关于ChatGPT的一切,读这篇论文就行了!

OpenAI最近发布了GPT-4(又名ChatGPT plus),这被证明是生成式AI (GAI)的一小步,但却是通用人工智能(AGI)的一大步。自2022年11月正式发布以来,ChatGPT凭借媒体的广泛报道迅速吸引了众多用户。这种前所未有的关注也促使众多研究者从各个方面对ChatGPT进行研究。据谷歌scholar统计,有500多篇文章的标题中有ChatGPT或在摘要中提到它。考虑到这一点,迫切需要进行调研,我们的工作填补了这一空白。首先对ChatGPT的底层技术、应用以及面临的挑战进行了全面的综述。对ChatGPT如何演变为实现通用AIGC(即AI生成内容)的前景进行了展望,这将是AGI发展的一个重要里程碑。

1. 引言
过去几年见证了大量生成式AI (AIGC,又称AI生成内容)工具的出现[73,135,141],这表明AI已经进入了一个创造而不是纯粹理解内容的新时代。关于生成式AI (AIGC)的完整调查,读者可以参考[214]。在这些AIGC工具中,2022年11月发布的ChatGPT引起了前所未有的关注。它吸引了众多用户,月活跃用户在短短两个月内就突破了1亿,打破了其他社交产品的用户增长记录[118]。ChatGPT是由OpenAI开发的,它最初是一个非营利性研究实验室,使命是构建安全有益的人工通用智能(AGI)。OpenAI在2020年宣布GPT-3后,逐渐被公认为世界领先的AI实验室。最近,它发布了GPT-4,这可以被视为生成AI的一小步,但对于AGI来说是一大步。
由于其令人印象深刻的语言理解能力,许多新闻文章提供了广泛的报道和介绍,举几个例子,BBC Science Focus [69], BBC news [39], CNN Business [79], Bloomberg news[157]。谷歌管理层针对ChatGPT的威胁发布了“红色警报”,暗示ChatGPT对公司,尤其是其搜索服务构成了重大威胁。在微软将ChatGPT引入必应(Bing)搜索服务之后,这种危险似乎更难被忽视。股价的变化也反映出微软相信ChatGPT可能会帮助必应与谷歌搜索竞争。这种对ChatGPT前所未有的关注,也促使众多研究人员从各个方面对这个有趣的AIGC工具进行研究[149,163]。根据我们在谷歌scholar上的文献综述,不少于500篇文章在标题中包含ChatGPT或在摘要中提到这个病毒式的术语。如果没有一个完整的调查,读者很难掌握ChatGPT的进展。我们的全面综述及时提供了对ChatGPT的初步了解。
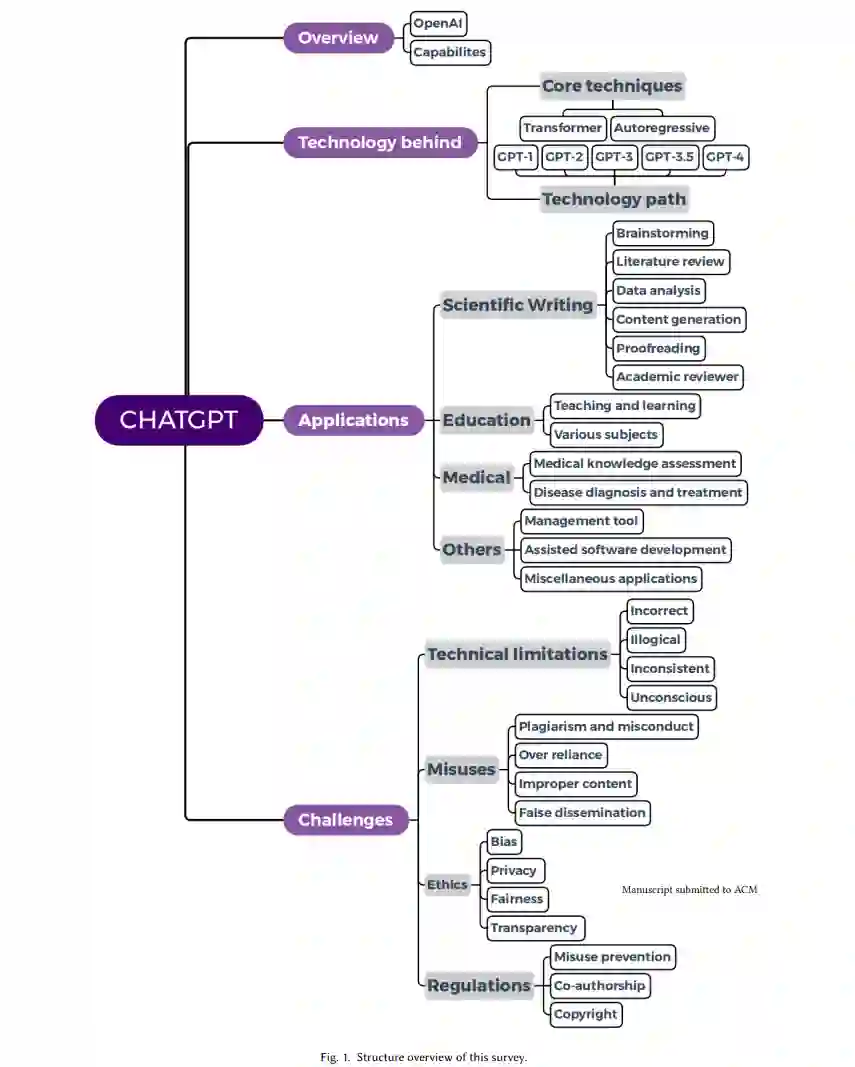
由于本次综述的主题可以看作是一个商业工具,因此我们首先介绍了开发ChatGPT的公司OpenAI的背景。此外,本综述还对ChatGPT的功能进行了详细的讨论。在背景介绍之后,本工作总结了ChatGPT背后的技术。具体来说,我们介绍了它的两个核心技术:Transformer架构和自回归修饰,在此基础上,我们给出了大型语言模型GPT从v1到v4的技术路径[18,122,136,137]。强调了突出的应用和相关的挑战,如技术限制、滥用、伦理和监管。最后,我们对ChatGPT未来如何演变为通用AIGC以实现AGI的最终目标进行了展望,从而总结了本调查。我们工作的结构化概述如图1所示。
2 ChatGPT概述
首先,我们提供了ChatGPT的背景和相应的组织,即旨在构建人工通用智能(AGI)的OpenAI。期望AGI能够解决人类层面的问题以及超越人类层面的问题,前提是建立安全、可信、有益于我们社会的系统。
2.1 OpenAI
OpenAI是一个研究实验室,由一组致力于构建安全和有益AGI[50]的研究人员和工程师组成。它成立于2015年12月11日,由一群备受瞩目的科技高管组成,包括特斯拉CEO Elon Musk, SpaceX总裁Gwynne Shotwell, LinkedIn联合创始人Reid Hoffman,以及风险投资家Peter Thiel和Sam Altman[78]。在这一小节中,我们将讨论OpenAI的早期发展,它是如何成为一个营利性组织的,以及它对AI领域的贡献。 OpenAI最初是一个非营利组织[24],其研究主要集中在深度学习和强化学习、自然语言处理、机器人等方面。在发表了几篇有影响力的论文[123]并开发了一些最复杂的人工智能模型后,该公司很快就因其前沿研究而建立了声誉。然而,为了创造能够带来资金的人工智能技术,OpenAI在2019年被重组为营利性公司[31]。尽管如此,该公司在为其技术创建商业应用的同时,继续开发合乎道德和安全的人工智能。此外,OpenAI还与几家顶级科技公司合作,包括微软、亚马逊和IBM。今年早些时候,微软透露了与OpenAI的一项为期数年、价值数十亿美元的新合资项目[21]。虽然微软没有给出确切的投资金额,但Semafor声称微软正在讨论花费100亿美元[101]。据《华尔街日报》(the Wall Street Journal)报道,OpenAI的市值约为290亿美元。
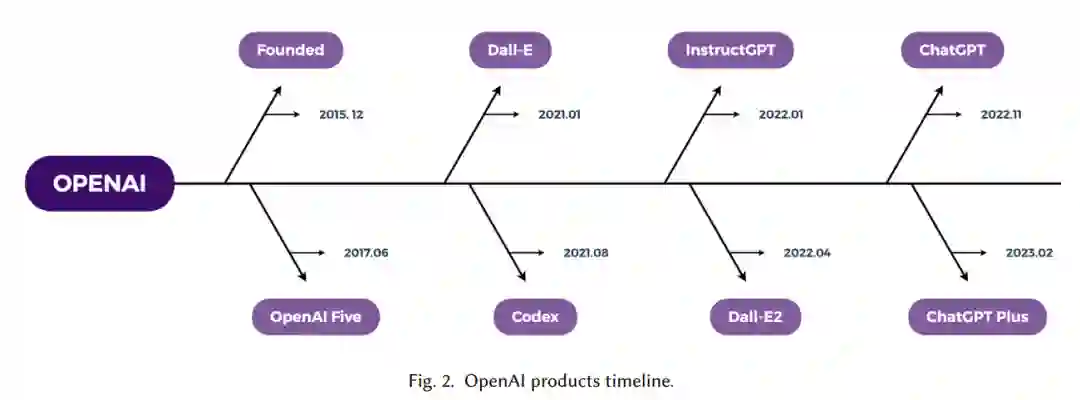
从大型语言模型到开源软件,OpenAI显著推动了人工智能领域的发展。首先,OpenAI开发了一些迄今为止最强大的语言模型,包括GPT-3[95],该模型因其在许多上下文中产生连贯和现实的文本的能力而获得了广泛的赞誉。OpenAI还开展了强化学习的研究,这是人工智能的一个分支,旨在训练机器人根据奖惩做出选择。近端策略优化(PPO)[71]、软Actor-Critic (SAC)[189]和可信区域策略优化(TRPO)[181]只是OpenAI迄今为止创建的一些强化学习算法。这些算法已被用于训练智能体执行各种任务,包括玩游戏和控制机器人。到目前为止,OpenAI已经创建了许多软件工具来协助其研究工作,包括OpenAI Gym[76],这是一个用于创建和对比强化学习算法的工具集。在硬件方面,OpenAI投资了几个高性能处理系统,包括NVIDIA的DGX-1和DGX-2系统[150]。这些系统是在考虑深度学习的情况下创建的,能够提供构建复杂AI模型所需的处理能力。除了ChatGPT, OpenAI开发的其他流行工具包括DALL-E[141]和Whisper [135], Codex[25]。图2显示了OpenAI产品发展历程。
ChatGPT使用交互形式对用户[1]提出的问题提供详细的、类人的回答。ChatGPT能够根据提示输入文本生成高质量的文本输出。基于GPT-4的ChatGPT plus还可以将图像作为输入。除了聊天机器人的基本角色外,ChatGPT还可以成功地处理各种文本到文本的任务,如文本摘要[45]、文本补全、文本分类[86]、情感[221]分析[112]、释义[104]、翻译[35]等。
ChatGPT已经成为搜索引擎领域的有力竞争者。正如我们在引言部分提到的,谷歌提供了世界上最优秀的搜索引擎,认为ChatGPT是对其垄断地位的挑战[188]。值得注意的是,微软已经将ChatGPT集成到其Bing搜索引擎中,允许用户接收更多有创意的回复[174]。我们可以看到搜索引擎和ChatGPT之间的明显区别。即搜索引擎帮助用户找到他们想要的信息,而ChatGPT开发双向对话的回复,为用户提供更好的体验。其他公司正在开发类似的聊天机器人产品,如谷歌的LamMDA和Meta的BlenderBot。与ChatGPT不同,谷歌于2021年开发的LaMDA积极参与与用户的对话,导致输出文本中出现种族主义、性别歧视和其他形式的偏见[119]。
BlenderBot是Meta的聊天机器人,由于开发人员对其输出材料设置了更严格的限制[130],用户的反馈相对枯燥。ChatGPT似乎在某种程度上平衡了类人的输出和偏差,允许更令人兴奋的反应。值得注意的是,除了比普通ChatGPT更高效和具有更高的最大token限制外,由GPT-4支持的ChatGPT还可以创建多种方言语言和情感反应,并减少不良结果,从而减少偏差[169]。文献[96]指出,可以通过使用多任务学习和增强训练数据质量来进一步提高ChatGPT的建模能力。
3 ChatGPT背后的技术
3.1 两项核心技术
骨干架构:Transformer。在Transformer出现之前[182],RNN是语言理解的主要骨干架构,而注意力是模型性能的关键组成部分。与之前只将注意力作为支持组件的工作相比,谷歌团队在他们的工作标题中声称:“attention is All You Need”[182]声称,自从谷歌在2017年发布了一篇论文,即“attention is All You Need”[182]以来,对Transformer骨干结构的研究和使用在深度学习社区中经历了爆炸性的增长。本文总结了Transformer的工作原理,重点关注其核心组件self-attention。自注意力的基本原理假设,给定输入文本,该机制能够为单个单词分配不同的权重,从而促进捕获序列中的依赖关系和上下文关系。序列中的每个元素都具有其唯一的表示形式。为了计算序列中每个元素与其他元素的关系,需要计算输入序列的Q (query)、K (key)和V (value)矩阵。这些矩阵是由输入序列的线性变换推导出来的。通常,查询矩阵对应于当前元素,键矩阵代表其他元素,值矩阵封装了要聚合的信息。通过计算查询与关键矩阵之间的相似度,确定当前元素与其他元素之间的关联权重。这通常通过点积操作来实现。随后,对相似度进行归一化,以确保所有关联的总和等于1,这通常通过softmax函数执行。然后将归一化的权重应用于相应的值,然后对这些加权值进行聚合。这个过程产生了一种新的表示,包括当前单词和文本中其他单词之间的关联信息。上述过程可以正式表述如下:
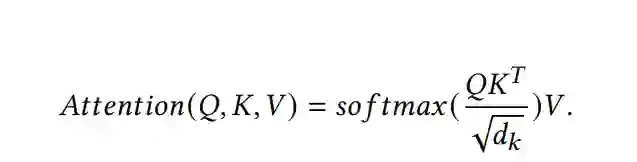
Transformer技术已经成为近期大型语言模型发展的重要基础,如BERT[41]和GPT[18, 122, 136, 137]系列也是基于Transformer技术的模型。还有一系列工作将Transformer从语言扩展到视觉,即计算机视觉[42,63,100],这表明Transformer已经成为NLP和计算机视觉的统一骨干架构。 生成式预训练:自回归。对于模型预训练[64,212,216-218],有多种流行的生成式建模方法,包括基于能量的模型[56,159,160,186],变分自编码器[5,84,124],GAN[17, 54, 198],扩散模型[20,33,213,215,220]等。在这里,我们主要总结自回归建模方法[11,90,90,177,178],因为它们是GPT模型的基础[18,122,136,137]。自回归模型是统计分析中处理时间序列数据的一种重要方法。这些模型指定输出变量与前面的值线性相关。在语言建模的上下文中[18,122,136,137],自回归模型根据前一个单词预测后一个单词,或根据下面的单词预测最后一个可能的单词。该模型学习序列数据的联合分布,使用之前的时间步长作为输入来预测序列中的每个变量。自回归模型假设联合分布𝑝𝜃(𝑥)可以分解为条件分布的乘积,如下所示:
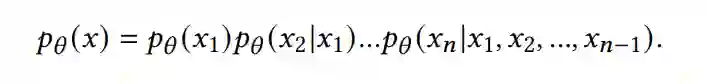
虽然两者都依赖于之前的时间步长,但自回归模型与循环神经网络(RNN)架构的区别在于,前者使用之前的时间步长作为输入,而不是RNN中发现的隐藏状态。本质上,自回归模型可以被概念为一个前馈网络,其中包含所有之前的时间步长变量作为输入。早期的工作使用不同的函数对离散数据进行建模,以估计条件分布,例如全可见Sigmoid置信网络(FVSBN)[51]中的逻辑回归和神经自回归分布估计(NADE)中的一个隐层神经网络[90]。随后的研究扩展到对连续变量建模[177,178]。自回归方法已广泛应用于其他领域,具有代表性的作品有:PixelCNN[180]和PixelCNN++[153]),音频生成(WaveNet[179])。
3.2 技术路径
ChatGPT是在一系列GPT模型的基础上发展起来的,这是自然语言处理领域的一项重大成就。图6概述了这一开发过程。在下面,我们总结了GPT的关键组成部分以及更新后的GPT的主要变化。

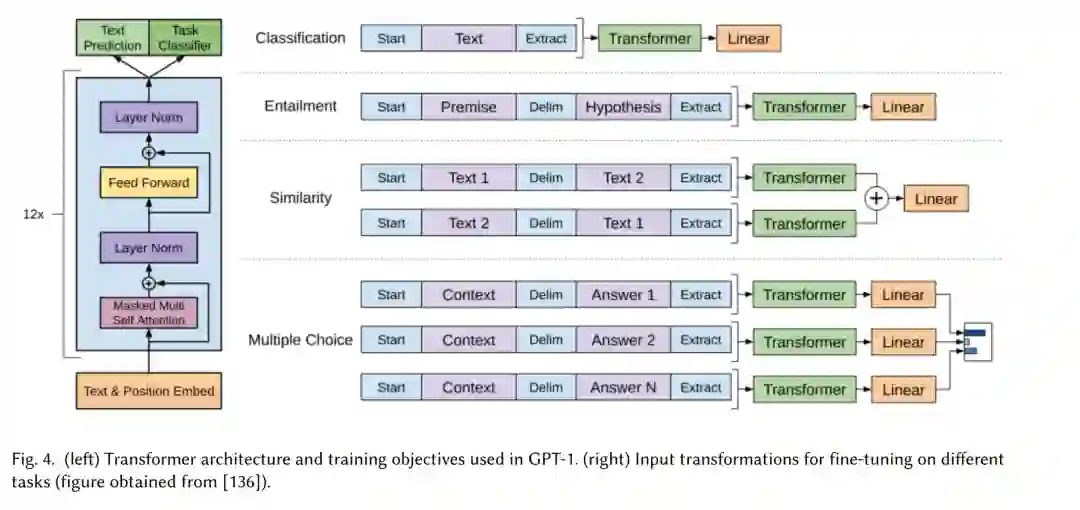
GPT-1。在只有解码器的情况下,GPT-1采用了12层的Transformer,具有117M的参数[136]。图4展示了GPT-1的概述以及如何将其用于各种下游任务。在包含独特未出版书籍的大型BooksCorpus数据集上进行训练,GPT-1能够掌握长程依赖关系的上下文。一般任务无关的GPT模型在12个任务中的9个中优于为特定任务训练的模型,包括自然语言推理、问答、语义相似性和文本分类[136]。观察到GPT-1在各种零样本任务上表现良好,表明了高水平的泛化能力。在GPT-2发布之前,GPT-1已经发展成为用于各种NLP任务的强大模型。
GPT-2。作为GPT-1的继承,GPT-2由OpenAI于2019年推出,专注于在没有明确监督的情况下学习NLP任务。与GPT-1类似,GPT-2基于仅解码器的Transformer模型。然而,GPT-2的模型架构和实现已经开发出来,具有15亿个参数和800万个网页的训练数据集,这是其前身GPT-1的10倍以上[137]。在零样本设置下,GPT-2在测试的8个语言建模数据集中的7个上取得了最先进的结果,其中7个数据集的任务包括对不同类别单词的性能识别、模型捕捉长期依赖关系的能力、常识推理、阅读理解、摘要和翻译[137]。然而,GPT-2在问答任务上仍然表现不佳,这表明无监督模型GPT-2的能力有待提高[137]。
GPT-3。GPT-3的基础是Transformer架构,特别是GPT-2架构。与具有15亿个参数的GPT-2相比,GPT-3具有1750亿个参数、96个注意力层和3.2 M的批处理大小,大小[18]显著增加。GPT-3在各种各样的在线内容上进行训练,包括小说、论文和网站,使用语言建模,这是一种无监督学习,模型试图根据前面的单词猜测短语中的下一个单词。完成后,GPT-3可以使用监督学习在特定任务上进行微调,其中使用特定任务的较小数据集来训练模型,如文本补全或语言翻译。由于OpenAI的API[36],开发人员可以将GPT-3模型用于许多应用程序,包括聊天机器人、语言翻译和内容生产。API根据任务的规模和复杂程度提供不同的访问级别。与其他性能高度依赖微调的语言模型相比,GPT-3可以执行许多任务(如语言翻译),而无需任何此类微调、梯度或参数更新,使该模型与任务无关[105]。
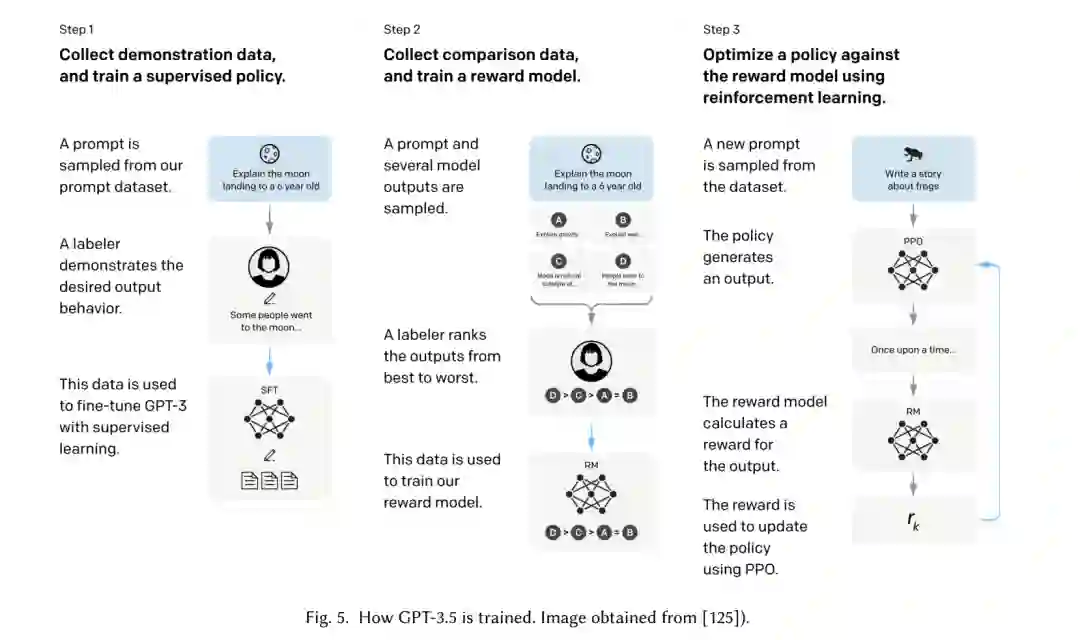
GPT-3.5。GPT-3.5是广泛流行的GPT-3的变体,ChatGPT是GPT-3.5的微调版本。在GPT-3模型之上,GPT-3.5具有额外的微调程序:有监督的微调和人工反馈的强化学习(RLHF)[203],如图5所示,其中机器学习算法接收用户反馈并使用它们来对齐模型。RLHF用于克服传统无监督和有监督学习只能从无标记或有标记数据中学习的局限性。人工反馈可以采取不同的形式,包括惩罚或奖励模型的行为,为未标记的数据分配标签,或更改模型参数。通过将人工反馈纳入训练过程,GPT-3.5的可用性显著提高。
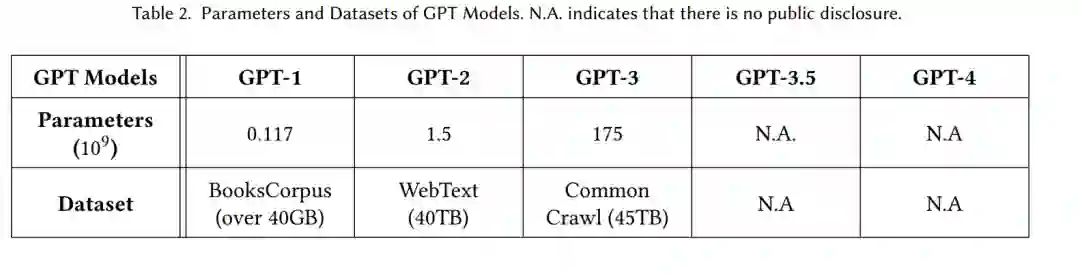
GPT-4。2023年3月14日,OpenAI发布了GPT-4[122],这是GPT系列的第四部分。GPT-4是一个大型多模态模型,能够将文本和图像作为输入,并生成文本作为输出。该模型在几个专业和职业标准上提供了人类水平的性能,但在现实世界中,它仍然比人类的能力弱得多。例如,GPT-4的虚拟律师考试成绩位于测试参与者的前10%,而GPT-3.5的分数位于最低的10%[77]。GPT-4遵循人类意图的能力明显优于早期版本[125]。在提供给ChatGPT和OpenAI API的样本中,5214个问题中,GPT-4的答案在70.2%的情况下优于GPT-3.5。在绝大多数预训练数据于2021年9月结束后,GPT-4通常对发生了什么缺乏意识,也没有从经验中学习。它偶尔会表现出基本的逻辑错误,这些错误似乎与它在各个领域的技能不一致,或者当从用户那里接受错误的声明时,它可能过度信任用户[122]。它可能会像人们一样与复杂的问题作斗争,例如生成包含安全缺陷的代码[122]。表2总结了从v1到v4的GPT模型参数和训练数据集。
4 ChatGPT的应用
4.1 科技写作
ChatGPT以其强大的内容生成能力而被广泛认可,对学术领域的写作产生了重大影响。许多现有的工作已经测试了ChatGPT如何应用于科学写作,包括头脑风暴、文献综述、数据分析、直接内容生成、语法检查以及作为学术评审员。
头脑风暴。头脑风暴是获得初始想法的基本方法,是高质量科学研究的先决条件。ChatGPT可以在头脑风暴中发挥各种作用,从激发创造力[57,139]产生新想法,到提供建议[98,168]扩展现有想法。ChatGPT可以帮助用户进行发散性和创造性思维[139]。此外,一些研究以问答的形式探讨了ChatGPT对未来护理研究的见解,可以分析未来技术发展对护理实践的影响,并为护士、患者和医疗保健系统[57]提供有价值的见解。此外,ChatGPT还表现出多角度“思考”的能力,它可以从医疗系统、社会经济、个人健康行为等多个维度分析和反思COVID-19大流行后超额死亡的影响[168]。评估ChatGPT是否能为特定领域的研究人员提供有用的建议。作者在[98]中测试了它在临床决策支持方面的能力,并评估了它与人工建议的差异。测试结果表明,与人类思维不同,ChatGPT生成的建议具有独特的视角,其生成的建议具有高度的可理解性和相关性,在科学研究中具有重要价值。
文献综述。一篇全面的文献综述需要涵盖所有的相关研究,这会耗费研究者太多的时间和精力。例如,基于人工智能的科学文献研究工具语义学者搜索引擎(Semantic Scholar search engine)已经索引了2亿多份学术出版物。因此,找到相关的研究论文并从中提取关键见解几乎是大海捞针。幸运的是,ChatGPT作为一个人工智能驱动的研究阅读工具,可以帮助我们浏览大量的论文并理解其内容。在实际使用中,我们可以给ChatGPT一个主题,然后它可以帮助我们查找相关文献。在讨论ChatGPT处理文献综述的能力之前,我们回顾了一个类似的AI工具SciSpace Copilot,它可以帮助研究人员快速浏览和理解论文[152]。具体来说,它可以为科学文本和数学提供解释,包括后续问题,以多种语言提供更详细的答案,促进更好的阅读和理解文本。相比之下,ChatGPT作为一种通用语言模型,不仅具有SciSpace Copilot的所有功能,而且可以广泛应用于各种自然语言处理场景[152]。为了总结所选领域的相关工作,文献综述是必不可少的。作为一项探索性任务,他们选择了“医疗领域的数字孪生”主题,并使用关键词“医疗领域的数字孪生”汇编了过去三年(2020、2021和2022)从谷歌学者搜索结果中获得的论文摘要。然后用ChatGPT对这些摘要进行转述,生成的结果具有良好的[7]性能。然而,ChatGPT在这项任务中的应用还处于起步阶段。[59]的作者要求ChatGPT提供10篇医学领域DOIs的开创性学术文章。不幸的是,在进行了5次测试之后,结果显示,在提供的50个doi中,只有8个存在,并且已经正确地发布。虽然ChatGPT在文献综述方面的能力还比较薄弱,但我们相信在不久的将来,ChatGPT将被广泛用于文献综述,进一步提高研究人员的效率,使他们能够将时间集中在重点研究上。
数据分析。科学数据需要在分析之前进行清理和组织,这通常需要花费研究人员几天甚至几个月的时间,最重要的是,在某些情况下,必须学习使用Python或r等编程语言。使用ChatGPT进行数据处理可以改变研究前景。例如,如[102]所示,ChatGPT完成了对一个模拟数据集的数据分析任务,该数据集包含10万名年龄和风险分布不同的医疗工作者,以帮助确定疫苗的有效性,这大大加快了研究过程[102]。[152]中讨论了另一个类似的用于数据分析的人工智能工具,其中基于人工智能的电子表格机器人可以将自然语言指令转换为电子表格公式。此外,像Olli这样的平台还可以可视化数据,用户只需要简单地描述所需的内容,然后他们可以得到人工智能创建的折线图、柱状图和散点图。考虑到ChatGPT是目前为止最强大的人工智能工具,我们相信这些功能也可以在ChatGPT中以更智能的方式实现。
内容生成。许多工作尝试使用ChatGPT为他们的文章生成内容[3,146]。例如,[3]利用ChatGPT辅助撰写两种疾病的发病机制的医学报告。具体来说,ChatGPT提供了三方面关于同型半胱氨酸血症相关骨质疏松的机制,所有这些都被证明是正确的。然而,当涉及到生成信息的参考文献时,ChatGPT所提到的论文并不存在。[223]描述了一项使用ChatGPT编写催化综述文章的研究,主题设置为CO2加氢生成高级醇。chatgpt生成的内容包括论文的必要部分,但缺乏对反应机制的介绍,这对该主题至关重要。这篇文章的内容包含了大量有用的信息,但缺少具体的细节,存在一定的错误。此外,ChatGPT可以帮助准备稿件,但生成的结果与实际发表的内容相差较大。一个可能的原因是ChatGPT的关键词与人工生成的文本差异很大,这就需要用户对生成的内容进行进一步的编辑[88]。ChatGPT还被用于生成特定领域的综述文章,如健康领域[7],这表明学者可以专注于核心研究,而将创造性较低的部分留给AI工具。然而,考虑到人工生成的内容和ChatGPT生成的内容之间的风格差异,[7,88]建议不要完全依赖ChatGPT。利用ChatGPT作为助手来帮助我们完成写作,而不是仅仅依赖它。
校对。在ChatGPT出现之前,有很多语法检查工具。一些工作[82,109,197]对语法和拼写校对进行了测试,表明ChatGPT提供了比其他AI工具更好的用户体验。例如,ChatGPT可以自动修复任何标点和语法错误,以提高写作质量[197]。此外,该研究还研究了ChatGPT如何超越帮助用户检查语法的范围,进一步生成关于文档统计、词汇统计等报告,改变作品的语言,使其适合任何年龄的人,甚至将其改编为故事[82]。另一个次要但值得注意的是,到目前为止,Grammarly的高级版本Grammarly Premium需要用户每月支付30美元的费用,这比ChatGPT Plus每月20美元的费用要贵得多。此外,ChatGPT已经与其他基于人工智能的语法检查器进行了比较,包括QuillBot、DeepL、DeepL Write和谷歌Docs。实验结果表明,ChatGPT在错误检测数量方面表现最好。虽然ChatGPT在校对时存在一些可用性问题,例如比DeepL慢10倍以上,并且缺乏突出建议或为特定单词或短语提供替代选项的能力[109],但应该注意的是,语法检查只是冰山一角。ChatGPT在改进语言、重构文本和写作的其他方面也很有价值。
学术评审。研究论文的同行评议是传播新思想的一个关键过程,对科学进步有重大影响。然而,产生的研究论文的数量给人类评审者带来了挑战。[161]对ChatGPT用于文献综述的潜力进行了研究。具体来说,ChatGPT能够对输入的学术论文进行分析,然后从论文的概述、优缺点、清晰度、质量、新颖性、可重复性等方面对论文进行评价。然后,将论文生成的评论输入ChatGPT进行情感分析。在此之后,可以对接受评审的论文做出决定。
4.2 教育领域
ChatGPT具有产生类似人类的响应的能力,已经被许多研究工作所研究,以探讨它给教育领域带来的影响。在这里,我们从两个角度对它们进行总结:教/学和学科。
教与学。在典型的课堂环境中,教师是知识的来源,而学生是知识的接受者。在课堂之外,学生经常被要求完成老师设计的作业。ChatGPT可以显著改变教师和学生之间的交互方式[10,148,209,211]。
各种教育科目的ChatGPT。在现代教育中,有各种各样的学科,包括经济学、法学、物理学、数据科学、数学、体育、心理学、工程学和媒体教育等。尽管ChatGPT并不是专门为成为某一特定主题的大师而设计的,但在众多的作品中已经证明,ChatGPT对某一主题的理解还不错,有时甚至超越了人类的水平。为了方便讨论,我们将主题分为STEM(科学、技术、工程、数学)和非STEM(包括经济学、法学、心理学等)。
4.3 医疗领域
医学知识评估。ChatGPT在医疗领域的能力已经在一些工作中得到了评估[43,53,72,205]。疾病诊断和治疗。虽然一些机器学习算法已被应用于辅助疾病分析,但大多数情况下主要局限于与单任务相关的图像判读。在这一部分,我们讨论ChatGPT在临床决策支持中的能力。
5 挑战
5.1 技术局限
尽管ChatGPT功能强大,但它也有自己的缺点,这也是OpenAI团队官方认可的。为了证明其局限性,已经进行了大量的工作[15,16,26,60,96,151,226],总结如下:
不正确。ChatGPT有时会生成看似合理的错误或无意义的答案,就像一本正经地胡说八道[16]。也就是说,ChatGPT提供的答案并不总是可靠的[15,16,226]。正如OpenAI所认识到的,这个问题是具有挑战性的,一个主要原因是目前的模型训练依赖于监督训练和强化学习,以使语言模型与指令保持一致。因此,模型模仿人类演示者听起来很有道理,但往往以正确性为代价。事实错误相关的问题在ChatGPT plus版本中得到了缓解,但这个问题仍然存在[122]。
不合逻辑。在[16,60,151]中指出,ChatGPT的逻辑推理能力还有待提高。由于ChatGPT缺乏理性的人类思维,它既不能“思考”,也不能“推理”,因此未能通过图灵测试[60]。ChatGPT仅仅是一个复杂的统计模型,无法理解自己或对方的话,也无法回答深入的问题[151]。此外,ChatGPT缺乏一个“世界模型”来进行空间、时间或物理推理,或预测和解释人类的行为和心理过程[16],在数学和算术方面也有局限,无法解决困难的数学问题或谜语,甚至可能在一些简单的计算任务[16]中得到不准确的结果。
不一致。当用相同的提示输入给模型喂食时,ChatGPT可以产生两个不同的输出,这表明ChatGPT具有不一致的局限性。此外,ChatGPT对输入提示高度敏感,这激发了一群研究人员对提示工程的研究。一个好的提示可以提高系统综述性文献搜索的查询效率[191]。利用关于软件开发任务的有效目录和指导等提示模式,可以进一步提高软件开发任务自动化的效率[193,194]。尽管在为ChatGPT发现更好的提示方面取得了进展,但简单地改变提示可以产生显著不同的输出这一事实,意味着ChatGPT需要提高其鲁棒性。
无意识。ChatGPT不具备自我意识[16],虽然它可以回答各种问题,生成看似相关连贯的文本,但它没有意识,没有自我意识,没有情绪,也没有任何主观经验。比如ChatGPT可以理解和创造幽默,但是它不能体验情感或者主观体验[16]。关于自我意识,目前还没有一个被广泛接受的定义,也没有可靠的测试方法。一些研究者建议从某些行为或活动模式推断自我意识,而另一些人则认为这是一种主观体验,无法客观地测量[16]。机器究竟是真正拥有自我意识,还是只能模拟自我意识,目前还不清楚。
6. 展望
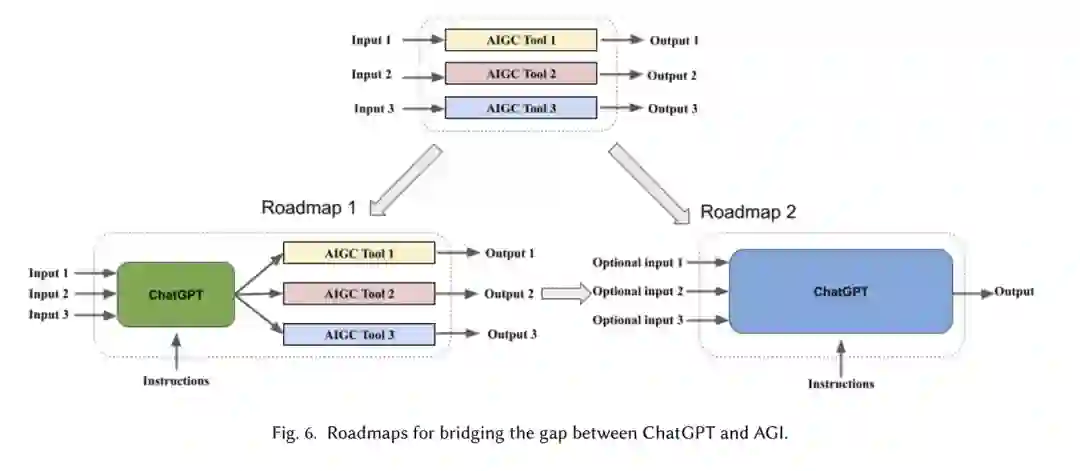
在这个蓬勃发展的生成AI时代,有大量的AIGC工具用于各种生成任务,包括text-to- text [12, 75, 117, 138, 200], text-to-image[106, 144, 166, 199, 219],图像描述[68,187,202],text-to-speech[85, 145, 167],语音识别[93,97,126,155,190],视频生成[66,108,116,201],3D生成[67,114]等。尽管具有令人印象深刻的功能,但在[55]中指出,ChatGPT并不是生成式AI所需要的全部。从输入输出的角度来看,ChatGPT主要擅长文本到文本的任务。随着底层语言模型从GPT-3.5进化到GPT-4,加号版ChatGPT在输入端增加了模态。具体来说,它可以选择性地将图像作为输入,但是,它仍然不能处理视频或其他数据模态。在输出端,GPT-4仍然局限于生成文本,这使得它与通用的AIGC工具相距甚远。很多人都想知道下一代GPT可能会实现什么[8,19]。一个极有可能的情况是,ChatGPT可能会走向通用型AIGC,这将是实现人工通用智能(AGI)[19]的一个重要里程碑。
实现这样的通用AIGC的一种天真的方式是,以并行的方式将各种AIGC工具集成到一个共享agent中。这种朴素方法的一个主要缺点是不同的AIGC任务之间没有交互。在查阅了大量文章后,我们推测可能存在两种将ChatGPT桥接并推向AGI的路线图。因此,我们主张一个共同的景观,实现多元化AIGC模式之间的互联互通。