
作者丨科技猛兽编辑丨极市平台 导读 本文将设计训练和生成策略的任务制定为一个统一的优化问题,并自动完成设计,本文方法因此称为 AutoNAT。AutoNAT 更全面地探索了 NAT 的全部潜力,而不会受到有限的先验知识的限制。
本文目录
1 AutoNAT:重新思考图像生成中的非自回归建模
(来自清华大学,新加坡国立大学) 1 AutoNAT 论文解读 1.1 AutoNAT 的诞生背景 1.2 NAT 方法简介 1.3 AutoNAT 方法:一种联合优化的框架 1.4 生成策略的优化 1.5 训练策略的优化 1.6 实验结果
太长不看版
本文研究的是图像生成的任务。目前图像生成任务的主流方案扩散模型虽然很成功,但是计算强度很大,那么需要更加高效的替代方案。Non-autoregressive Transformer (NAT) 是一种高效的,且已得到公认的方案。但是与扩散模型相比其缺点是性能较差。 因此,本文的目标是通过重新审视其训练和推理策略的设计来重新评估 NAT 的全部潜力。作者指出了现有 NAT 设计的问题,并对 NAT 的一些策略进行了深入的研究。最终的方法叫做 AutoNAT,其能够显著提高 NAT 方法的性能边界,并且能够以显着降低的推理成本与最新的扩散模型相媲美。作者在 ImageNet-256 & 512、MS-COCO 和 CC3M 这 4 个数据集上进行了验证。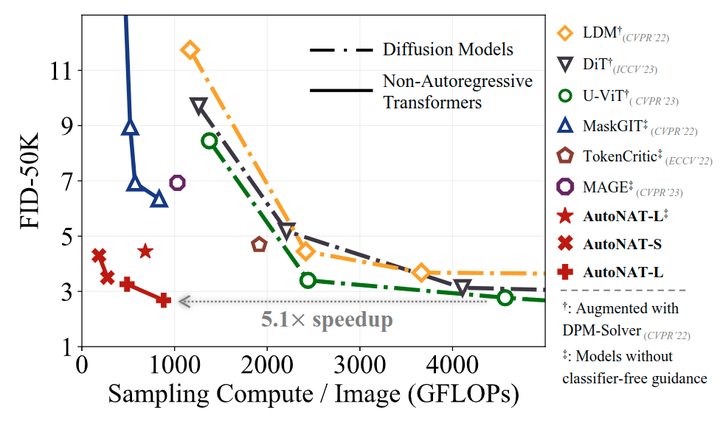
1 AutoNAT:重新思考图像生成中的非自回归建模
论文名称:Revisiting Non-Autoregressive Transformers for Efficient Image Synthesis (CVPR 2024)
论文地址:
http://arxiv.org/pdf/2406.05478 代码链接:
http://github.com/LeapLabTHU/ImprovedNAT
1.1 AutoNAT 的诞生背景
扩散模型在图像生成领域越来越受欢迎。然而,扩散模型计算密集型的迭代生成过程带来了显著的时延以及能耗。因此,目前也已经有许多研究工作来探索更加有效的替代方案。在这个背景下,Non-autoregressive Transformers (NAT)[1][2][3]是一种高效替代方案的代表。这些模型也能提供类似于扩散模型的优点,比如高可扩展性以及采样的丰富性,同时因其矢量量化 (Vector Quantized, VQ)[4][5]空间中的并行解码机制而明显更快。 如图 2 所示,NAT 从完全掩码的画布开始生成,并通过在每一步同时解码多个 tokens 来快速生成图片。生成好的 tokens 再通过一个预训练好的 pre-trained VQ-decoder[5]映射到 pixel 空间。然而,与扩散模型相比,NAT 的一个主要缺点是它们的性能较差。例如,MaskGIT[1]是一种流行的 NAT 模型,只需 8 步就可以在 ImageNet 上生成图像,FID 仅为 6.18,远远落后于最新的扩散模型[6]7。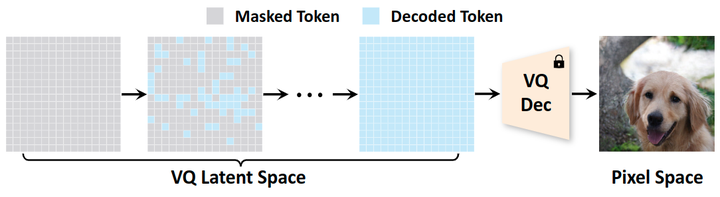
- 每一步应该解码多少 tokens?
- 应该解码哪些 token?
- 如何从 VQ codebook 中采样 token?
妥善去配置这些方面需要一个专门的 "生成策略",包括多个调度函数。而且,"训练策略" 也需要仔细去设计使得模型能够处理生成过程中遇到的不同的输入分布。因此,开发一个能够最大限度释放 NAT 潜力的合适的 "训练策略" 和 "生成策略" 是一个关键但是未被充分探索的问题。常见的做法[1]主要使用启发式驱动规则,需要大量的专家知识和劳动密集型的努力,但它仍然不是最优的。 本文则将设计训练和生成策略的任务制定为一个统一的优化问题,并自动完成设计,本文方法因此称为 AutoNAT。AutoNAT 更全面地探索了 NAT 的全部潜力,而不会受到有限的先验知识的限制。
1.2 NAT 方法简介
NAT 通常与预先训练的 VQ-autoencoder[4][5]结合使用来生成图像。VQ-autoencoder 负责图像和 latent 视觉 tokens 之间的转换,而 NAT 学习在 latent space 中生成视觉 tokens。由于 VQ-autoencoder 通常是预先训练好的,而且在生成过程中保持不变,因此这里主要介绍 NAT 的训练和生成策略。 训练策略
非自回归 Transformer 的训练基于掩码 token 建的模目标函数。具体而言,将 VQ Encoder 获得的视觉 token 表示为 ,其中 是序列长度。每个视觉 token 对应于 VQ 编码器码本的特定索引。在训练期间,随机选择 个可变数量的 tokens,并用 [MASK] token 做替换,其中 是从 范围内的预定义分布 中采样的 mask ratio。训练的目标是根据周围的 unmasked tokens 预测原始 tokens,优化交叉熵损失函数。 生成策略
非自回归 Transformer 在推理过程中, 以多步方式生成潜在的视觉 tokens。一开始的 token 序列 的所有 tokens 都是 masked。在第 步, 模型首先以并行的方式解码所有的 tokens 并从 来预测 ,然后重新屏蔽不太可靠的预测结果。
- 并行解码: 给定视觉 tokens , 模型首先并行解码所有 [MASK] tokens 以形成下一步的初步预测结果
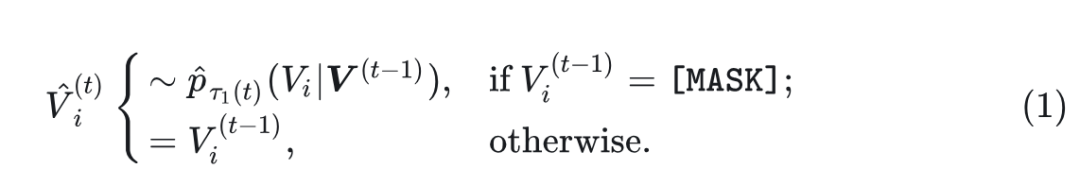
其中, 是采样温度调度函数。 表示模型在第 个位置的预测概率分布。同时, 为所有标记定义置信度分数 :
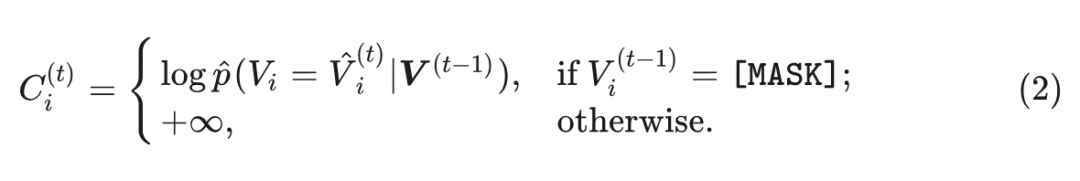
其中, 是位置 处所选 token 的预测概率。 2) 重新预测: 从初始猜测结果 , 再把 个最小置信度的 token 重新 mask 掉, 得到 :
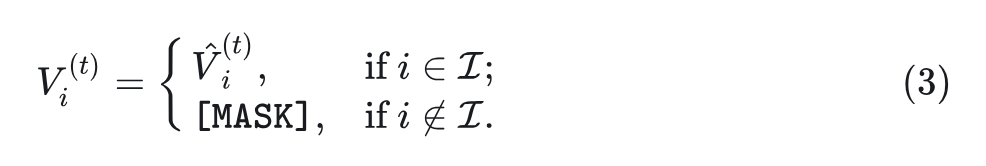
其中, 是 re-masking 的调度函数, 它在每一步调节要重新屏蔽的 tokens 的比例。集合 包括 最有信心的预测的索引, 并且在没有从 替换的情况下进行采样,其中 是 re-masking 的温度调度函数。 模型一共迭代 步, 解码所有 [MASK] tokens, 产生最终序列 ,然后将序列输入 VQdecoder 以获得图像。 NAT 方法的局限性
与其他基于似然的生成模型相比,NAT 的主要优势之一是效率高:可以用几个采样步骤生成高质量的图像。然而,这些模型通常不容易被用好,因为其性能往往严重依赖于需要仔细配置的多个调度函数。 如上所述, 生成过程通常涉及 3 个调度函数来控制掩码比 、采样温度 和 re-masking 温度 。当进一步采用 classifier-free guidance 时, 进一步引入引导尺度调度函数 以逐步调整引导强度。现有的工作通常使用启发式规则设计这些功能, 需要专业知识和手动工作。同时, 这些启发式规则可能无法捕获生成过程的最佳动态, 从而导致次优的设计。 而且,这种复杂的生成过程需要支持精心设计的训练策略。在很多工作[1][2]里, 的配置方案都是模拟 mask ratio 在生成过程中的变化,如下图 3 所示。但是这种常见的设计可能并不合适。图 4 中的违反直觉的发现表明,即使使用单个固定 mask ratio 也可以产生比启发式设计更好的结果。一种可能的解释是,从一个 mask ratio 解码中学习到的能力有更好的迁移性能,用于解码其他 mask ratio。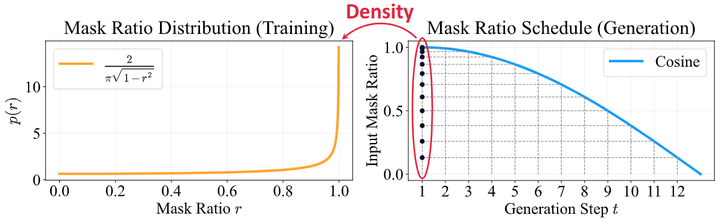
1.3 AutoNAT 方法:一种联合优化的框架
如前文所述,非自回归生成模型启发式的训练和生成策略既费力而且是次优的。为了解决这个问题,本文提出了一种基于优化的方法,推导出这些最佳配置,如下图 5 所示。
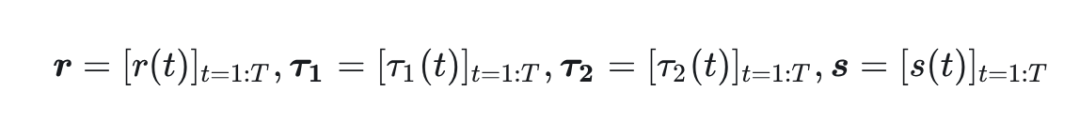
来规避直接优化函数的难度。形式上,这个优化问题可以定义为:
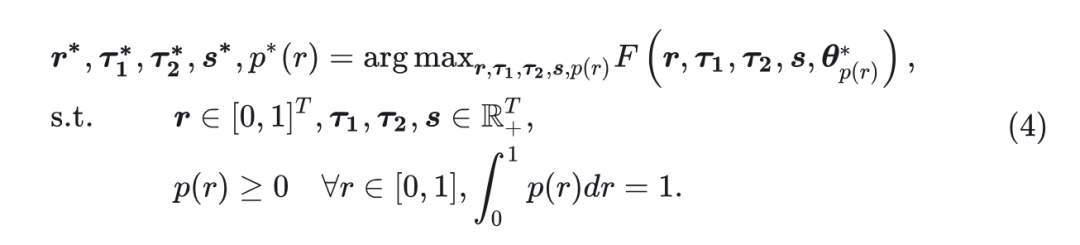
式中, 表示在 mask ratio distribution 训练的模型参数。函数 衡量生成质量, 比如 FID, IS 指标等。此外, 对 的约束确保了它是一个有效的概率分布。 交替优化
在解决优化问题之前, 注意到 和其他变量之间的一个重要区别: 嵌套在模型参数项 中。直接同时解决所有变量将是低效的, 因为 的评估需要使用 训练模型并评估 有多好, 比较慢, 阻碍了其他变量的优化。 受到这种不平衡性的启发,本文将优化问题分为两个子问题:生成策略优化和训练策略优化,并提出交替算法。 第1个子问题 [生成策略优化]:在给定 下训练的模型的情况下,获得控制生成过程 的超参数的最佳配置。 第 2 个子问题 [训练策略优化]:使用给定的生成配置优化 。 这两个子问题交替求解,直到模型的生成质量收敛,这种方法可以通过更好的效率来解决整体优化问题。 下图 6 是整体的优化过程。下文中分别阐述了生成策略和训练策略的优化。
1.4 生成策略的优化
生成策略的优化指的是在给定固定 的情况下搜索最优生成策略变量 。
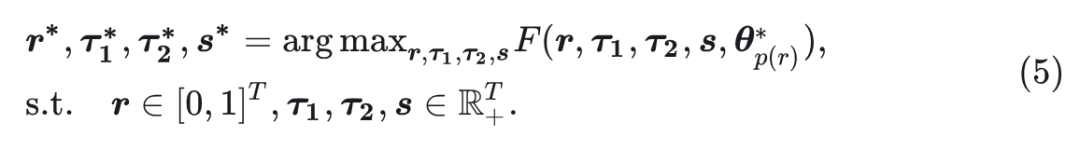
作者发现这个子问题可以通过简单的梯度下降有效地解决。具体而言, 尽管由于并行解码过程, 相对于 而言都是不可微的, 但通过利用有限差分方法来近似每个变量对应的梯度是可行的。令 为变量的级联。 相对于 的梯度可以近似为:
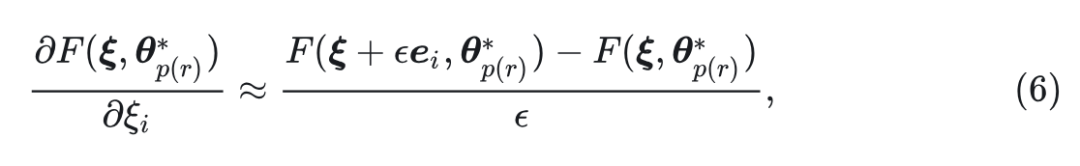
式中, 在 的维度范围, 是 方向上的单位向量, 是一个小的正数。将估计的梯度表示为 , 然后可以通过梯度下降更新超参数:
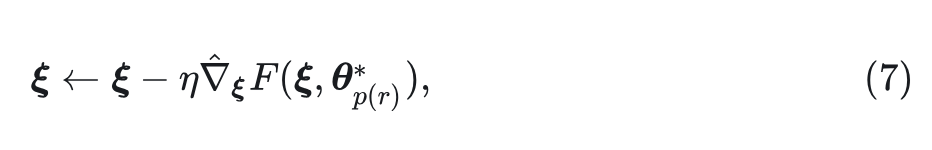
其中, 是学习率。
1.5 训练策略的优化
训练策略的优化指的是使用给定的生成策略变量 搜索最佳的掩码比分布 。由于通常需要训练模型来评估 的任何候选值, 因此在概率分布空间中优化 在计算上很昂贵。因此, 作者将 限制为特定的概率密度函数族。本文采用 Beta 分布作为 家族:
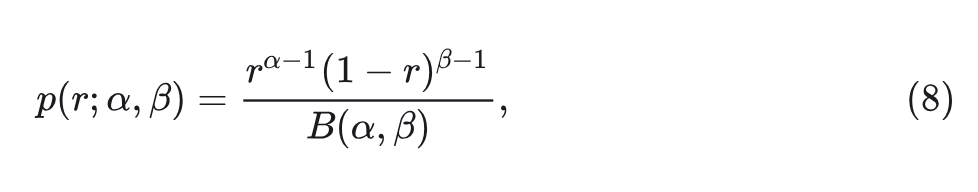
式中, 是 Beta 函数, 。因此, 可以将优化问题简化为:

有了这个假设,作者发现使用简单的 Greedy Search[9]就可以有效得到。具体来说,首先执行行搜索来优化一个参数,同时保持另一个固定。一旦找到了第 1 个参数的最佳值,就切换到第 2 个参数并再次进行线搜索以找到其最优值。这种优化一直持续到性能指标没有进一步改进。
1.6 实验结果
作者使用 VQGAN,codebook size 为 1024 来执行图像和 visual token 的转化。本文模型架构遵循 U-ViT[6],这是一种适用于图像生成任务的 Transformer。考虑 2 种模型配置:Small 模型 (13 层,512 dimension,表示为 AutoNAT-S) 和 Large 模型 (25 层,768 dimension,表示为 AutoNAT-L)。数据集 ImageNet-512,作者采用 Patch Size 为 2 来适应增加的 token 数。在 AutoNAT 的实现中,首先采用小模型并在 ImageNet-256 (T = 4) 上进行交替优化以获得基本训练和生成策略,利用 FID 作为默认评估指标。 Class-Condition 图像生成结果
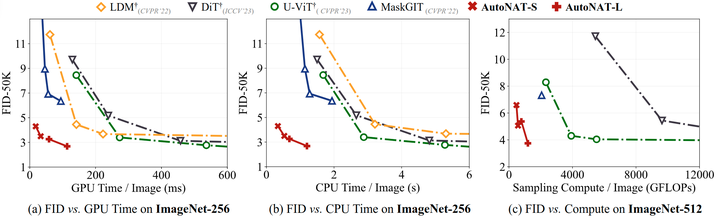
如下图 7 所示,作者在 ImageNet 256×256 和 ImageNet 512×512 上对比了本文方法与其他生成模型。图中报告了 generation steps,模型参数量,以及生成过程中的总计算量,以对于性能和效率进行全面的评估。结果表明,AutoNAT-S 虽然比其他基线的参数明显少,但在 ImageNet-256 上产生了极具竞争力的性能。比如,AutoNAT-S 只需要 0.2 TFLOPs 和 4 个 generation steps 就实现了 4.30 的 FID。进一步将计算量增加到 0.3 TFLOPs,AutoNAT-S 的 FID 进一步提高到了 3.52,超过了大多数基线。较大的 AutoNAT 继续这一趋势,以 8 个 generation steps 获得 2.68 的 FID。在 ImageNet-512 上,最好的模型实现了 3.74 的 FID,超过了其他最先进的模型,同时显著减少了计算资源。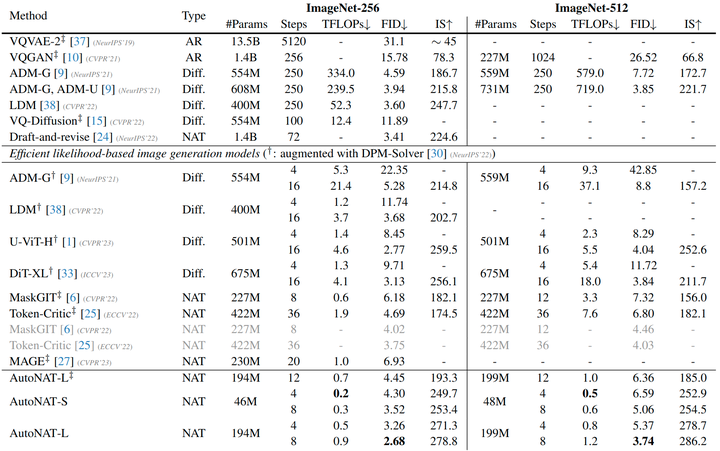
实验结果如图 9 所示,AutoNAT-S 能够以最小的 0.3 TFLOPs 计算优于其他基线,并实现了 5.36 的 FID 提升,表明其卓越的效率和有效性。与配备快速采样器的扩散模型 U-ViT 相比,AutoNAT-S 超过了其 50-step 的采样结果,同时计算成本降低了 7 倍,并且在计算资源相近的情况下大大优于它。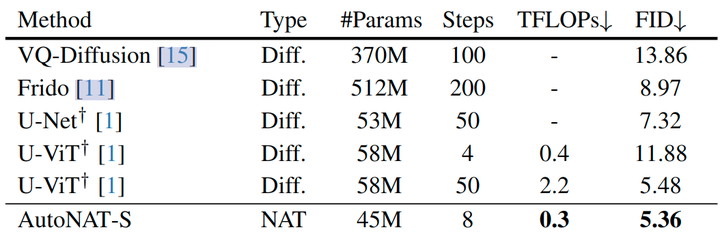
实验结果如图 10 所示,作者验证了 AutoNAT 在更大 CC3M 数据集上文生图任务的有效性。作者将 AutoNAT 应用于预训练的 Muse[2]模型,并且只优化生成策略。结果显示,将本文优化策略与 Muse 模型相结合,在 CC3M 上产生了 6.90 的 FID,显着超过了其他基线。与普通 Muse 模型相比,AutoNAT 在使用其一半的计算成本时性能就已经更优,并且在使用相同的计算资源时实现了更好的 FID (6.90 vs. 7.67)。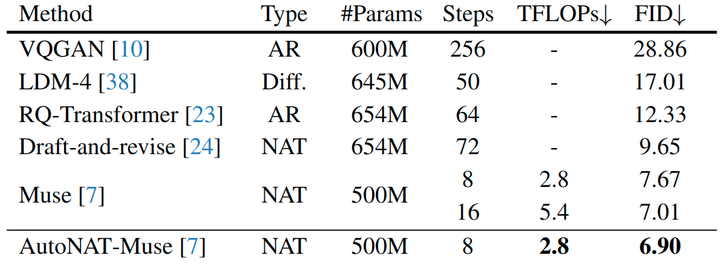
- ^abcdMaskgit: Masked generative image transformer.
- ^abcdMuse: Textto-image generation via masked generative transformers.
- ^Mage: Masked generative encoder to unify representation learning and image synthesis.
- ^abNeural Discrete Representation Learning
- ^abcTaming Transformers for High-Resolution Image Synthesis
- ^abAll are Worth Words: a ViT Backbone for Score-based Diffusion Models
- ^Scalable Diffusion Models with Transformers
- ^Diffusion Models Beat GANs on Image Synthesis
- ^Convex Optimization