来源:中国人工智能学会,文 / 梁吉业
0 引言
从微观世界粒子的相互作用到宏观世界人的社交,从自然生态系统中的食物网到人造互联网中的链接,事物间的关联可谓无处不在。图论起源于欧拉对“哥尼斯堡七桥问题”的研究,是建模事物间关联的有效工具。在大数据时代,事物及其关联前所未有地以数据的形式被记录和收集,具体体现为图数据。图数据,即包含图的数据,其中图的节点代表事物,边代表事物间的关联。进一步地,事物及其关联往往具有特定的性质,这些性质在经典的图论中是被忽略的。
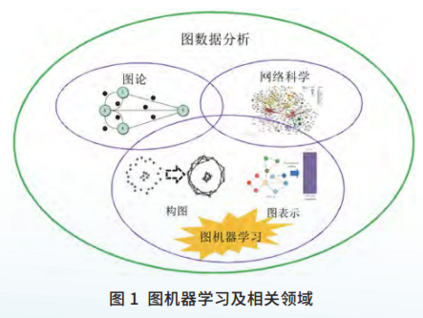
图数据分析在生物制药、智能交通、电子商务、疫情防控等领域发挥着极其重要的基础性作用。图机器学习,即从图数据中学习,是图数据分析的核心方法(见图1)。
图机器学习与网络科学(也称为“复杂网络理论”)相关但又不同。首先,网络科学研究的对象是图,其中的节点和边都是抽象的;而图机器学习研究的对象是图数据,其中的节点和边往往包含特定的性质。此外,网络科学侧重于发现和度量网络本身的性质,以及阐释这些性质产生的机理;而图机器学习则侧重于完成诸如分类、回归、聚类等学习任务。
与传统的机器学习相比,图机器学习以图数据为研究对象并将事物间的关联作为重点考虑因素,打破了传统机器学习独立同分布的基础假设,将引发新的学习理论和范式。
本文从基于构图的机器学习、基于图表示的机器学习和图机器学习应用三方面介绍图机器学习的前沿进展,并对未来可能的研究问题进行展望。
简介

梁吉业
计算智能与中文信息处理教育部重点实验室主任、山西大学教授。主要研究方向为数据挖掘与机器学习。CAAI 知识工程与分布智能专委会副主任,CAAI Fellow。
1 基于构图的机器学习
机器学习的目标是从数据中挖掘有价值的信息,而数据的质量对学习结果的好坏具有重要影响。如何利用低质量数据进行有效的学习是机器学习领域一个重要的研究问题。
在图机器学习中低质量数据问题包含两个层面,一是描述事物性质的数据是低质量的;二是描述事物间关联的数据是低质量的。其中第一个问题与传统机器学习所面临的低质量数据问题具有高度相关性,在此不进行展开分析;第二个问题是图机器学习特有的问题,也是本文关注的重点。图数据中图结构的建立可以分为两类,一类是天然存在的图;另一类是通过数据驱动的方法构建的图。这两类图在一定程度上都存在低质量问题。
1.1 低质图的质量提升
在一些实际应用中,图是天然存在的,可以直接作为图机器学习的输入。然而这些图的质量是无法保证的,其中可能包含对学习任务无关、甚至有误导性的关联信息。例如在科学引文网络分析中,跨学科的文献引用是学科交叉研究的体现,但这些引用关系对于将文献按学科分类是不太相关的;在网页搜索时,一些重要内容的链接会被人为篡改并指向恶意网页,这些链接对于网页排序是有害的。
针对低质的图结构信息,一种直接的思路是检测并修正图中对学习任务不利的关联信息,从而提高学习方法的泛化能力。然而,如何度量图中关联信息的好坏是一个具有挑战性的问题,往往涉及到数据分布与具体学习任务的特性,在大部分情况下只能通过具体学习任务的成功与否进行事后评价。另一种可行的思路是将图的修正也作为一个子学习任务并与具体的学习任务纳入统一的学习过程,动态地修正图中不利的关联信息,同时提高学习模型的性能。
1.2 数据驱动的构图
还有一些实际应用中,图并非天然存在,此时需要从数据中构建图。
传统的构图方法利用节点的属性信息直接计算出图,例如近邻构图、高斯核加权构图等。此类方法的优点是简单、高效,然而由于没有考虑数据本身的特性,因此难以反映数据真实的分布信息。另一类方法通过构建优化模型从数据中学习图,例如基于距离度量的方法,其建模的基本准则是样本间距离越小对应连边权重应该越大;基于数据表示的方法利用样本间表示系数度量连边的权重。此类方法可以较好地挖掘数据分布信息,但图的质量严重依赖于建模时采用的数据分布假设的正确性。上述两类构图方法都独立于具体的学习任务,因此难以满足具体学习任务的需求。数据驱动的构图通常面临两方面的挑战,第一,好的图应真实反映数据的分布信息,然而在实际中数据的分布通常是未知的、复杂多样的;第二,图质量的好坏通常是针对学习任务而言的,不同学习任务的需求是各异的。
在实际应用中,上述两个挑战往往同时存在。针对这一问题,动态构图的方法被提出,此类方法将构图与具体学习任务整合在同一个模型中,通过同时优化图和学习任务的解来进一步提升学习方法的性能。2021年,Liang 等提出一种自适应构图方法1,在自适应挖掘数据分布信息的同时兼顾具体学习任务的需求。该方法通过生成多个不同的聚类结果用来捕获复杂、多样数据分布信息,并将其权重和具体学习任务整合到一个优化问题中,实现二者的相互指导和动态提升。这种自适应构图的方法在图半监督学习和图嵌入降维两种学习任务中取得了明显效果。
2 基于图表示的机器学习
作为衔接图数据和下游任务的桥梁,图表示学习是进行各类图建模任务的关键环节。现有的图表示学习大致分为传统的图嵌入方法和新兴的图神经网络方法两大类。
2.1 传统图嵌入方法
在过去的几十年间,传统图嵌入方法取得巨大进展,涌现了大量工作,如谱聚类、基于图的降维、DeepWalk、LINE、PTE及node2vec等。这类方法的核心思想是将图结构信息转化为低维稠密的向量。这些低维的向量表示能够保留图的多种类型信息,如节点的邻域信息、节点的结构角色和节点状态等,从而使得其表示具有一定的可解释性,同时使得快速高效的算法设计成为可能,而不必再去考虑原本的图结构。2018年,Qiu等基于矩阵分解框架统一了传统的图嵌入方法2 ,概括了众多经典图嵌入方法在矩阵分解视角下的形式及作用机理。然而,传统的图嵌入得到的仍是“浅层”表示,且面临节点属性选择、可扩展性、嵌入维度选择等挑战。2020 年《美国国家科学院院刊》(PNAS)的一项研究表明,在某些情况下,基于矩阵奇异值分解的传统图嵌入方法无法准确地捕获复杂图中的局部结构,对既稀疏又具有高聚类系数的图难以获得有效的嵌入表示。可见,传统图嵌入方法并不能很好适配复杂的图数据分析场景。
2.2 图神经网络方法
近年来,图神经网络作为一种新型的图表示学习工具迅速崛起,其理论与方法的研究现正处于爆发期。如何构建具有较好表示学习能力的图卷积,从而有效获取图数据的“深层”抽象信息,已经成为图神经网络领域的研究热点。现有的图卷积方法可分为谱方法和空域方法两类,谱方法基于卷积定理及谱图理论来定义图卷积;而空域方法从节点域出发,通过定义不同的消息传递函数来实现中心节点和其邻近节点的信息聚合及更新。Bruna等于2014年首次给出了谱图卷积的定义3,提出了基于谱方法的图神经网络模型,同时也指出了谱图卷积的高计算复杂性等问题。后续有关谱方法的研究通常围绕如何构造图上的正交基(如Haar基、小波基)、如何实现快速正交变换等问题来设计不同的谱图卷积。空域方法则是类似欧式空间CNN卷积操作,通过设计不同的节点信息聚合及更新函数来完成节点间的消息传递,实现结构信息与节点特征信息的融合及抽象。实质上,不管是谱方法还是空域方法,构造图卷积的关键在于寻找节点信息聚合和更新的空间(频域/时域)及方式(滤波 / 聚合)。换句话说,谱方法在频域内做图信号滤波,空域方法在时域内做信息聚合,殊途同归。2017年Kipf等提出的GCN模型就是典型的例子4 ,从谱方法视角看其卷积运算是对ChebNet形式的简化,而从空域角度看其等价于1阶近邻节点的消息传递。
目前,关于图神经网络的图表示学习的研究,大多聚焦于大规模图数据分析与深层图神经网络模型构建两个方面。一方面,很多实际应用领域中的图数据规模超大,含百万甚至千万级节点,这对图神经网络模型的高效计算带来了巨大挑战。现有的研究通常基于图采样、图粗糙化、子图构建等策略,主要用来降低图神经网络处理大规模图数据的时间及空间代价。然而,这些方法通常也面临邻域选择的不确定性、采样带来的冗余计算,以及采样偏差、子图表示的信息丢失等问题。另一方面,面向复杂的大规模图数据,浅层图神经网络模型的表示能力有限,通过简单地堆叠图卷积模块构建的深度图神经网络模型表现出弱于浅层模型的表达能力。因此,探索现有图神经网络加深后出现的性能退化机理是目前亟需解决的痛点和难点问题。
基于图神经网络的图表示学习是当前图机器学习领域的一个热门研究方向,除了上述在大规模图数据和深层网络构建方面的进展外,还有很多值得深入研究的问题。例如,图神经网络如何在弱监督环境下进行表示学习、如何从攻防两方面开展图神经网络对抗鲁棒性的研究、如何可视化图神经网络的结构模式并对其进行可解释性分析、如何融合拓扑结构和节点特征设计图池化算子等。此外,实际应用中的异质图、多维图、符号图、动态图和超图等复杂图同样为图神经网络的表示学习研究带来了很大的挑战。
值得注意的是,基于构图的机器学习与基于图表示的机器学习并非是分离的,已有研究尝试将二者结合,以实现构图、图表示与下游图任务的端到端学习。
3 图机器学习应用
近年来,图机器学习在计算机视觉、自然语言处理、网络数据分析、推荐系统、交通预测和生物化学等领域取得了很多成功的应用。总体而言,这些应用呈现出三个趋势。
3.1 面向特定领域的图机器学习
相比仅关注事物性质或仅关注事物间关联的方法,图机器学习提供了更强大的建模能力,因此在特定的领域可以发挥更大作用。例如,在推荐系统中,图神经网络能够更好地整合用户与产品的属性信息及其交互信息,进而学到精准的用户偏好特征,以提升推荐效果;在链接预测中,图机器学习为融入节点和边的属性信息提供了方法,因此可以提高预测质量并完成冷启动预测任务,而这一任务仅利用网络拓扑信息是不能有效完成的。
3.2 面向复杂场景的图机器学习
传统的机器学习如分类、回归旨在学习并预测事物的性质,较少涉及事物间的关联。然而,在某些复杂的应用场景中,事物间关联是解决问题的核心。因此,需要用图建模事物间关联并将其作为学习目标。以图像描述(Image Caption)这类复杂任务为例,其难点是不仅要检测出图像中的语义目标,而且要理解这些语义目标之间的相互关系,最后还要用合理的语言表达出来。相比于简单的图像分割、目标识别任务,图像描述需要对图像进行更高层次的理解。类似的任务还包括自然语言处理中句法依存树的生成、知识工程中知识图谱的自动构建等。
3.3 融入知识的图机器学习
知识是由各种概念构成的。以概念为节点,以概念间的关联为边便构成了知识图谱。经过多年发展,目前已经积累了大量的领域知识图谱和世界知识。借助图机器学习,这些以图形式表示的知识可以方便地参与到学习过程中,从而提升学习方法的性能和可解释性。例如在机器阅读理解任务中,领域知识图谱可以与图神经网络模型有效结合,从而提高机器阅读理解系统的推理能力与可解释性。
除了上述三种趋势外,图机器学习也在不断地应用到新的领域,例如组合优化、程序分析和医疗健康等。
4 展望
虽然图机器学习在近些年取得了重要进展,但作为一个新兴领域,其仍然存在很多开放性的问题有待进一步探索。
从理论研究层面看,当数据间的关联作为重点考虑的因素时,传统机器学习采用的独立同分布假设将不再适用,以之为基础的传统学习理论也将不再适用,因此需要建立新的图机器学习理论。
从方法研究层面看,大部分现有的图机器学习方法本质上是将图数据嵌入到欧氏空间并在欧氏空间完成学习;然而图数据本身并非欧氏空间数据,因此需要发展可以直接处理图数据的机器学习方法。
从应用研究层面看,图机器学习将在需要重点关注事物间关联的应用场景(如电子商务、智慧交通、疫情防控等)中发挥更大的作用;同时由于考虑了事物本身的特性及其复杂的关联,将图机器学习方法用于自然科学和社会科学中大量存在的图数据,将促使新的科学发现,加快科学研究的进展。
(参考文献略)
1 https://link.springer.com/article/10.1007%2Fs10994-021-05975-y 2 https://dl.acm.org/doi/10.1145/3159652.3159706 3 https://arxiv.org/abs/1312.6203 4 https://arxiv.org/abs/1609.02907