

本文目录
1 序列建模打造大视觉模型
(来自 UCB,Johns Hopkins University) 1 LVM 论文解读 1.1 大视觉模型的特点是什么? 1.2 LVM 数据集 1.3 LVM 方法1:视觉 tokenizer 1.4 LVM 方法2:自回归 Transformer 模型 1.5 LVM 方法3:推理过程 1.6 LVM 评测1:缩放性 1.7 LVM 评测2:序列提示 1.8 LVM 评测3:类比提示 1.9 LVM 评测4:杂项提示
太长不看版
本文的首发日期是 2023.12,属于大视觉模型的开山之作行列。本文提出一种序列建模 (sequential modeling) 的方法,不使用任何语言数据,训练大视觉模型 (Large Vision Model, LVM)。 作者定义了一种 "视觉句子 (Visual Sentences)",它可以用于表征图像,视频,语义分割和深度重建,同时只需要像素信息。作者构造了一个包含 420B tokens 的数据集,通过 Next Token Prediction 和交叉熵损失来训练大视觉模型。 最后得到的模型具有对于数据规模和模型容量很好的缩放性。而且在测试时通过设计合适的视觉提示,可以拿来解决许多不同的视觉任务。
本文的结论有哪些
随着数据量和模型容量的增加,展示出缩放性质。 通过在测试时设计合适的提示来 "解决许多不同的视觉任务"。虽然结果不像定制、专门训练的模型那样表现出高性能,但单个视觉模型都解决了如此多的任务这一事实非常令人鼓舞。 作者发现无监督数据量对各种标准视觉任务的性能有明显的好处。 作者看到了通用视觉推理能力的痕迹,即处理分布外数据并执行新任务。但是这一点需要进一步研究。
1 序列建模:大视觉模型的先驱
论文名称:Sequential Modeling Enables Scalable Learning for Large Vision Models (CVPR 2024)
**论文地址:**http://arxiv.org/pdf/2312.00785.pdf
1.1 大视觉模型的特点是什么?
GPT 和 LLaMA 等大型语言模型 (LLM) 已经席卷了世界。构建大视觉模型 (Large Vision Model, LVM) 需要什么?
在动物的世界里,我们都知道视觉能力不依赖于语言。许多实验表明,非人类灵长类动物的视觉世界与人类的视觉世界非常相似。因此,虽然 LLaVA[1]等视觉语言模型很有趣,但是本文从纯视觉像素的角度进行探索:我们仅仅依赖视觉像素可以走多远?
本文作者从当代的 LLM 中寻找一些关键的特征来制作 LVM 模型,找了2个关键特征:
- Scalability: 对于大数据集的可扩展性。
- Prompting: 通过提示 (in-context learning) 来灵活地适配下游任务。
为了实现这2个特征,作者指出了3个关键组件:
- 数据: 作者希望利用好视觉数据的多样性。首先,要使用不带标注的图像和视频。接下来,作者希望利用 semantic segmentations, depth reconstructions, keypoints, multiple views of 3D objects 等等这些在过去几十年里生产了不少的数据。作者定义了一种通用的数据格式 "视觉句子 (Visual Sentences)",它可以在无需标注的情况下,用于表示这些不同的数据。本文的训练数据集大小为 1.64B 个 images/frames。
- 架构: 使用一个在视觉数据上训练的大 Transformer 架构 (3B 参数量)。使用一个预训练的 tokenizer 将图片映射成 256 个离散向量 tokens。
- 损失函数: 从 LLM 中获得灵感,采用序列自回归预测的损失函数。因为 images/videos/annotated images 都可以视为 tokens 序列,因此以最小化交叉熵损失来预测下一个令牌作为损失函数。
1.2 LVM 数据集
任何大的预训练模型的一个关键要求就是它必须在大规模数据集上进行训练。对于语言模型,我们可以很轻易地获得非常大且不同的数据集。比如,流行的 Common Crawl[2]存储库包含跨越整个 Web 的 250 亿个网页,非常多样化,并且自然地包含有一些演示,像语言翻译,问答等等的数据。 在计算机视觉中,我们仍然远未拥有相当大小和多样性的数据源。本文工作的核心贡献是策划这样一个数据集的第一版,作者称之为统一视觉数据集 (Unified Vision Dataset v1, UVDV1)。作者利用了许多不同的视觉数据来源:
- 无标注图片 (unlabelled images)
- 带有视觉标注的图片 (images with visual annotations)
- 无标注视频 (unlabelled videos)
- 带有视觉标注的视频 (videos with visual annotations)
- 3D 合成数据 (3D synthetic objects)
无标注图片占总数据量的 80%,以较低质量为代价提供了较丰富的多样性。带有注释的图像具有更多的约束分布,但通常质量更高。视频数据更受约束 (因为通常以人为为中心),但是时间数据的宝贵来源。3D合成对象的渲染多样性最低,但可以提供关于3D结构行为的提示。UVDV1 是一个纯视觉数据集,不包含非视觉数据 (比如文本)。UVDV1 包含 1640 亿张图像。 与 LLM 的另一个重要的区别是,文本数据都有一个自然、统一的一维结构,即文本流。但是视觉数据并非如此。不同的数据来源都具有不同的结构。因此,本文提出 "视觉句子 (Visual Sentences)" 作为统一的视觉数据单元。这个好处就是便于作者把不同来源,不同特点的数据给集合起来,用于训练视觉模型。Visual Sentences 指的是包含一张或多张图片的序列,并以 End-Of-Sentence (EOS) token 作结尾。
如下图1所示是如何将各种数据源划分为 Visual Sentences。图2是本文数据集的具体组成。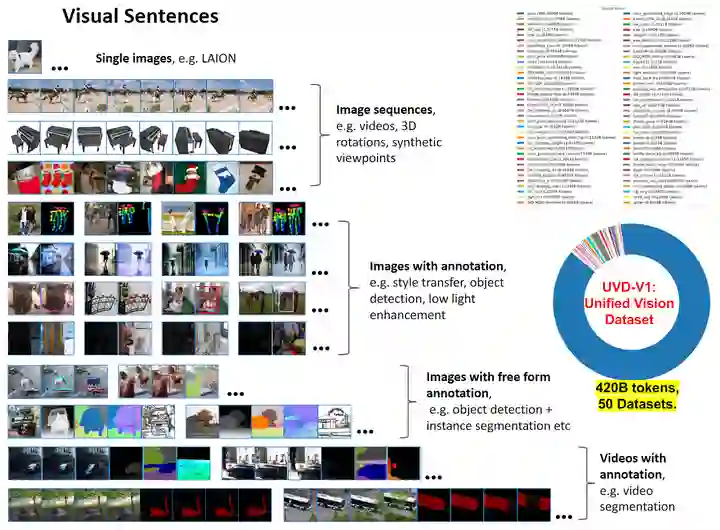

- 目标检测:通过在每个对象周围覆盖一个颜色编码的边界框来创建注释。
- 人体姿态:人体骨骼在像素空间中渲染,遵循 OpenPose 的格式。
- 深度估计,曲面法线和边缘检测:给定 ImageNet 和 COCO 图像,根据特定的协议[6]生成注释。
- 风格迁移,降噪,去雨,低光照图像增强和立体声数据集:这些都被表示为输入和输出的图像对。
- 着色:作者将 ImageNet 图像转换为灰度,生成图像对。
- 修复:在图像中随机添加黑色方框以模拟损坏,从而产生图像对。 对于以上所有的注释类型,作者通过将相同注释类型的 8 个图像对连接,成为一个包含 16 个图像的 Visual Sentence。 对于一张图片有 个不同注释的图片采用不同的方法:对这组的 个图片, 随机采用 个样本,其中 。用这 个样本来构建 Visual Sentence。 带有注释的图像序列: 当将带注释的视频数据 (VIPSeg、Hand14K、AVA、JHMDB) 转换为 Visual Sentence 时,作者应用了两种互补的策略。 第1种是连接帧及其对应的注释:{frame1,annot1,frame2,annot2,...}。 第2种是连接所有的帧,并把注释排列在其后面:{frame1,frame2,annot1,annot2,...}。
1.3 LVM 方法1:视觉 tokenizer
不像文本数据能够自然地表现出离散的结构,视觉句子中对图像像素进行建模其实并不简单。本文的方法包含2步:
- 训练一个大型视觉 tokenizer (对单个图像进行操作),将每个图像转换为一系列视觉 tokens。这步类似于 NLP 中的 tokenizer。
- 在 Visual Sentence 数据集上训练一个自回归的 Transformer 模型。数据集中的每张图片都表示为一系列视觉 tokens。
虽然图像与图像之间有人为的序列结构,但是图像结构内部并不包含天然的序列结构。因此,为了将 Transformer 模型应用到图像中,一般有下面两种方式:
- ViT:把图片分成 Patch,按照扫描线顺序排成一排序列。
- VQVAE[7] 或者 VQGAN[8]:将图像特征聚类成离散的 tokens,再按照扫描线顺序排成一排序列。
在本文中,作者使用 VQGAN[8]中的 Encoder 来把图像转化成 tokens。VQGAN 由 Encoder 和 Decoder 组成,而且具有量化层,通过自己建立的 codebook 将输入图像变为离散的 token 序列。Encoder 和 Decoder 全部使用卷积层组成。Encoder 由几个下采样模块组成,以收缩输入的空间维度。Decoder 由等效的上采样模块组成,用于将图像恢复到其初始大小。对于给定的图像,本文使用的 VQGAN tokenizer 产生 256 个离散 tokens。 需要注意的是,本文使用的 VQGAN tokenizer 独立地对单个图像进行操作,而不是一次对整个 Visual Sentence 进行操作。这样的独立性使我们能够将 tokenizer 训练与下游 Transformer 模型解耦,以便 tokenizer 可以在单个图像数据集上进行训练,而无需考虑 Visual Sentence 的分布。 作者采用的 VQGAN 架构来自[9]。下采样率 ,codebook 大小 8192。这意味着对于大小为 256×256 的图像,VQGAN 分词器产生 16×16 = 256 个 tokens,其中每个 token 都可以取 8192 个不同的值。 作者在 LAION 5B 数据集的 1.5B 子集上训练本文的 VQGAN 分词器。
1.4 LVM 方法2:自回归 Transformer 模型
在使用 VQGAN 将图像转换为离散的 tokens 后,作者将来自多个图像的离散标记连接成1个一维序列,将 Visual Sentence 视为一个统一的序列。作者使用交叉熵损失,和 Next Sentence Prediction 的目标训练一个 casual Transformer 模型。 在所有视觉句子上训练模型,使模型能够从上下文中推断出图像之间的关系,而不是从特定于任务的标记或特定于格式的标记中推断出来。这使模型能够泛化到其他看不见的 Visual Sentences。 本文使用的 Transformer 模型与自回归语言模型几乎相同,因此作者采用 LLaMA 的架构。上下文长度使用 4096,这样可以使用分词器容纳下 16 张图片。与语言模型类似,作者在每个视觉句子的开头添加一个 [BOS] (begin of sentence) token,最后添加一个 [EOS] (end of sentence) token。 在整个 UVDv1 数据集 (420 亿个标记) 上训练模型 1Epoch。模型大小有 300M, 600M, 1B 和 3B 这四种。详细的架构如图3所示。 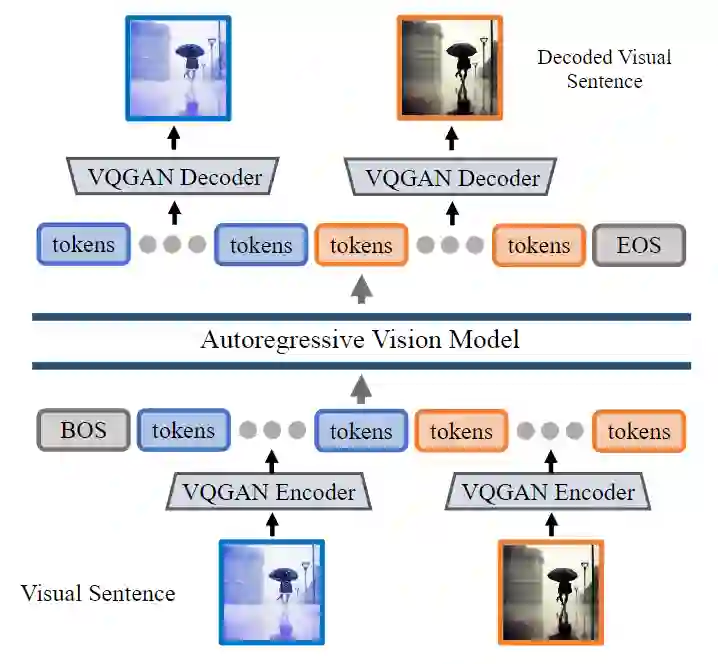
1.5 LVM 方法3:推理过程
由于自回归 Transformer 输出下一个 token 的概率分布,因此可以很容易地从这个分布中采样以生成新的 tokens。为了将模型用于下游任务,可以在测试时构建一个定义任务的 Visual Sentence 的一部分,并应用模型生成输出。这类似于语言模型中的 in-context learning[10]或计算机视觉中的 visual prompting[11]。
1.6 LVM 评测1:缩放性
对验证集损失的缩放性
如下图4所示是不同参数大小的 LVM 训练损失。由于所有的模型都只训练 1 Epoch,因此模型只看到给定的数据样本1次,因此训练期间任何点的训练损失与验证集损失很像。可以观察到,随着训练的进行:
- 模型的训练损失,无论其大小如何,都会逐步减少。
- 随着模型的大小的增加,损失下降得更快。
这些观察结果表明,LVM 在更大模型和更多数据方面表现出强大的缩放性。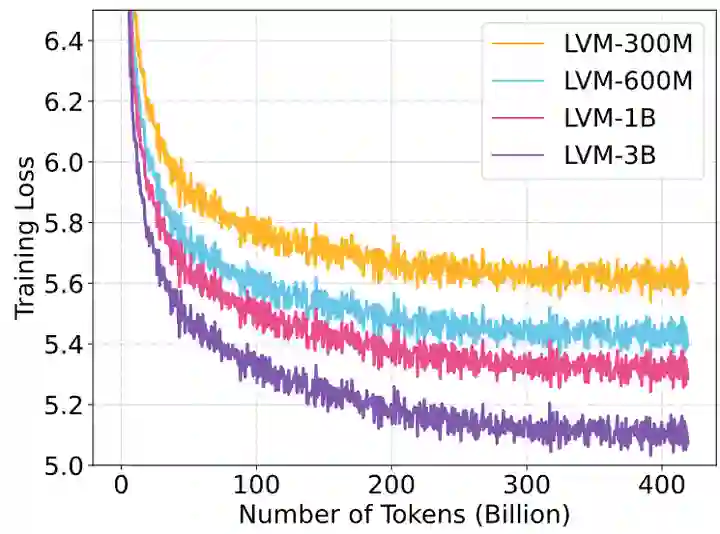
对下游任务的缩放性
作者在 4 个下游任务上评估不同大小的模型:语义分割 (semantic segmentation)、深度估计 (depth estimation)、表面法线估计 (surface normal estimation) 和边缘检测 (edge detection)。作者在 ImageNet 验证集上评估这些任务,并使用1.2节所描述的相应方法生成注释。对于每个任务给出5对 (输入,对应的 GT 注释) 以及查询图像作为输入,并使用 LVM 模型预测下 256 个 tokens (对应一张图片) 下评估困惑度。 实验结果如下图5所示,可以看到更大的模型确实在所有任务中获得了较低的困惑度,表明 LVM 对于下游任务的缩放性。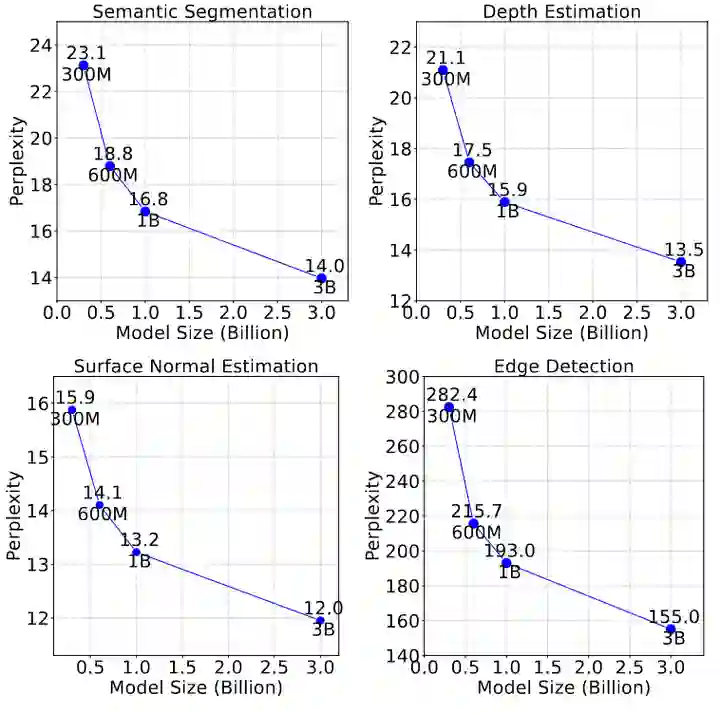
对数据集的缩放性
作者在 UVDv1 数据集的子集上训练几个 3B 模型,并比较它们在下游任务上的表现,以探究数据集缩放性对 LVM 的影响。实验结果如下图6所示,可以观察到每个数据组件都对下游任务做出了积极贡献。LVM 不仅受益于更大的数据,而且性能随着数据集的多样性逐步提升。 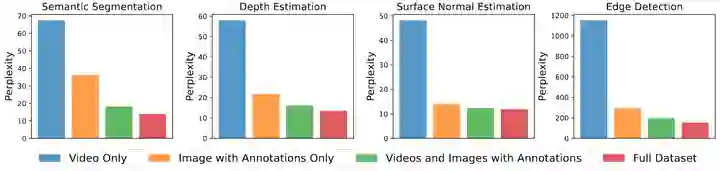
1.7 LVM 评测2:序列提示
给模型传入 7 images 的序列,并要求其输出下一张图片 (256 tokens)。如下图7所示是视频预测任务的结果,是一些下一帧预测的示例。它的 prompt 来自于 Kinetics-700 的验证集。蓝色边框是7帧的 Prompts,红色边框生成的预测结果。可以观察到空间定位、视点和对象理解的一定程度的推理能力。Kinetics-700 验证集上预测的困惑度为 49.8。最后 4 行显示了使用较长上下文 (15 帧) 和较长预测 (4 帧) 的预测。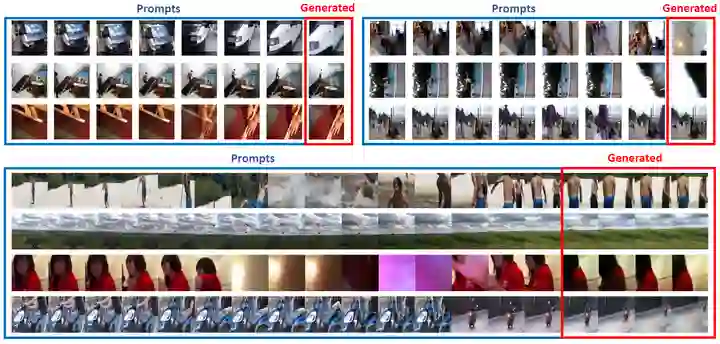
1.8 LVM 评测3:类比提示
这一节作者评估了更加复杂的提示结构。这种方法挑战模型理解任意长度的类比和复杂性,从而测试其高级解释能力。实验结果如图8所示。Prompt 由 14 张图像组成,给出各种任务的示例,然后是第 15 个查询图像。顶部是 In distribution 实验结果,意思是 Prompts 是训练集一部分 (但这些图像实际在训练中从未见过)。底部是 Out of distribution 实验结果,意思是 Prompts 这些图泛化到训练中没有见过的任务。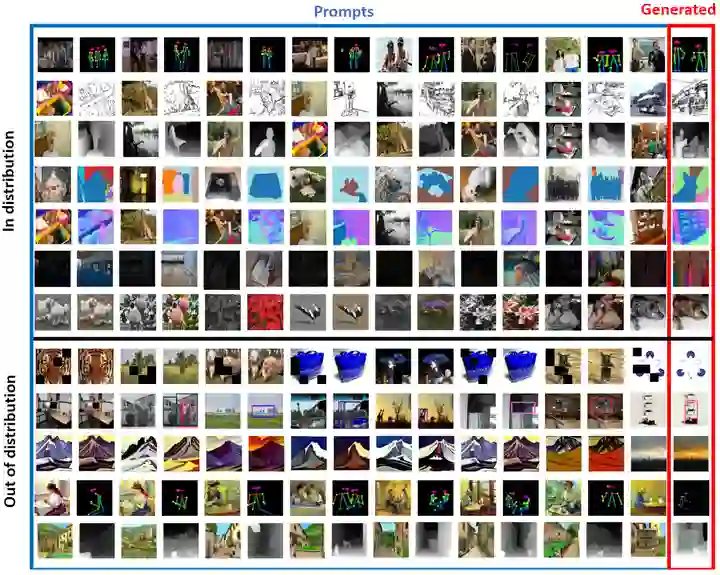
1.9 LVM 评测4:杂项提示
图9是各种简单的视觉任务,例如对象复制、重新照明和放大的实验结果。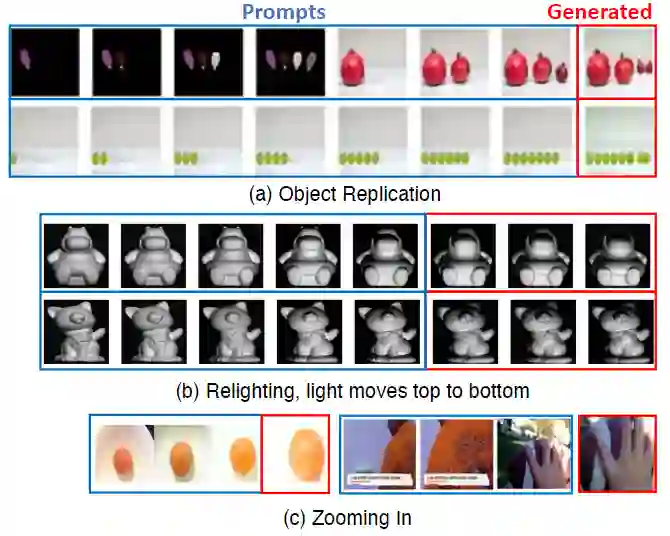

参考
- ^Visual Instruction Tuning
- ^https://commoncrawl.org/
- ^LAION-5B: An open large-scale dataset for training next generation image-text models
- ^On the De-duplication of LAION-2B
- ^Objaverse: A Universe of Annotated 3D Objects
- ^Prismer: A Vision-Language Model with An Ensemble of Experts
- ^Neural Discrete Representation Learning
- ^abTaming Transformers for High-Resolution Image Synthesis
- ^MaskGIT: Masked Generative Image Transformer
- ^Language Models are Few-Shot Learners
- ^Visual Prompting via Image Inpainting
- ^STANDARDIZATION OF PROGRESSIVE MATRICES, 1938
