

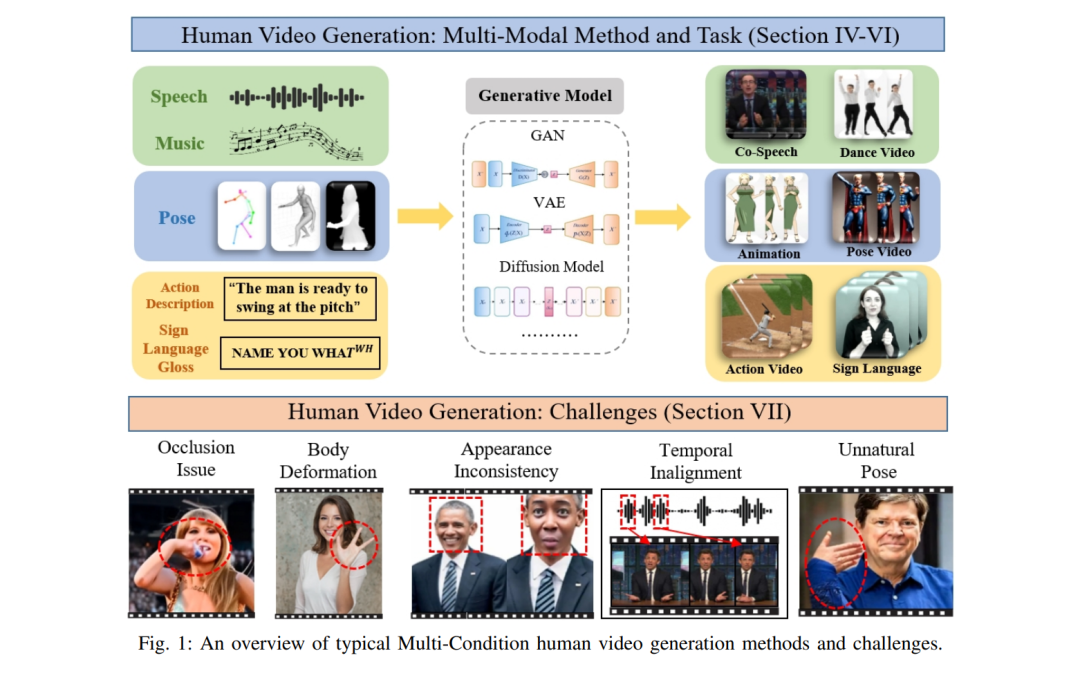
人类视频生成任务旨在通过生成模型在文本、音频和姿态等控制条件下合成自然且逼真的2D人体视频序列。这些生成的视频序列包括全身或半身人像,包含详细的身体部位和面部动作表示。最近,由于在电影制作、电子游戏、AR/VR、人机交互、数字人类和便捷人机交互等广泛应用的潜力,这一领域引起了显著关注。
最近,人类视频生成在生成方法的进展中取得了快速进步,即变分自编码器(VAE)、生成对抗网络(GAN)和扩散模型。然而,研究这样的视频合成问题被认为具有挑战性,主要有以下原因。首先,沿时间序列保持人类外观一致性是该任务中的一大障碍。其次,在合成视频中,避免人体变形是困难的,例如手指异常。第三,人类运动视频的复杂性不仅仅是面部建模,还涉及准确建模身体运动以及保持背景与身体部位的一致性和和谐。此外,人类运动生成的需求通常包括上下文作为条件,如文本描述、音频信号和姿态序列,确保与这些条件信号的时间对齐对于生成连贯且逼真的人类视频至关重要。
为应对人类视频生成的快速发展和新兴挑战,我们提供了这一领域的全面综述,帮助社区跟踪其进展。
总而言之,本综述的主要贡献有四方面:
- 我们详细界定了人类视频生成的边界,全面分析了这一领域的最新进展,并根据驱动生成过程的模态将这些进展分为三大类:文本驱动、音频驱动和姿态驱动。据我们所知,这是第一个对该领域进行系统和集中审查的综述。
- 我们通过大量相关方法和广泛的相关数据集、挑战、评估指标和商业项目,全面审查了人类视频生成中的挑战和难题。本文为读者选择适合其特定应用的基线或解决方案提供了指导。此外,我们的发现为改进当前方法提供了宝贵的见解。
- 基于我们的详细文献回顾和深入分析,我们确定了人类运动生成未来发展的几个有前途的方向。
- 我们还提供了一个持续更新的GitHub存储库,包含该领域的最新进展,以及优秀的作品和数据集的链接。我们旨在为研究社区提供最前沿的信息,并便于访问重要的研究工作、数据集和应用。详情请访问我们的存储库链接。
**
本综述组织如下。第二部分讨论了与以前综述的比较。第三部分涵盖了任务的基本原理,包括常用的数据集和评估指标。第四至第六部分分别总结了基于不同条件信号(包括文本、音频和姿态)的人类运动生成的现有方法。最后,我们在第八部分得出结论并为该领域提供见解。
成为VIP会员查看完整内容

相关内容
Arxiv
224+阅读 · 2023年4月7日

相关VIP内容
相关资讯
相关论文
Arxiv
224+阅读 · 2023年4月7日