
摘要
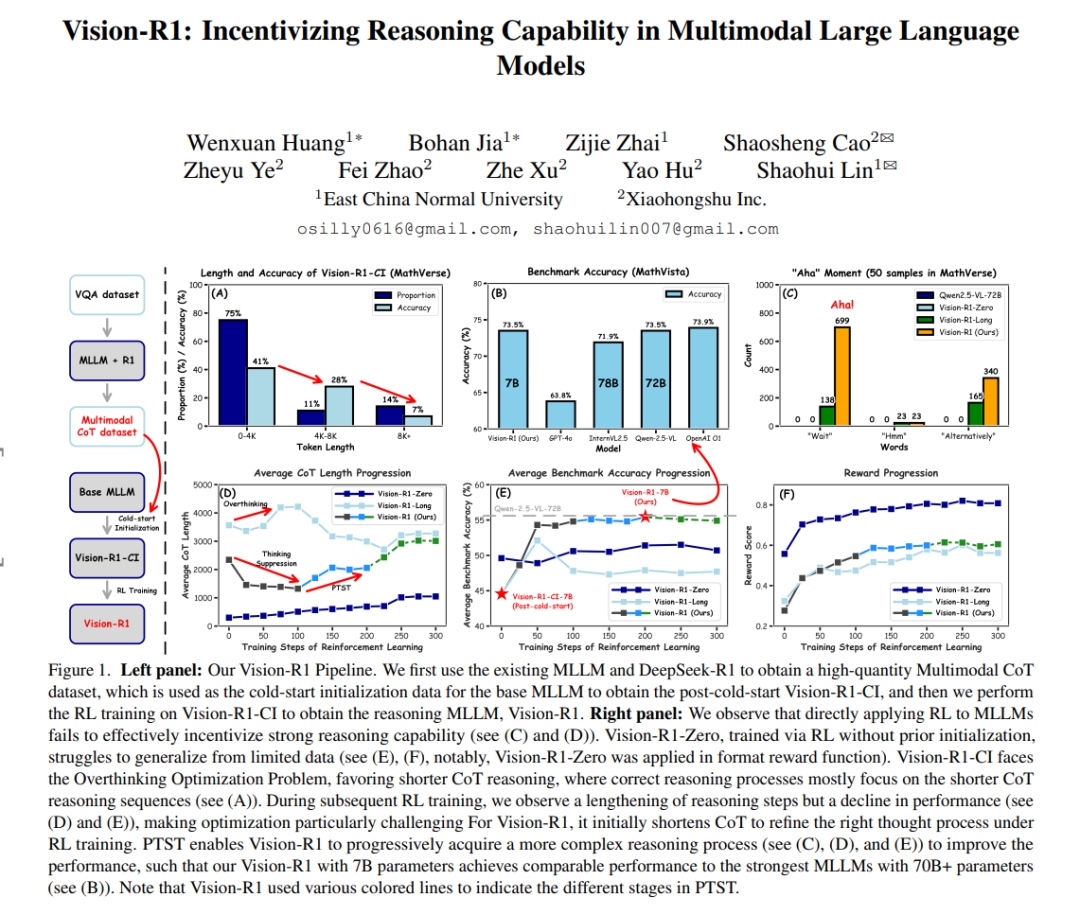
DeepSeek-R1-Zero 已成功展示了通过纯强化学习(RL)在大语言模型(LLMs)中涌现出推理能力。受这一突破的启发,我们探索了如何利用 RL 来增强多模态大语言模型(MLLMs)的推理能力。然而,由于缺乏高质量的多模态推理数据,直接使用 RL 训练难以激活 MLLMs 中的复杂推理能力,例如质疑和反思。为了解决这一问题,我们提出了推理型 MLLM——Vision-R1,以提升多模态推理能力。具体而言,我们首先通过利用现有的 MLLM 和 DeepSeek-R1,通过模态桥接和数据过滤构建了一个无需人工标注的高质量多模态思维链(CoT)数据集,即 Vision-R1-cold 数据集(包含 20 万条多模态 CoT 数据),作为 Vision-R1 的冷启动初始化数据。为了缓解冷启动后因“过度思考”导致的优化挑战,我们提出了渐进式思维抑制训练(PTST)策略,并结合硬格式化结果奖励函数使用组相对策略优化(GRPO),在 10K 多模态数学数据集上逐步优化模型学习正确且复杂推理过程的能力。综合实验表明,我们的模型在各种多模态数学推理基准测试中平均提升了约 6%。Vision-R1-7B 在广泛使用的 MathVista 基准测试中达到了 73.5% 的准确率,仅比领先的推理模型 OpenAI O1 低 0.4%。数据集和代码将发布在:https://github.com/Osilly/Vision-R1。 1. 引言
提升大语言模型(LLMs)的复杂推理能力仍然是人工智能(AI)领域最具挑战性的问题之一,这被广泛认为是实现通用人工智能(AGI)的关键途径[1, 2]。传统的推理范式通常依赖于简单的“直接预测”方法生成简洁的最终答案,而没有明确、结构化的中间推理步骤,这在复杂推理任务中往往表现欠佳[1]。OpenAI O1[1] 是首个通过使用复杂思维链(CoT)进行训练以实现显著性能提升的 LLM。与此同时,多种方法[3–14]被探索用于生成高质量的复杂 CoT 推理,并通过优化推理路径进一步推动该领域的发展。 在多模态大语言模型(MLLMs)领域,最近的研究[15, 16]也探索了 CoT 推理的应用。这些方法假设 MLLMs 缺乏结构化的推理过程,因此在需要逻辑推理的任务中表现不佳。为了提升 MLLMs 的推理能力,一些方法[15, 17]尝试手动构建包含步骤级推理过程的数据集,并应用监督微调(SFT)来重新格式化 MLLMs 的输出。然而,这种手动设计的“格式化推理 MLLM”通常会导致“伪 CoT”推理,缺乏人类思维中常见的认知过程,例如质疑、反思和检查(见图 2,“伪 CoT”和复杂 CoT 的数据示例)。这一限制阻碍了其在复杂视觉推理任务中的应用。因此,生成类人的高质量复杂 CoT 推理数据以训练 MLLMs,使其更有效地处理复杂的多模态推理任务,具有重要意义。 最近,DeepSeek-R1[2] 成功应用强化学习(RL)诱导 LLMs 中复杂认知推理能力的自我涌现。这引发了我们的思考:RL 能否用于激励 MLLMs 的推理能力?为了回答这个问题,我们首先遵循 DeepSeek-R1-Zero 范式[2],直接使用 RL 来提升 MLLMs 的推理能力。然而,这种直接的 RL 训练面临挑战,因为在缺乏大规模高质量多模态数据和长时间训练的情况下,难以有效引导 MLLMs 生成复杂的 CoT 推理(见图 1 (E) 和 (F))。 为了解决上述问题,我们提出了 Vision-R1,一种结合冷启动初始化和 RL 训练的推理型 MLLM。首先,我们构建了一个无需人工标注的高质量多模态 CoT 数据集。具体而言,我们利用现有的 MLLM 从多模态图像-文本对中生成“伪 CoT”推理文本。这种“伪 CoT”推理明确结合了视觉描述和结构化的步骤级推理过程,以文本形式呈现更详细的视觉信息。接下来,我们将增强后的推理文本反馈到 MLLM 中,以获得包含必要视觉信息的描述。这一过程有效实现了“模态桥接”,将视觉信息转换为语言。生成的文本描述随后被传递到仅文本推理的 LLM——DeepSeek-R1,以提取高质量的 CoT 推理。最后,通过基于规则的数据过滤对数据集进行优化,最终获得包含 20 万条多模态类人复杂 CoT 推理样本的数据集,作为 Vision-R1 的冷启动初始化数据集。 遵循 DeepSeek-R1 的训练流程,我们需要在 10K 多模态数学数据集上应用组相对策略优化(GRPO)[2, 18] 以增强模型的推理能力。然而,如图 1 (A) 和 (D) 所示,我们观察到冷启动初始化的 MLLM 中存在“过度思考”现象,即正确的推理过程往往集中在较短的 CoT 推理序列上。这一问题导致后续 RL 训练中的优化困难。为了解决这一挑战,我们提出了渐进式思维抑制训练(PTST)并结合 GRPO,采用硬格式化结果奖励函数。这种方法鼓励 Vision-R1 在 RL 过程的早期压缩 CoT 推理步骤,内化正确的推理方法,同时逐步延长其推理时间以有效解决更复杂的问题。 我们的主要贡献总结如下: * 我们探索了如何将 RL 应用于 MLLMs,并提出了 Vision-R1,一种通过冷启动初始化和 RL 训练激励推理能力的推理型 MLLM。据我们所知,这是首个研究 RL 在增强 MLLMs 推理能力中的应用,并分析直接 RL 训练与冷启动初始化结合 RL 训练之间差异的工作。我们相信这一探索能为社区带来新的启发。 * 构建了一个无需人工标注的高质量 20 万条多模态 CoT 数据集,作为 MLLMs 的冷启动初始化数据。我们提出的 PTST 结合 GRPO 和硬格式化结果奖励函数,有效解决了 RL 训练中的“过度思考”优化问题。PTST 使 Vision-R1 逐步发展出更复杂的推理过程,同时有效引导 MLLMs 提升推理能力。 * 大量实验证明了 Vision-R1 的强大推理能力。值得注意的是,尽管 Vision-R1 仅有 70 亿参数,但在数学推理任务中的表现可与超过 700 亿参数的最先进(SoTA)MLLMs 相媲美。