
桑基韬 北京交通大学教授
**目录****引言 **趋势一:从专用到通用-预训练大模型和智能代理
(1)预训练语言模型 (2)视觉和多模态预训练 (3)预训练模型的应用 (4)AI Agent
趋势二:从能力对齐到价值对齐-可信与对齐
(1)可信:小模型时代的价值对齐
(2)大模型时代的价值对齐
趋势三:从设计目标到学习目标-预训练+强化学习
(1)预训练获得基础能力,强化学习进行价值对齐
(2)预训练模仿人类,强化学习超越人类
展望
(1)“真”多模态:从微调回归预训练
(2)系统一 vs. 系统二
(3)基于交互的理解和学习
(4)超级智能 vs 超级对齐
引言
1956年的达特茅斯会议将“人工智能”定义为“使机器能够模拟人类进行感知、认知、决策、执行的一系列人工程序或系统”。这一定义催生了模仿人类智能的两种思路-逻辑演绎和归纳总结,它们分别启发了人工智能发展的两个重要阶段:(1)1960至1990年,以逻辑为基础、侧重知识表达与推理的知识工程方法;(2)1990年之后,以概率为基础、强调模型构建、学习和计算的机器学习方法。
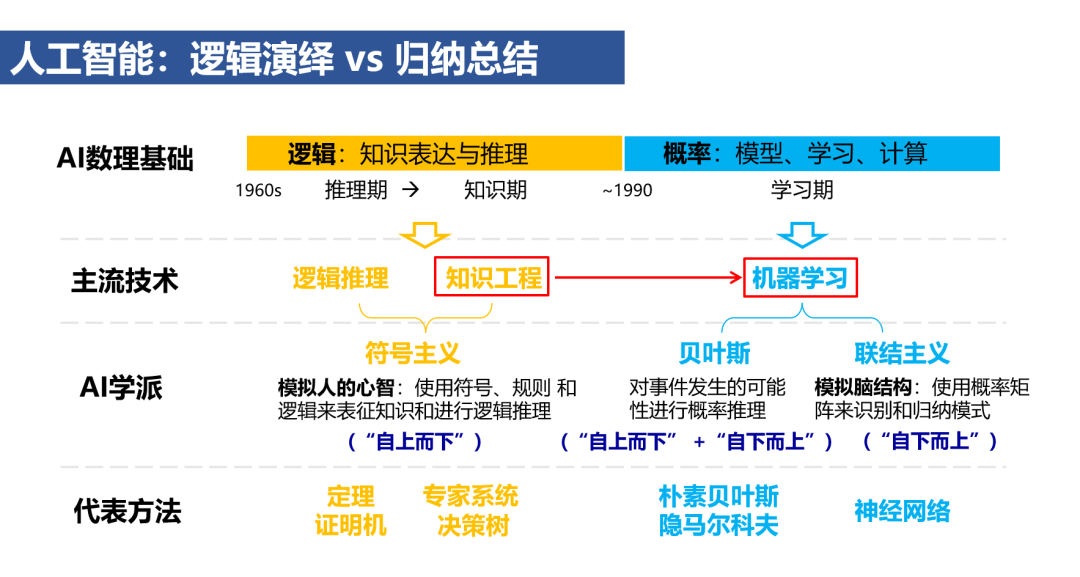
经过30多年的发展,机器学习方法大致经历了三个阶段:1990-2010年依赖手工设计特征的传统机器学习、2010-2020年从低层到高层进行监督表示学习的(传统)深度学习,以及2020年以后基于大规模无标注数据进行自监督学习的预训练大模型。围绕以预训练大模型为中心的第三代机器学习,下面探讨人工智能发展的三个趋势和对未来的四点展望。

**趋势一:从专用到通用-预训练大模型和智能代理 **
**
**
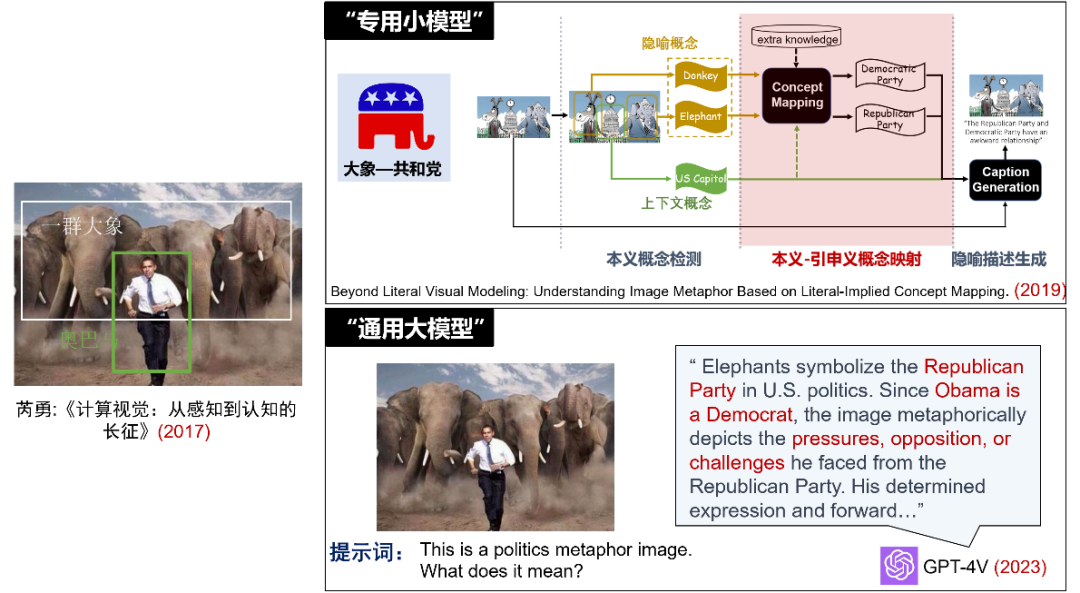
以中英翻译任务为例,知识工程方法需要语言学家来编写规则库,传统机器学习和深度学习基于语料学习概率模型或进行模型微调。这些方法都为特定的机器翻译任务而设计。然而,今天的同一个大语言模型不仅可以翻译几十种语言,还能处理问答、摘要、写作等不同的自然语言理解和生成任务。结合我自己的研究经历,芮勇老师在2017年提出了隐喻图像理解的认知挑战(将”大象”与“共和党”建立联系,从而理解图像对美国政治的讨论)。我们在2019年通过多个专用小模型流水线式(本义概念检测-本义引申义概念映射-隐喻描述生成)的方式尝试进行了解决。而到了2023年,只需要一句简短的提示词,GPT-4V就能非常准确地理解图像背后的政治隐喻含义。
预训练大模型采用的大规模预训练技术与早期深度学习中的逐层预训练技术,虽然都基于无标注数据来学习特征表示,但在训练方法、预训练任务、模型架构、功能实现、起源以及资源需求等方面存在很大差异。从起源来看,逐层预训练技术最初应用于计算机视觉领域,旨在学习图像的视觉特征表示。而大规模预训练技术的起点是自然语言处理领域的语言模型NNLM和Word2Vec。

**(1)预训练语言模型 **
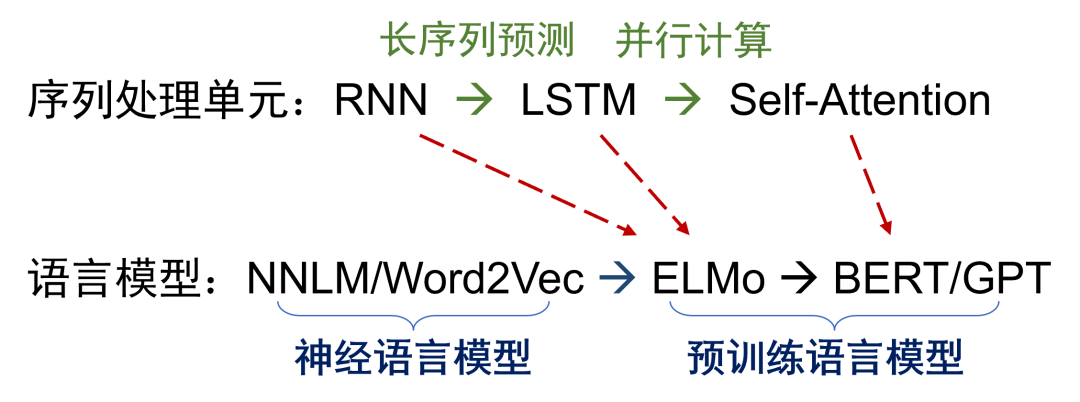
语言模型的核心是计算一段文本序列出现的概率,大致经历了统计语言模型、神经语言模型和预训练语言模型几个发展阶段。与基于静态词向量的神经语言模型(如Word2Vec)不同,自ELMo模型起,预训练语言模型开始学习能够感知上下文的动态词表示,从而可以更准确地预测文本序列的概率。在序列处理单元的发展上,从RNN到LSTM,再到Self-Attention,逐步解决了长序列预测和并行计算的问题。因此,预训练语言模型得以在大规模无标注的样本上进行高效学习。根据算力、数据量、模型规模之间关系的scaling law,目前预训练语言模型的性能提升还没有触及天花板。
**(2)视觉和多模态预训练 **
预训练语言模型的成功给计算机视觉领域带来了两个启示:一是利用无标注样本进行自监督学习,二是学习能够适应多种任务的通用表示。从iGPT、Vision Transformer、BEiT、MAE到Swin Transformer,自注意力机制的计算资源消耗、局部结构信息保持等问题被逐步解决,推动了视觉预训练模型的发展。 多模态预训练模拟了人类理解物理世界的多模态过程。将大语言模型比作机器的大脑,多模态则为其提供了感知物理世界的眼睛和耳朵,可以极大扩展机器的感知和理解范围。多模态预训练的核心问题是如何有效实现不同模态之间的对齐。根据模态对齐策略的不同,多模态预训练大致经历了多模态联合预训练模型和多模态大语言模型两个阶段。早期模型并行处理不同模态的数据进行预训练,主要技术包括单模态局部特征提取、模态对齐增强、跨模态对比学习等。其中CLIP通过在4亿图文对上进行对比学习,成功打通了语言和视觉模态。自2023年起,LLaVa、Mini-GPT、GPT-4V等在大语言模型的基础上,通过微调来融合其他模态数据,从而继承了语言模型中丰富的世界知识和优秀的交互能力。谷歌的Gemini模型则重新采用了联合预训练的多模态架构。最近,随着LVM、VideoPoet和Sora等新模型的出现,多模态预训练呈现出如下趋势:(1)重视语言模型在多模态理解和生成的作用;(2)通常包含多模态编码、跨模态对齐和多模态解码三个关键模块;(3)跨模态对齐趋向于采用Transformer架构、模型采用自回归(VideoPoet)或扩散(Sora)方法。

**(3)预训练模型的应用 **
根据Leslie Valiant的观点[1],大规模预训练可以类比生物神经网络通过亿万年数据积累所形成的先天结构先验,即群体基因或生理进化。预训练模型的应用,则类似于个体在后天面对小数据进行的微调。沿着GPT系列的发展,我们可以清晰地看到预训练模型能力和对应的应用方式的变化:从GPT-1的预训练模型参数微调(全量微调/参数高效微调)、GPT-2展现零样本能力后的提示工程、GPT-3展现上下文学习能力后的范例设计、以及到GPT-3.5任务涌现后直接通过任务描述来引导模型。OpenAI的成功很大程度来源于其领先的认知和始终如一的坚持:通过增加数据和模型规模推动智能向更加通用的方向发展。 
- 从闭集到开集:预训练模型从大规模数据中学习到通用知识,打破了任务解决局限于特定类别的限制。例如,CLIP通过建立语言与视觉模态的关联,能够处理零样本的视觉理解任务;SAM能够对未见过的物体和场景进行有效分割等。
- 老问题、新理解:模型应用方式的演变也为我们提供了对传统问题理解的新视角。比如,小样本学习从依赖训练阶段的标注样本,转变为在推理阶段通过提示词注入样例上下文;零样本学习由于CLIP等隐性知识库的普遍存在,已逐渐转变为开放词汇学习的问题。
- 中间任务的边缘化:自然语言处理领域中,如分词、词性标注、NER等中间任务的重要性正在降低。经典的自然语言处理借鉴计算语言学,中间任务多是由人设计的。比如传统对话系统被设计成包含自然语言理解、对话管理和自然语言生成三个模块,每个模块又细分为若干个中间任务。然而,随着以自回归的方式预训练数据达到一定规模后,这些中间任务和模块被统一为了对下一个词元预测的问题。从上述介绍的隐喻图像理解例子,我们也能观察到视觉和多媒体领域的类似变化。
- 领域边界的模糊化:计算机视觉CV和自然语言处理NLP的领域界限正日益模糊。在传统机器学习时代,CV从NLP借鉴了基础的Bag-of-Words词袋模型表示方法;而在早期深度学习阶段,NLP则从CV引入了MLP、ResNet等网络结构,以及Dropout、批归一化等训练和优化技术。到了预训练大模型时代,CV先是借鉴了NLP的自监督预训练和自注意力机制,而随着LVM和VIdeoPoet等视觉GPT和视频生成GPT类模型的推出,两个领域正朝着多模态编码和自回归模块化结构统一的方向发展。

**(4)AI Agent **
预训练大模型的通用性不仅体现在内容理解和生成上,还扩展到了思考和决策能力上。将Jasper、Midjourney等处理通用任务并具有自然交互能力的AI系统定位为CoPilot,具有规划任务和使用工具能力的AI系统则可以被称为AutoPilot,也就是AI Agent。在CoPilot模式下,AI是人类的助手,与人类协同参与到工作流程中;在AI Agent模式下,AI是人类的代理,独立地承担大部分工作,人类只负责设定任务目标和评估结果。 值得注意的是,AI Agent的概念在人工智能的早期就存在,在预训练大模型之前经历了基于规则设计和基于强化学习两个阶段。当前讨论的AI Agent,更准确地说,是基于预训练大模型的AI Agent。相比前两个阶段的AI Agent面向特定任务和场景设计,基于预训练大模型的AI Agent核心特点在于其对通用任务和场景的适应性。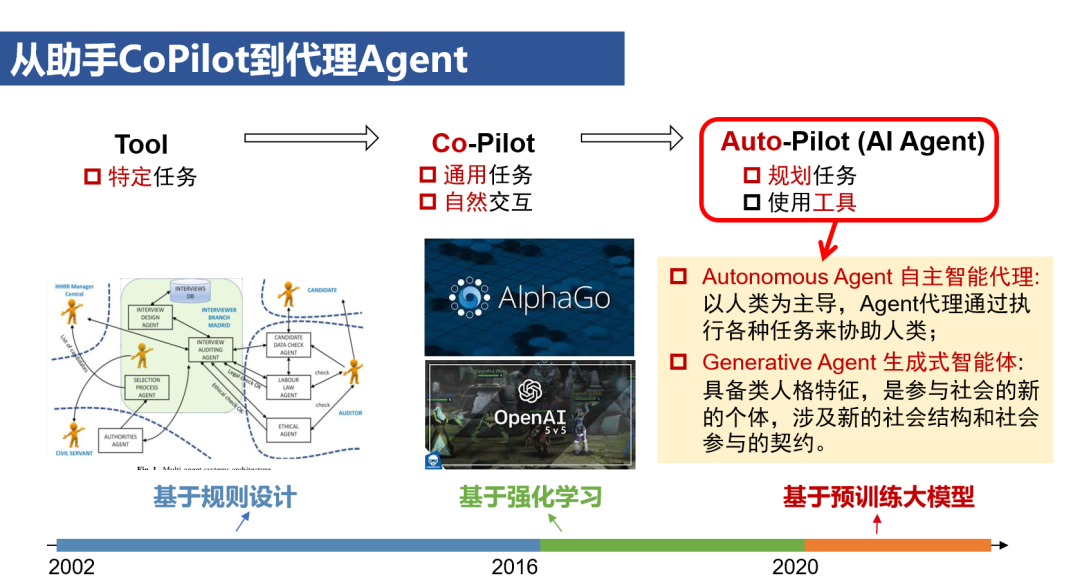
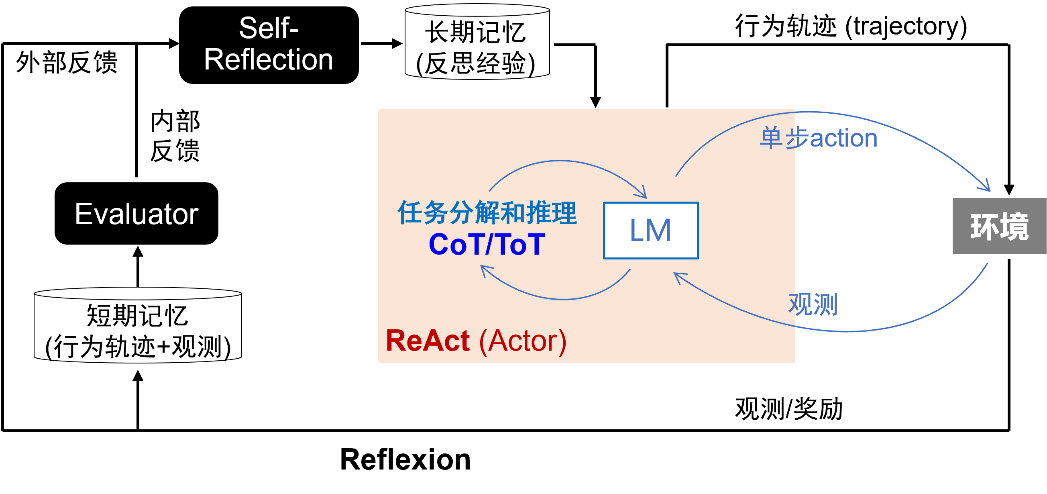
随着大模型逐渐成为未来社会的基础设施,如同电网、计算机、互联网成为基础设施后普及的电力、算力和信息获取能力,智能服务的成本也将大幅降低。AI Agent,作为智能服务普及的应用载体,将推动AI原生技术的变革。
从C端来看,AI Agent将成为智能时代的信息入口:用户将不再需要登录不同网站/App来完成各种任务,而是通过AI Agent与各类服务进行统一交互。AI原生的应用、操作系统甚至硬件,将超越现在的图形用户界面GUI(Graphical User Interface),更多地融合自然语言用户界面LUI(Language User Interface)[2],提供更为直观和便捷的交互体验。。 从B端看,机器学习即服务(MaaS)将机器学习模型作为服务来提供,相比SaaS实现了云服务的智能化升级。而代理即服务 (AaaS)则进一步将智能代理作为服务,推动云服务进一步向自动化升级。有观点认为,软件生产将进入类似3D打印的2.0时代,其具有(1)AI原生-面向AI使用设计自然语言接口、(2)解决复杂任务-规划和执行任务链、(3)个性化-满足长尾需求等特点。在这一趋势下,面向企业的软件可能不再仅仅是辅助员工的工具,而是作为数字员工,替代执行一部分基础和重复性的工作。 基于预训练大模型的AI Agent仍然面临如下几方面的技术挑战:
- 机制工程的设计复杂性和应用泛化性:目前AI Agent的工具调用、任务规划通常涉及复杂的机制工程(mechanism engineering),即通过启发式方法编写包含逻辑结构和推理规则的提示词框架。这种手工设计方式难以适应不断变化的环境和用户需求。根据从手工设计到数据驱动学习的发展规律,面向AI Agent进行机制学习是可能的解决思路,以实现更加灵活自适应的智能代理行为。

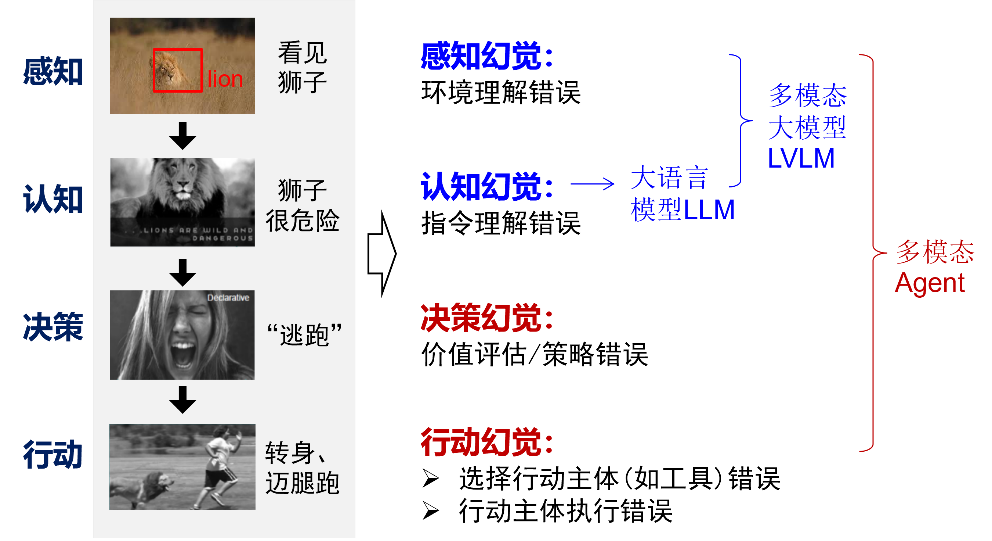
- 可信与对齐:由于加入了记忆、执行、规划等环节,面向AI Agent的可信与对齐有新的问题需要解决。例如,在对抗鲁棒性方面,不仅要关注模型本身的抗攻击能力,还要考虑记忆载体、工具集、规划过程等的安全性;在处理幻觉问题上,除了感知和认知阶段的幻觉,还要考虑决策和行动阶段的幻觉。
- 长上下文规划和推理的一致性:在处理长对话或复杂任务时,Agent需要保持上下文的连贯性,确保其规划和推理过程与用户的长期目标和历史交互保持一致。
- 自然语言接口的可靠性:相比计算机语言严格的语法和结构,自然语言具有歧义和模糊性,可能导致指令理解和执行时出现错误。
**趋势二:从能力对齐到价值对齐-可信与对齐 **
**
**
从人工智能的定义可以看出其与人类对齐的初衷。无论是基于逻辑演绎的知识工程方法,还是基于归纳总结的统计机器学习方法,目的都是与人类的对齐。以机器学习方法为例,监督学习范式下,人类标注训练数据集(X,Y),模型学习从输入X到输出Y的映射f(),这一过程可以看成一种类人知识蒸馏;无监督和自监督范式下,由人类定义的相似度度量和代理任务(比如生成式代理任务旨在重构人类语言或自然图像)也在向模型传递人类的知识。通过将训练目标函数和人类对齐,模型在一系列代表人类不同能力的任务上相继通过了图灵测试,这在一定程度上实现了与人类的能力对齐。

然而,在一些强人机交互和对安全有严格要求的领域,由于鲁棒性、公平性、解释性等问题,AI模型仍然难以实现工业级的大规模应用。

目前,对于AGI实现的标准还没有达成共识。如果将人机对齐视为实现AGI的一种标准,那么在追求目标层面上的能力对齐之外,还要考虑行为方式层面的价值对齐。能力对齐和价值对齐可以类比为结果和过程:就像旅行到达目的地是结果,但采用哪种交通方式、选择哪条路线可以有不同的过程。 
**(1)可信:小模型时代的价值对齐 **
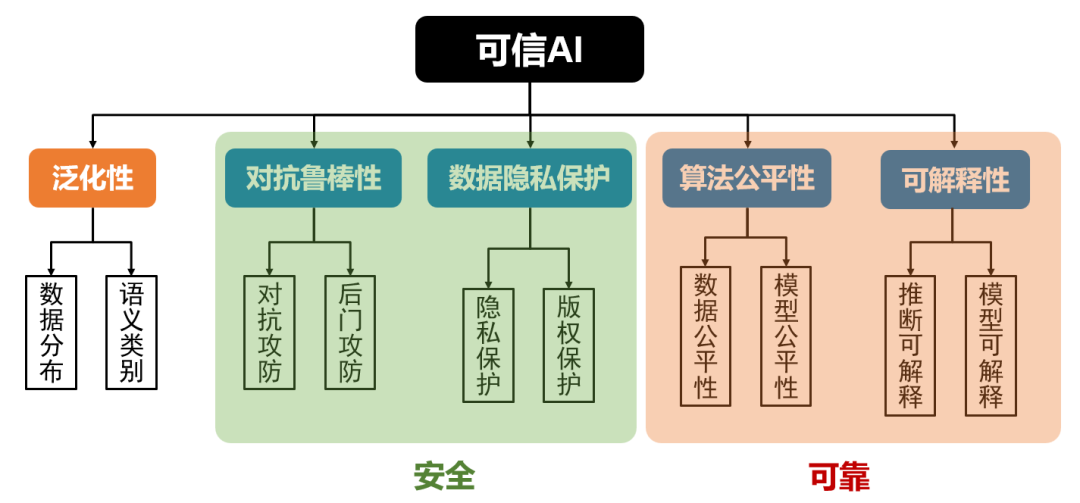
可以发现,价值对齐所要求的对抗鲁棒性[3]、算法公平性[4]、可解释性[5]、数据隐私保护[6] 等问题,正是构成经典可信AI的四个核心维度。而可信AI是建立在泛化性的基础上,这也对应了能力对齐是价值对齐的先决条件。概念上,我们可以将价值对齐看做可信AI的外延,它不仅包含了技术层面的对齐,还涵盖了更广泛的伦理和社会责任。
**(2)大模型时代的价值对齐 **
到了预训练大模型时代,随着AI能力的持续提升,应用广度和深度都将大幅增加。能力越大,责任越大。人们在享受AI带来的便捷和生产力提升的同时,对AI的态度将从适应逐渐转变为依赖。当人们开始依赖AI代替自己学习、思考、甚至决策时,对AI的可信和价值对齐也提出了更高的要求。除了将经典可信问题的研究对象从专用小模型迁移到预训练大模型上[7,8,9],我们还面临着一系列新的可信和价值对齐问题。 Anthropic提出了人机对齐的“3H原则[10]”:其中Helpful有益对应了能力对齐对于准确性的要求;而Honest诚实和Harmlles无害则大致对应了价值对齐中在可靠性和安全性方面的要求。哈工大秦兵老师提出的框架[11]中从合事实、合法、合情、合文化的维度,设定了普适和多元的价值观对齐目标。相比经典可信AI中的问题,在新的价值对齐框架下,特别是面向生成式AI的特点,真实性[12]、无毒害性[13]、情境适应性[14]等新的价值对齐问题需要给予更多的关注。

根据不同时间范围,OpenAI设定了3个对齐与安全团队,分别面向当前的前沿模型、过渡阶段模型和未来超级模型。根据这个设定,下面结合我们自己的研究例子讨论大模型时代价值对齐的三个阶段。
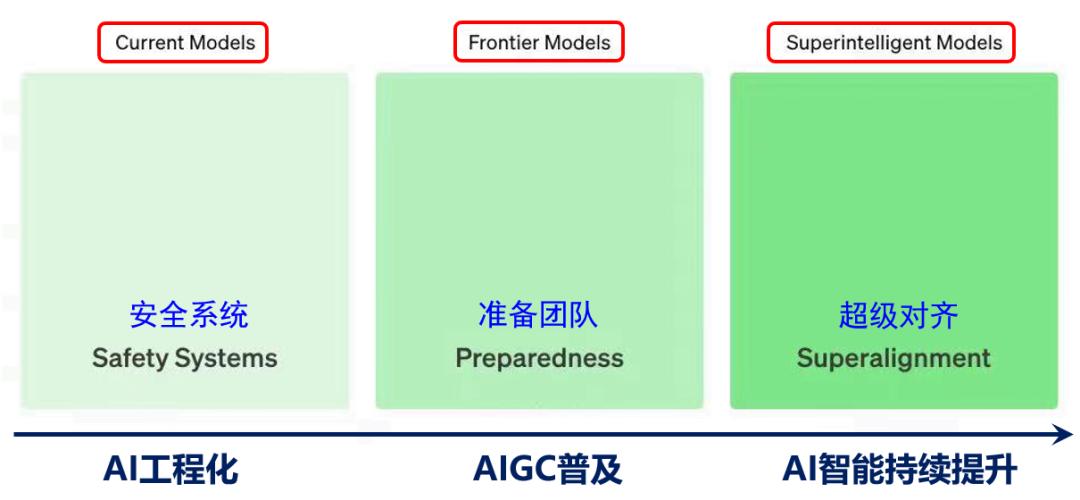
**AI工程化:可信大模型测试、诊断和修复 **
应用生态建设是技术走向成熟的标志。以软件科学向软件工程的发展为例,通过建立测试环境、工具链、开发平台等基础设施,完善软件构建、部署和维护等DevOps关键环节,形成了一个完整的软件开发周期。AI的工程化应用生态建设涉及对整个智能生命周期进行管理。其中的软件生态AIOps/LMOps通过提供必要的工具和服务,以确保模型开发、测试、部署和运维的高效与稳定。可信和价值对齐的研究需要深入到AI应用生态的构建和实施中,从概念和框架研究转向更加实际的技术实践,并将解决方案以工具和集成模块的形式支撑模型研发和应用开发人员。

仍以软件工程为例,其应用生态的核心在于构建一个完备的测试-调试闭环体系,包括性能评估、缺陷识别定位与修复、以及回归测试等环节。测试调试闭环的实施能够提高软件的可靠性,降低故障率和安全风险。由于数据驱动带来的黑箱问题,机器学习模型无法像软件那样直接实现调试。借助解释性方法对预训练模型进行诊断,定位存在问题的模块或模型参数,进而采取针对性的修复措施。对模型测试、诊断和修复的过程可以类比于去医院看病的检查、问诊、治疗环节。完成模型修复后,需重新测试以确认问题已解决且未引入新的问题,从而形成测试调试的闭环。

测试、诊断、修复技术应以模块化或工具的形式来支撑大模型研发和基于大模型的下游应用开发:
- 模型研发支持:测试和调试技术应集成为模块,嵌入到现有的研发流程中。这些模块需针对预训练模型的特性进行定制设计,以便研发人员能够迅速评估模型的性能,准确定位问题,并执行有效的优化措施。
- 下游应用开发支持:对于基于大模型的下游应用开发,测试和调试工具可以通过云服务的形式,在大模型平台上提供。这样,开发者便能够依据具体的应用场景对模型进行细致的评估和调整,从而简化模型的部署和运维流程,提升下游应用的可靠性和安全性。
**AIGC普及:自然-合成数据的OOD问题 **
从ChatGPT、Midjourney到Sora和Suno,文本、图像、视频、音乐的AI合成内容质量不断提升,使得人越来越难以区分。AIGC内容的高真实性已经可以混淆人类的判断,首当其冲的挑战就是数字取证和伪造检测,引发人们对虚假信息的担忧。另一方面,AI生成作为实实在在的生产力,AIGC无处不在的趋势恐怕难以阻挡。前段时间,全AI生成的预告片“芭比×海默”引发了病毒式传播和热议,Gartner预测:到2030年,主要影视作品中AI生成内容的比例将从2022年的0%上升到90%。

随着社会逐渐适应和接受AI合成内容,特别是在AI替代人类的场景下,会出现很多AI工具与AI合成内容交互的情况。这会带来一个新问题:目前这些从训练数据、结构到训练方法都是面向自然数据设计的模型,当应用到AI合成内容上时,会有什么问题?比如, AI合成文本和图像会带来信息检索的偏见[15],并在检索循环中放大这种偏见[16];相比自然图像,AI合成图像更容易产生幻觉[17]。看起来AIGC不仅confuse了人类,同时confuse了AI自己。 随着AI合成数据日益增多,我们可能会遇到以下几种情况:
- 传统泛化问题:用自然数据训练,应用于自然数据。这是过去几十年研究主要关注的情况,很多任务在实验室条件下解决得很好了。
- 自然到合成数据泛化:用自然数据训练,应用于合成数据。也就是上述工作[15,16,17]讨论的情况。
- 合成到自然数据泛化:用合成数据训练,应用于自然数据。比如,ShareGPT数据集广泛应用与大语言模型训练,Sora可能使用游戏引擎合成训练数据。合成数据可以弥补自然数据的不足,推动模型能力的持续提升。这种情况预计会持续增长。
- 合成到合成数据泛化:用合成数据训练,应用于合成数据,这是合成数据内部的泛化性问题。
情况2和3可以被视为广义的OOD问题,可以称之为“自然数据与合成数据的OOD”(Natural-Synthetic OOD)。实际上,即使是情况4,也应该考虑以某种方式混合自然数据和合成数据进行模型训练。深入理解自然数据和合成数据的差异,除了应用于鉴别真伪,对未来有效地使用合成数据训练、以及在应用中与合成数据进行交互也非常重要。

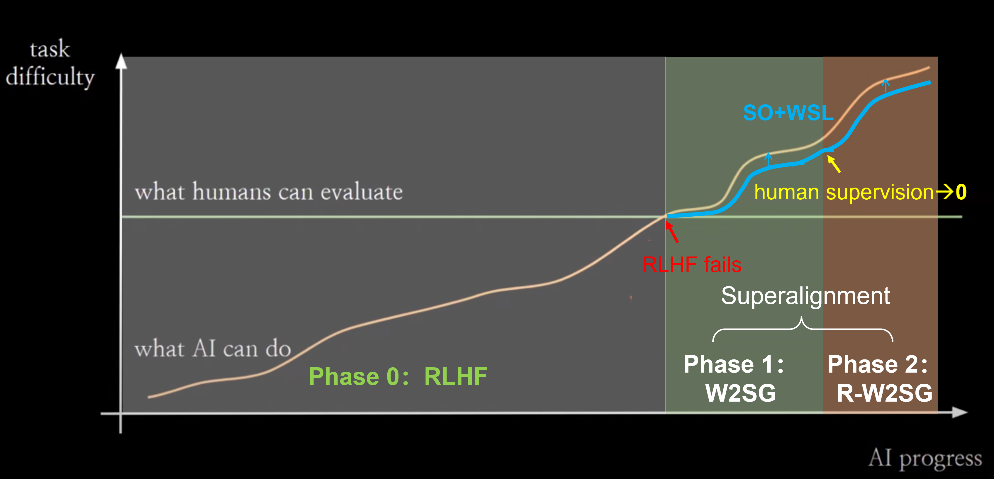
**AI智能持续提升:超级对齐 **
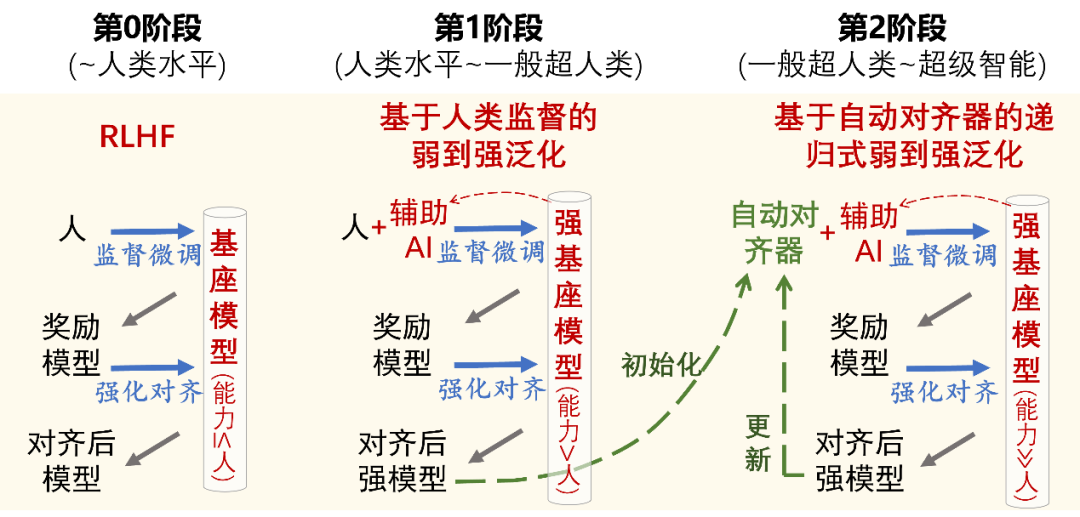
目前实现价值对齐的主流方法是RLHF。当人类评估者可以提供高质量的反馈信号时,RLHF非常有效。但在AI能力进化的时间尺度上,人类的评估能力是相对固定的。从某一个临界点开始,人类将无法再为对齐AI系统提高有效的反馈信号。超级对齐的核心问题是在这种情况发生时如何让弱监督者控制比他们聪明得多的模型。 OpenAI超级对齐团队提出的弱到强泛化(Weak-to-Strong Generalization, W2SG)框架[18]为超级对齐提供了新的解决思路,通过用弱老师模型模拟人类监督者、强学生模型模拟超过人类的被监督者,让超级对齐的实证研究成为可能。可扩展监督(Scalable Oversight, SO)致力于增强监督系统,结合可扩展监督可以减少弱监督和强学生之间的能力差距,更好地挖掘弱到强泛化框架的潜力 [19]。进一步,弱监督学习与弱到强泛化有类似的问题设置:如何更好地利用不完整和有缺陷的监督信号。因此,在弱到强泛化框架下融合可扩展监督和弱监督学习,分别从增强监督信号和优化对监督信号的利用两个角度来激发更强大模型的能力。
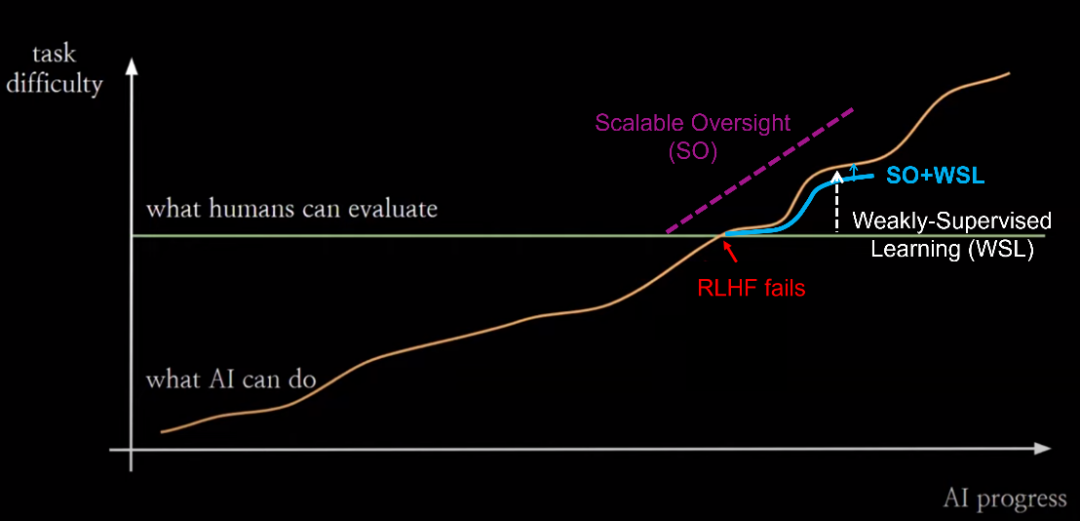
随着AI能力进一步提升,可能会到达第二个临界点:人类监督作用逐渐减弱至零。此时需要可以采用已经对齐的最强学生模型来替代人类,成为超人类的自动对齐评估器(automated alignment evaluator),作为新的弱老师模型继续监督这之后更强的学生模型。自动对齐器可以进行递归更新(Recursive W2SG,缩写为R-W2SG):使用经过监督对齐的强学生模型来更新自动对齐器,实现下一代的弱到强泛化,这样可以确保弱老师模型和强学生模型之间只存在一代的能力差距。
**趋势三:从设计目标到学习目标-预训练+强化学习 **
**
**
OpenAI研究员Hyung Won Chung从手工设计和自动学习模块的变化角度,总结了人工智能从专家系统、传统机器学习、深度(监督)学习到深度强化学习的发展历程[20]。在传统机器学习和深度学习中,目标函数需要通过手工设计,重点在于学习特征表示和特征到目标的映射。而强化学习将目标函数也作为可学习的模块,可以解决那些难以直接定义目标的任务。
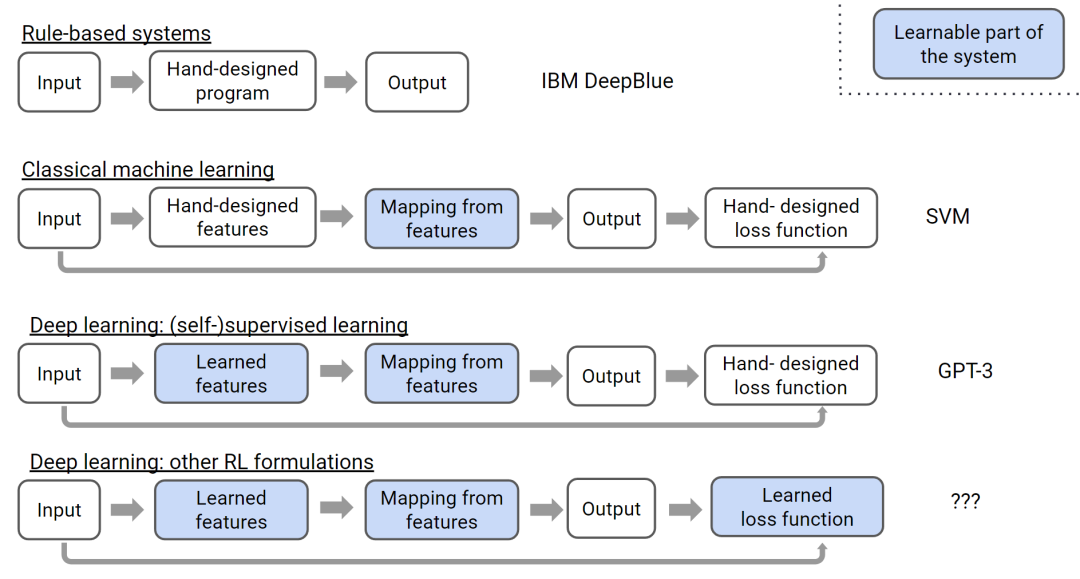
对比机器学习最近的主要发展节点,深度学习和大规模预训练分别对应了模型结构和对数据标注要求的变革,而强化学习聚焦于目标函数的变革:在缺乏明确目标指导的情况下,通过与环境的交互学习。将预训练与强化学习结合,是一个潜力巨大的研究方向:预训练对人类已有知识和经验压缩,但其受限于概率建模的约束,创造未知知识的小概率事件很难发生;强化学习通过平衡利用已有信息和探索未知知识,引入随机性,有机会打破预训练模型依赖人类设计的局限,实现更高层次的智能。

(1)预训练获得基础能力,强化学习进行价值对齐
目前大模型训练通常遵循预训练、监督微调、基于反馈强化学习三个主要步骤。预训练阶段通过大量无标注的数据学习语义语法等基础能力。监督微调通过高质量的提示词与答案配对样本对模型进行微调,可以提升模型的指令跟随,同时确保输出答案的形式符合预期。第三步的目的是使模型的输出符合人类偏好和价值观。由于人类价值观的复杂性,直接定义非常困难。因此,在RLHF中首先学习一个奖励模型,作为人类偏好的一种代理;然后通过与环境(即奖励模型)的交互,让模型学习并逐渐对齐人类的价值观。 *
**(2)预训练模仿人类,强化学习超越人类 **
AlphaGo的训练除了模仿学习还有自我博弈强化,从而探索出了超越人类经验的策略;相比之下,现在的预训练大模型只有模仿学习,依赖反映人类活动的语料库进行学习,模仿的是人类已有的知识和表达方式。参考AlphaGo强化学习的奖励设计方式,为语言建模设计一个类似于围棋输赢的自我博弈任务,有希望突破人类知识的局限。当然,语言的复杂性和多样性使得定义任务何为“胜利”没那么容易,可能的方法是为预训练模型设置不同的角色或立场,通过竞争或协作类的博弈任务进行能力增强[20]。 Demis Hassabis认为创造力分为三个层次,分别是插值(interpolation)、外推(extrapolation)和发明(invention)。根据这个分类,预训练大模型目前仍然停留在第一个层次:对已有知识进行插值和组合,但显然已经做到了顶级水平。AlphaGo与李世石第二局中的第37步是第二层次外推的代表:下出了人类棋手没见过的策略。通过预训练+强化学习突破人类监督限制,可以看成是在探索大模型的第二个层次。关于第三个层次,Hassabis认为它关注的“不是围棋中下了一步好棋,而是发明了一种新的棋类游戏”。对应到大模型,可能需要它发现新的数学猜想或定理。回想AlphaGoZero抛弃了模仿学习人类棋谱,在只有胜负规则的情况下无师自通打了AlphaGo个100:0。类似的,如果抛弃预训练阶段对语料的拟合,让模型直接从零开始探索,是否可能突破人类语法限制、甚至开发出自己的语言,这会是实现第三个层次智能的解决方案么?
**展望 **
**
**
(1)“真”多模态:从微调回归预训练
尽管在过去的一年里,大语言模型的成功促使很多多模态模型选择在已有的大语言模型基础上进行视觉和语音编码器的微调,但从长远来看,多模态大模型的发展倾向于从头联合预训练多种模态数据。虽然语言是人类智能区别其他动物的关键,但从人类大脑的进化过程看,语言能力是在大概50万年才开始发展的。人类视觉系统的进化经历了几亿年的时间,早在语言能力形成前就完成了。此外,教育学的经验也告诉我们,协调多模态感知有助于孩子的智力发育。 目前,我们已经看到一些模型,如Gemini,重新采用了联合预训练的方法。同时,许多人预测,下一代的多模态大模型,如GPT-5,尤其是当加入视频生成能力后,将更可能采用统一的联合预训练方法。联合预训练能够从底层更全面地理解和整合来自不同模态的信息,建立更深层次的联系和协同。 *
**(2)系统一 vs. 系统二 **
虽然AI Agent通过设计复杂的提示词强迫模型进行系统二的慢推理,但模型在预训练阶段对语料的系统一式处理限制了其复杂推理能力。据传DeepMind和OpenAI正计划通过加入树搜索等策略增强对于训练数据的利用,这本质上是在训练阶段引导模型进行系统二式的学习。这种训练方法有望使模型在推理时能够更好地发挥出系统二的能力。 一个有趣的问题是,如果训练阶段采用系统二学习、而在推理时采用系统一快回答,会产生什么效果?回顾MuZero在训练中采用了MCTS自对弈方法,但在推理阶段、尤其是需要快速响应的场景,它并不执行在线MCTS搜索,而是直接使用训练好的策略网络来做决策。这可以理解为经过系统二的强化训练后,模型获得了复杂的推理能力,并已经将这些能力固化为系统一的直觉。这可能代表了一种更理想的应用场景:模型在训练阶段深入学习并掌握复杂的推理能力,而在应用中以一种更直接、简单的方式运用这些能力。 *
**(3)基于交互的理解和学习 **
李飞飞曾指出2020-2030的AI北极星任务是实现对真实世界的主动感知和交互。如果说统计方法通过模仿智能的结果来获得智能,交互可以被视为通过模拟实现智能的途径获得智能。相比逻辑演绎和归纳总结获得智能的形式化表达和自动实现方法,因果可能是实现通过交互获得智能的一个重要解决方案。因果有望通过干预、不确定推断、反事实推理等方式,解决统计机器学习在数据假设、优化目标、学习机制等方面的局限。

基于交互的学习,特别是在将预训练与强化学习结合的框架下,为人工智能的发展提供了新的视角。比如,将多模态预训练模型置于具身智能的框架中,使其能够在与环境交互的过程中学习和自我增强。通过与物理和社交环境的交互,模型可以分别增强其对物理世界[21]和社会互动[22]的常识理解和适应能力。 *
**(4)超级智能 vs 超级对齐 **
OpenAI的宫斗事件让“超级智能”和“超级对齐”这两个概念带到了公众视野中。作为OpenAI的技术领袖,Ilya Sutskever长期以来一直致力于推动AI智能水平的持续提升。而随着超级对齐团队的成立,以及他亲自担任团队负责人,他的工作重心已经转向了对齐和安全问题。 超级智能和超级对齐是未来人工智能发展的一条主要线索:一个探索能力上限、一个确保安全底线,一个打造最锋利的矛、一个构造最坚固的盾。
参考资料:
[1] Leslie Valiant: “Evolution as Learming.” Talk @Theory-Fest 2019-2020: Evolution. [2] Mobile-Agent: Autonomous Multi-Modal Mobile Device Agent with Visual Perception. 2024. [3] Benign Adversarial Attack: Tricking Models for Goodness. 2022. [4] Towards Accuracy-Fairness Paradox: Adversarial Example-based Data Augmentation for Visual Debiasing. 2020. [5] 面向图像分类的深度模型可解释性研究综述. 2022. [6] Adversarial privacy-preserving filter. 2020. [7] Towards Adversarial Attack on Vision-Language Pre-training Models. 2022. [8] Counterfactually Measuring and Eliminating Social Bias in Vision-Language Pre-training Models. 2022. [9] Exploring the Privacy Protection Capabilities of Chinese Large Language Models. 2024. [10] Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback. 2022. [11] 秦兵.”大语言模型之安全性检测及人类价值观对齐” 报告, 2023. [12] An LLM-free Multi-dimensional Benchmark for MLLMs Hallucination Evaluation. 2024. [13] CValues: Measuring the Values of Chinese Large Language Models from Safety to Responsibility. 2024. [14] CDEval: A Benchmark for Measuring the Cultural Dimensions of Large Language Models. 2024. [15] LLMs may dominate information access: Neural retrievers are biased towards LLM generated texts. 2024. [16] AI-Generated Images Introduce Invisible Relevance Bias to Text-Image Retrieval. 2024 [17] AIGCs Confuse AI Too: Investigating and Explaining Synthetic Image-induced Hallucinations in Large Vision-Language Models. 2024. [18] Weak-to-Strong Generalization: Eliciting Strong Capabilities With Weak Supervision. 2023 [19] Improving Weak-to-Strong Generalization with Scalable Oversight and Ensemble Learning. 2024 微信公众号文章:“超级智能是矛,超级对齐是盾”。 [20] 微信公众号文章:“关于Q*(Q-star)的两个猜测”。 [21] A Reconfigurable Data Glove for Reconstructing Physical and Virtual Grasps. 2023. [22] Emergent Tool Use from Multi-Agent Interaction. 2020

