在2023年3月,我们发表了大语言模型综述文章《A Survey of Large Language Models》。这篇综述文章已经更新到第13个版本,包含了83页的正文内容,并收录了900余篇参考文献。该综述文章旨在系统地梳理大语言模型的研究进展与核心技术,讨论了大量的相关工作。自大语言模型综述的预印本上线以来,受到了不少读者的关注。

自英文综述文章上线后,陆续有读者询问是否有对应的中文版本。为此,我们于2023年8月发布了该综述的中文翻译版。为了更好地提供大模型技术的中文参考资料,我们于2023年12月底继续启动了中文书的编写工作,并且于近日完成初稿。与英文综述文章的定位不同,中文版书籍更注重为大模型技术的入门读者提供讲解,为此我们在内容上进行了大幅度的更新与重组,力图展现一个整体的大模型技术框架和路线图。本书适用于具有深度学习基础的高年级本科生以及低年级研究生使用,可以作为一本入门级的技术书籍。
中文书项目链接:

中文书下载链接1:
****https://github.com/LLMBook-zh/LLMBook-zh.github.io/blob/main/LLMBook.pdf
中文书下载链接2:
********http://aibox.ruc.edu.cn/zws/index.htm
全书章节组织:
一、背景与基础知识
第一章 引言(大模型发展历程、重要技术概览) 第二章 基础介绍(Scaling Law、GPT系列模型发展历程) 第三章 大模型资源(开源模型、数据、代码库) 二、预训练
第四章 数据准备(数据收集、清洗、配比、课程方法) 第五章 模型架构(Transformer 结构、大模型主流架构、细节改进) 第六章 模型预训练(预训练任务、优化参数设置、并行训练方法) 三、微调与对齐
第七章 指令微调(指令数据收集与合成方法、指令微调策略与作用) 第八章 人类对齐(3H标准、RLHF算法、非RL算法) 四、大模型使用
第九章 解码与部署(解码生成算法、解码加速算法、模型压缩算法) 第十章 提示学习(基础提示方法、上下文学习、思维链) 第十一章 规划与智能体(复杂规划方法、智能体搭建方法) 五、评测与应用
第十二章 评测(评测指标与方法、基础与高级能力评测、评测体系) 第十三章 应用(概览研究领域与专业领域的应用)
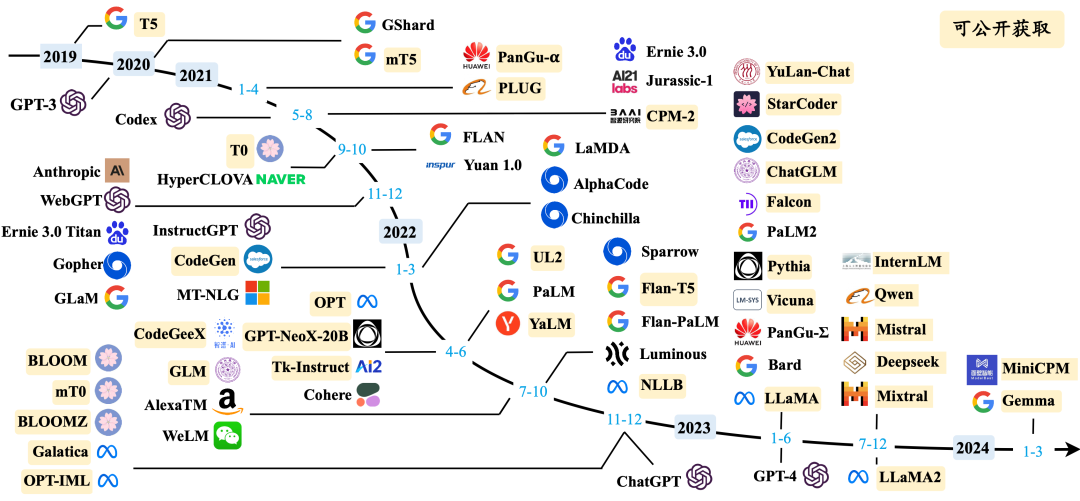
大语言模型发展时间线
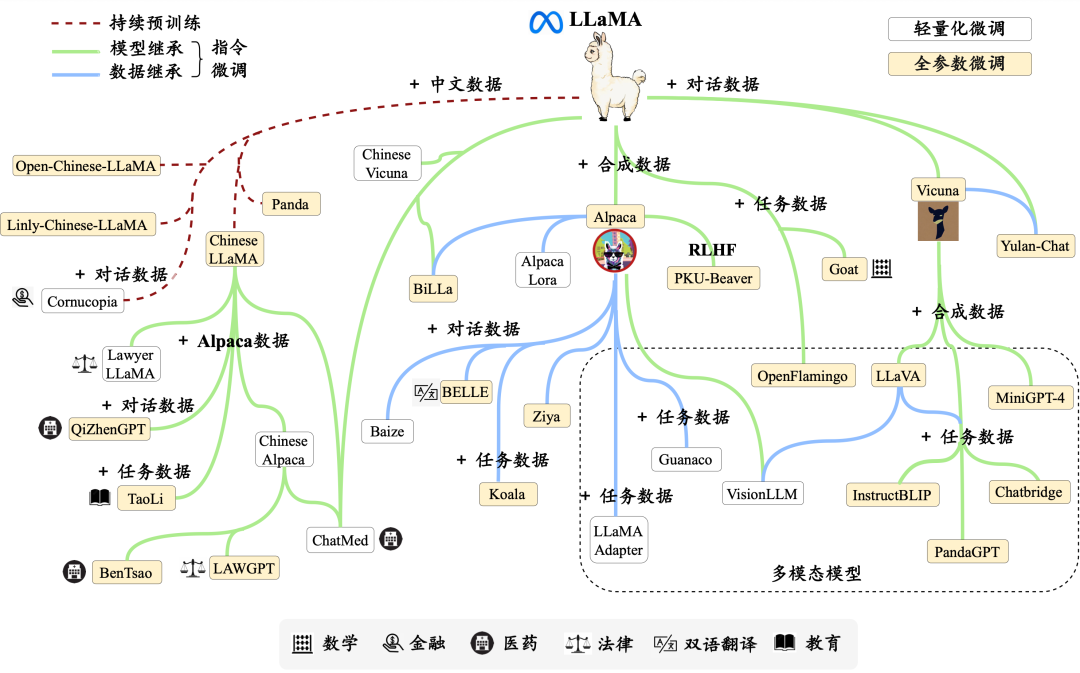
LLaMA 系列模型的衍生工作进化图
在本书撰写过程中,我们收到了来自许多同行的大量修改意见,在此一并表示感谢,希望大家一如既往支持与关注我们的大模型中文书,您的支持与反馈将是我们前行最大的动力。本书的初版仅是一个起点,我们计划在网上持续进行内容的更新和完善,并特别欢迎读者提出宝贵的批评与建议,也会同步在网站上对于提出宝贵建议的读者进行致谢。如果您有任何意见、评论以及建议,请通过GitHub的Issue页面(https://github.com/LLMBook-zh/LLMBook-zh.github.io/issues)或邮箱进行反馈。
为了更好地整理和传播大模型技术的最新进展与技术体系,我们为读者提供了以下配套资源,供读者在阅读本书时进行参考和使用。
**大模型代码工具库:**我们开发了一个全面的代码工具库LLMBox,专门用于开发和实现大语言模型,其基于统一化的训练流程和全面的模型评估框架。LLMBox旨在成为训练和利用大语言模型的一站式解决方案,其内部集成了大量实用的功能,实现了训练和利用阶段高度的灵活性和效率。工具库链接:https://github.com/RUCAIBox/LLMBox。

**
**
**YuLan大模型:**YuLan系列模型是中国人民大学高瓴人工智能学院师生共同开发的支持聊天的大语言模型(名字“玉兰”取自中国人民大学校花)。最新版本从头完成了整个预训练过程,并采用课程学习技术基于中英文双语数据进行有监督微调,包括高质量指令和人类偏好数据。模型链接:https://github.com/RUC-GSAI/YuLan-Chat。

**
**
本书各章节的主要负责人和参与人名单如下:
第三章的负责人是闵映乾和杨晨,参与人有李军毅、周昆; * 第四章的负责人是张君杰、侯宇蓬和周昆; * 第五章的负责人是董梓灿,参与人有田震和唐天一; * 第六章的负责人是唐天一和陈昱硕; * 第七章的负责人是唐天一,参与人有成晓雪; * 第八章的负责人是李军毅和陈志朋; * 第九章的负责人是陈昱硕、刘沛羽和唐天一,参与人有周昆; * 第十章的负责人是李军毅、汤昕宇和都一凡; * 第十一章的负责人是任瑞阳和蒋锦昊,参与人有李军毅; * 第十二章的负责人是张北辰和周昆,参与人有张高玮; * 第十三章的负责人是周昆,参与人(按拼音字母排序)有蒋锦昊、李依凡、刘子康、孙文奇、王禹淏、徐澜玲、杨锦霞和郑博文。
同时感谢其他所有参与本书编写、校对的同学和老师们。