额外的文本增强 ,所有其他部分保持不变。与原始的 CLIP 相比,不会带来任何额外的计算或参数开销。通过将文本增强合并到 CLIP 中,作者在训练数据中引入了可变性和多样性,使得模型可以从原始文本和增强的文本中进行学习。这种简单有效的策略增强了训练的过程,并有助于 LaCLIP 方法的整体性能和迁移性。
1.6 实验设置
**数据集:**Conceptual Captions 3M (CC3M),Conceptual Captions 12M (CC12M),RedCaps 和 LAION-400。 **视觉编码器配置:**对于 CC3M, CC12M, 和 RedCaps 数据集,作者使用 ViT-B/16 架构。对于 LAION-400M 数据集,使用 ViT-B/16 和 ViT-B/32 架构。CC12M 数据集还使用了 ViT-S/16 和 ViT-L/16 架构。 **文本编码器配置:**使用 CLIP 中的最小文本编码器,tokenizer 与 CLIP 保持一致。vocabulary size 为 49, 408 最大上下文长度是 77。 **评测指标:**Zero-Shot (ZS) 分类精度, Few-Shot (FS) 分类精度和 Linear Probing (LP) 分类精度。 Zero-Shot (ZS) 分类:使用与 CLIP 论文相同的 prompt 模板。 Few-Shot (FS) 分类:使用 weighted kNN 分类器在冻结权重的模型上进行 5-shot 分类。 Linear Probing (LP) 分类:使用预训练好的图像编码器提取特征,并使用 L-BFGS 优化器训练一个分类头完成分类。
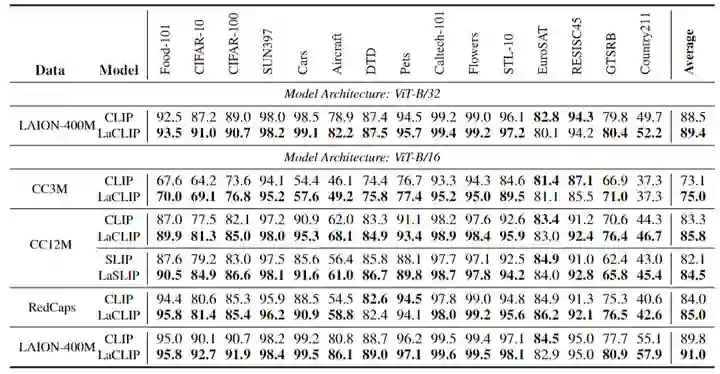
1.7 Zero-Shot 分类结果
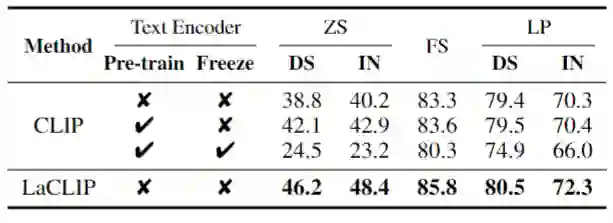
Zero-Shot 分类结果如下图3所示。在所有预训练的数据集中,本文的 LaCLIP 方法在 ImageNet 和下游任务上都对 CLIP 模型上实现了显着的性能提升。比如在 CC12M 数据集上训练模型时,本文呢的 LaCLIP 方法在 ImageNet 上的 top-1 精度上实现了超过 8% 的改进。而且,LaCLIP 和 CLIP 在训练期间共享相同的参数和计算成本。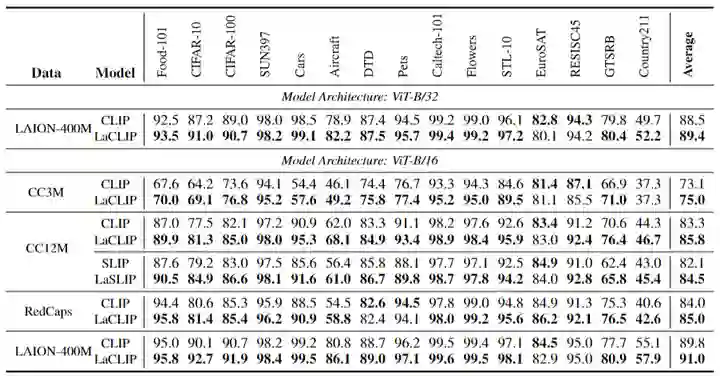
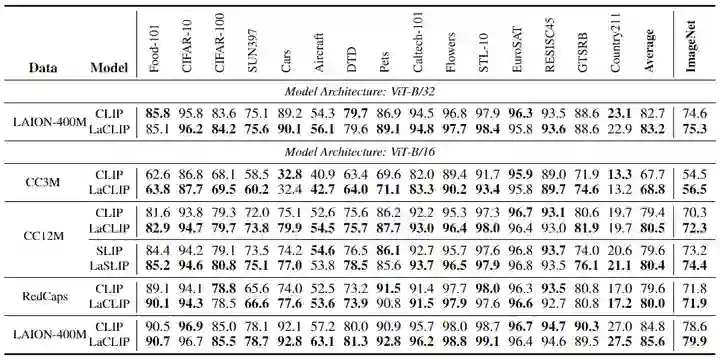
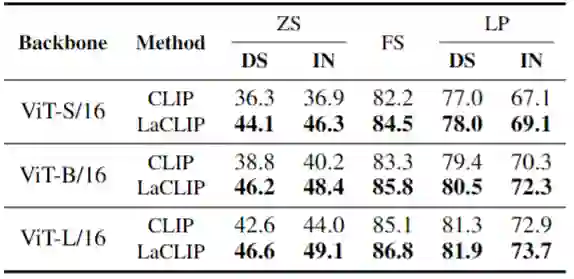
1.8 Few-Shot 分类和 Linear Probing 实验结果
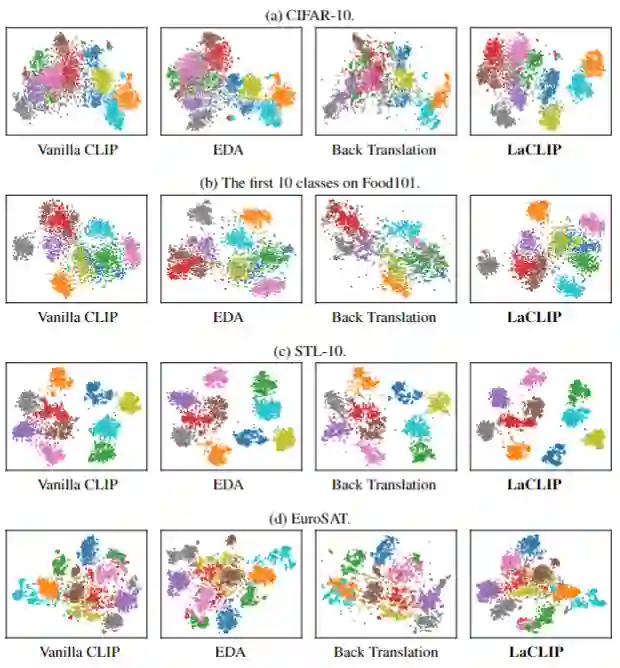
Few-Shot 分类和 Linear Probing 实验结果分别如下图4和5所示。本文的方法在绝大多数情况下始终优于普通 CLIP 或 SLIP。有趣的是,尽管从图像端引入了额外的自我监督,但 SLIP 在 Few-Shot 的设置中的性能比 vanilla 的 CLIP 还要差。通过结合本文提出的语言增强策略,SLIP 的 Few-Shot 性能有所提高,超过了 vanilla CLIP。这个结果也说明了文本增强对于 Few-Shot 情况的泛化性。 同时,Few-Shot 分类和 Linear Probing 性能的提升也证明了:文本增强方法不仅有利于更有效地对齐文本和图像的联合嵌入表征 (通过 Zero-Shot 实验证明),而且对于图像编码器提取到的纯视觉特征的质量也有帮助。 为视觉编码器提供更加丰富,更加多样化的文本信息,所带来的结果就是图像编码器能够学习更通用和更鲁棒的图像表征,而这些表征可以有效地在一系列下游任务中加以利用。