无需写代码能力,手搓最简单BabyGPT模型:前特斯拉AI总监新作
机器之心报道
GPT 原来这么简单?
-
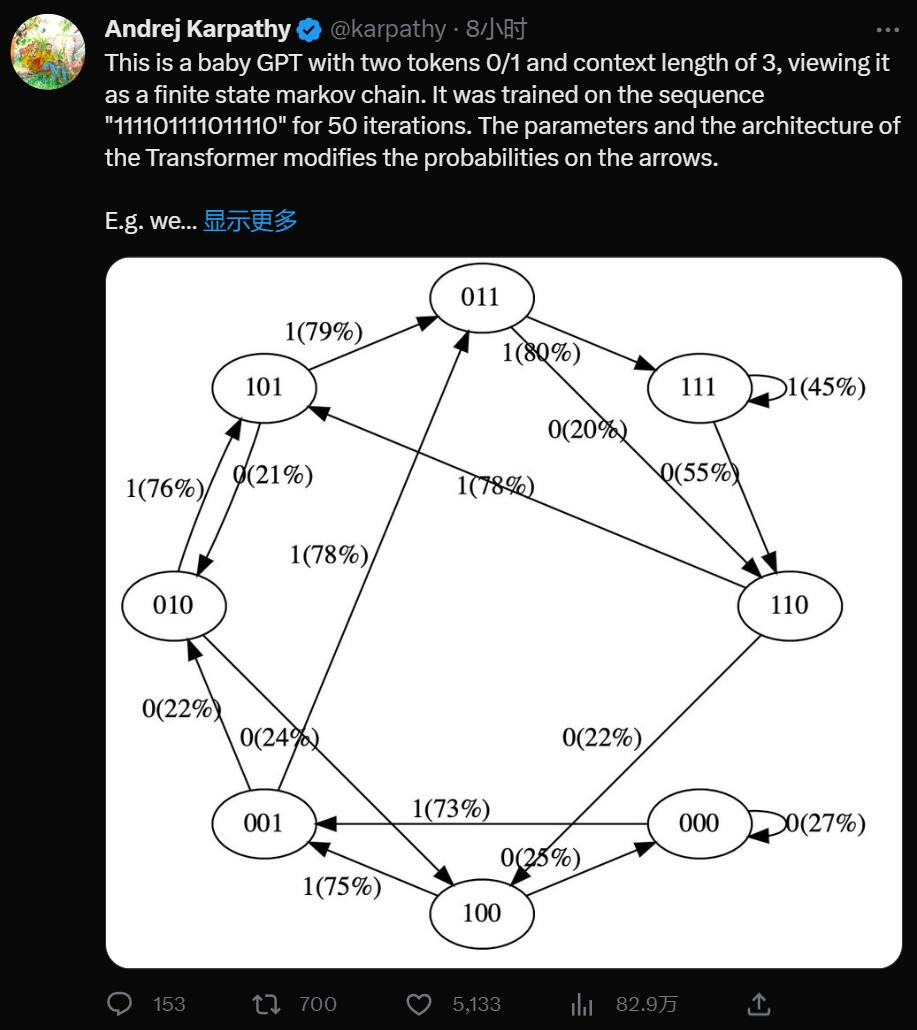
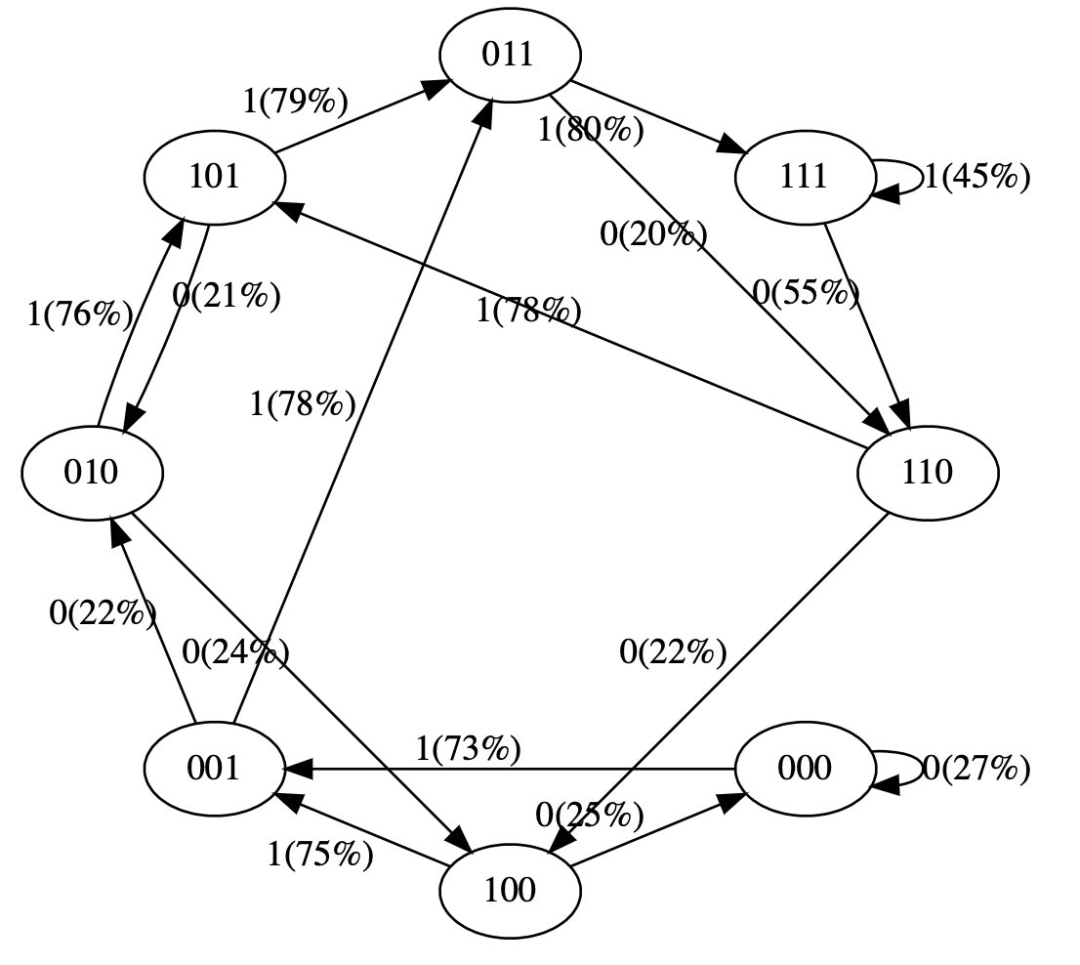
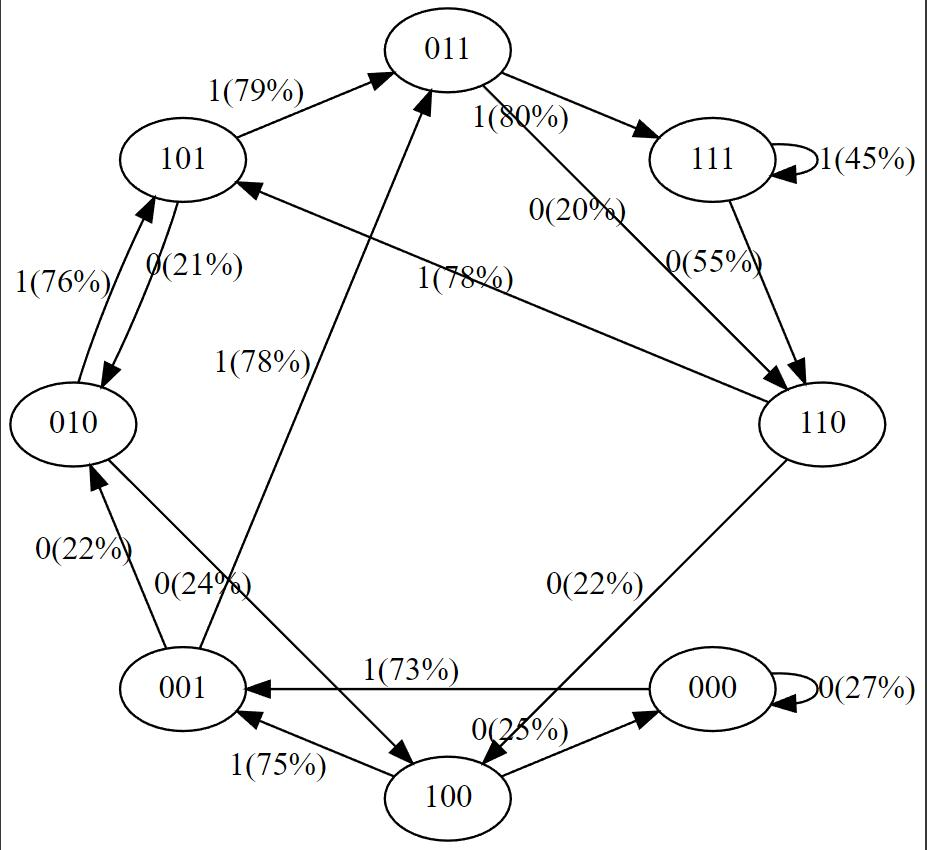
在训练数据中,状态 101 确定性地转换为 011,因此该转换的概率变得更高 (79%)。但不接近于 100%,因为这里只做了 50 步优化。 -
状态 111 以 50% 的概率分别进入 111 和 110,模型几乎已学会了(45%、55%)。 -
在训练期间从未遇到过像 000 这样的状态,但具有相对尖锐的转换概率,例如 73% 转到 001。这是 Transformer 归纳偏差的结果。你可能会想这是 50%,除了在实际部署中几乎每个输入序列都是唯一的,而不是逐字地出现在训练数据中。
[0,1,0] ---> GPT ---> [P (0) = 20%, P (1) = 80%]# hyperparameters for our GPT# vocab size is 2, so we only have two possible tokens: 0,1vocab_size = 2# context length is 3, so we take 3 bits to predict the next bit probabilitycontext_length = 3
print ('state space (for this exercise) = ', vocab_size ** context_length)# state space (for this exercise) = 8
print ('actual state space (in reality) = ', sum (vocab_size ** i for i in range (1, context_length+1)))# actual state space (in reality) = 14
config = GPTConfig (block_size = context_length,vocab_size = vocab_size,n_layer = 4,n_head = 4,n_embd = 16,bias = False,)gpt = GPT (config)
def all_possible (n, k):# return all possible lists of k elements, each in range of [0,n)if k == 0:yield []else:for i in range (n):for c in all_possible (n, k - 1):yield [i] + clist (all_possible (vocab_size, context_length))
[[0, 0, 0],[0, 0, 1],[0, 1, 0],[0, 1, 1],[1, 0, 0],[1, 0, 1],[1, 1, 0],[1, 1, 1]]
# we'll use graphviz for pretty plotting the current state of the GPTfrom graphviz import Digraphdef plot_model ():dot = Digraph (comment='Baby GPT', engine='circo')for xi in all_possible (gpt.config.vocab_size, gpt.config.block_size):# forward the GPT and get probabilities for next tokenx = torch.tensor (xi, dtype=torch.long)[None, ...] # turn the list into a torch tensor and add a batch dimensionlogits = gpt (x) # forward the gpt neural netprobs = nn.functional.softmax (logits, dim=-1) # get the probabilitiesy = probs [0].tolist () # remove the batch dimension and unpack the tensor into simple listprint (f"input {xi} ---> {y}")# also build up the transition graph for plotting latercurrent_node_signature = "".join (str (d) for d in xi)dot.node (current_node_signature)for t in range (gpt.config.vocab_size):next_node = xi [1:] + [t] # crop the context and append the next characternext_node_signature = "".join (str (d) for d in next_node)p = y [t]label=f"{t}({p*100:.0f}%)"dot.edge (current_node_signature, next_node_signature, label=label)return dotplot_model ()
input [0, 0, 0] ---> [0.4963349997997284, 0.5036649107933044]input [0, 0, 1] ---> [0.4515703618526459, 0.5484296679496765]input [0, 1, 0] ---> [0.49648362398147583, 0.5035163760185242]input [0, 1, 1] ---> [0.45181113481521606, 0.5481888651847839]input [1, 0, 0] ---> [0.4961162209510803, 0.5038837194442749]input [1, 0, 1] ---> [0.4517717957496643, 0.5482282042503357]input [1, 1, 0] ---> [0.4962802827358246, 0.5037197470664978]input [1, 1, 1] ---> [0.4520467519760132, 0.5479532480239868]
# let's train our baby GPT on this sequenceseq = list (map (int, "111101111011110"))seq
[1, 1, 1, 1, 0, 1, 1, 1, 1, 0, 1, 1, 1, 1, 0]# convert the sequence to a tensor holding all the individual examples in that sequenceX, Y = [], []# iterate over the sequence and grab every consecutive 3 bits# the correct label for what's next is the next bit at each positionfor i in range (len (seq) - context_length):X.append (seq [i:i+context_length])Y.append (seq [i+context_length])print (f"example {i+1:2d}: {X [-1]} --> {Y [-1]}")X = torch.tensor (X, dtype=torch.long)Y = torch.tensor (Y, dtype=torch.long)print (X.shape, Y.shape)
# init a GPT and the optimizertorch.manual_seed (1337)gpt = GPT (config)optimizer = torch.optim.AdamW (gpt.parameters (), lr=1e-3, weight_decay=1e-1)
# train the GPT for some number of iterationsfor i in range (50):logits = gpt (X)loss = F.cross_entropy (logits, Y)()()()print (i, loss.item ())
print ("Training data sequence, as a reminder:", seq)plot_model ()
-
GPT-2 有 50257 个 token 和 2048 个 token 的上下文长度。所以 `log2 (50,257) * 2048 = 每个状态 31,984 位 = 3,998 kB。这足以实现量变。 -
GPT-3 的上下文长度为 4096,因此需要 8kB 的内存;大约相当于 Atari 800。 -
GPT-4 最多 32K 个 token,所以大约 64kB,即 Commodore64。 -
I/O 设备:一旦开始包含连接到外部世界的输入设备,所有有限状态机分析就会崩溃。在 GPT 领域,这将是任何一种外部工具的使用,例如必应搜索能够运行检索查询以获取外部信息并将其合并为输入。

4月13日「掘金城市沙龙·北京站」限量免费参会!
从 ChatGPT 看,AI 模型服务化趋势是怎样的?AIGC 新时代下,文本智能创作面临什么样的变革?如何轻松训练 AIGC 大模型?基于大模型的 AIGC 工作原理和应用场景是什么样?
畅聊「AIGC 技术探索与应用创新」,字节跳动 NLP 算法工程师陈家泽、英特尔 AI 软件工程师杨亦诚、Google Cloud 机器学习专家王顺、清华大学 KEG 知识工程实验室研究助理郑勤铠、九合创投 COO 张少宇、稀土掘金江昪等多位业界专家已集结完毕。

登录查看更多
相关内容

Arxiv
0+阅读 · 2023年5月30日
Arxiv
0+阅读 · 2023年5月26日
Arxiv
0+阅读 · 2023年5月26日



相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2023年5月30日
Arxiv
0+阅读 · 2023年5月26日
Arxiv
0+阅读 · 2023年5月26日