

2022 年 11 月,ChatGPT 的问世展示了大语言模型的强大潜能,并迅速引起了广泛关注。ChatGPT 能够有效理解用户需求,并根据上下文提供恰当的回答。它不仅可以进行日常对话,还能够完成复杂任务,如撰写文章、回答问题等。令人惊讶的是,所有这些任务都由一个模型完成。在许多任务上,ChatGPT 的性能甚至超过了针对单一任务进行训练的有监督算法。这对于人工智能领域具有重大意义,并对自然语言处理研究产生了深远影响。
然而,由于 OpenAI 并未公开 ChatGPT 的详细实现细节,整体训练过程包括语言模型、有监督微调、类人对齐等多个方面,这些方面之间还存在大量的关联,这对于研究人员在自然语言处理基础理论和机器学习基础理论上要求很高。此外,大语言模型的参数量非常庞大,与传统的自然语言处理研究范式完全不同。使用大语言模 型还需要分布式并行计算的支持,这对自然语言处理算法研究人员又进一步提高了要求。
为了使得更多的自然语言处理研究人员和对大语言模型感兴趣的读者能够快速了解大语言模型和理论基础,并开展大语言模型实践,复旦大学自然语言处理实验室张奇教授、桂韬研究员、郑锐博士生以及黄萱菁教授结合之前在自然语言处理领域研究经验,以及分布式系统和并行计算的教学经验,通过在大语言模型实践和理论研究的过程中,历时 8 个月完成本书。希望这本书能够帮助读者快速入门大语言模型的研究和应用,并解决相关技术挑战。
点击 阅读原文 或访问 https://intro-llm.github.io/ 获取本书全文

条分缕析,梳理大规模预训练技术路线
《大规模语言模型·从理论到实践》旨在为对大语言模型感兴趣的读者提供一个入门指南,并可作为高年级本科生和研究生自然语言处理相关课程的大语言模型部分补充教材。鉴于大语言模型的研究仍在快速发展阶段,许多方面尚未达成完整结论或普遍共识。在撰写本书时,我们力求全面展现大模型研究的各个方面,并避免给出没有广泛共识的观点和结论。大语言模型涉及深度学习、自然语言处理、分布式计算、分布式计算等众多领域。因此,建议读者在阅读本书之前,首先系统地学习深度学习和自然语言处理的相关课程。在分布式计算和异构计算方面,读者需要具备基本的概念。如果希望在大语言模型训练和推理方面进行深入研究,还需要系统学习分布式系统、并行计算、CUDA 编程等相关知识。
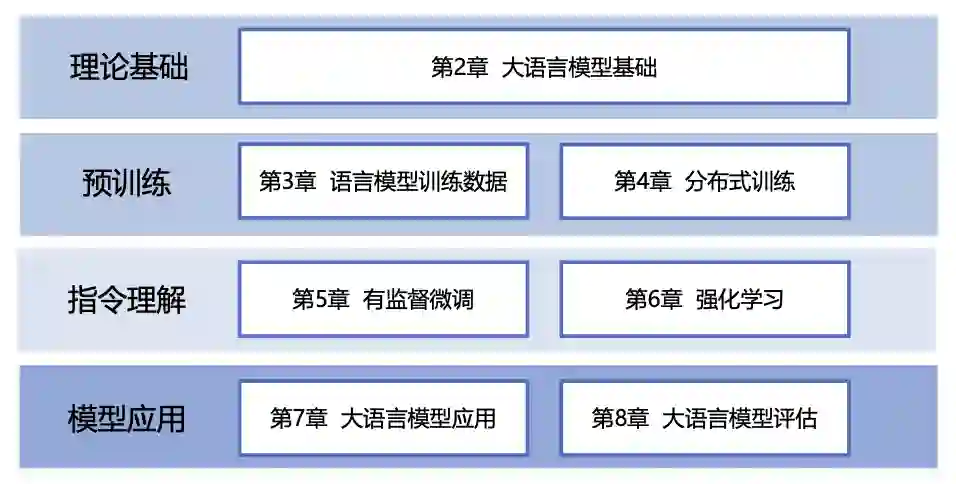
本书围绕大语言模型构建的四个主要阶段:预训练、有监督微调、奖励建模和强化学习,详细介绍各阶段使用的算法、数据、难点以及实践经验。

预训练阶段需要利用包含数千亿甚至数万亿单词的训练数据,并借助由数千块高性能 GPU 和高速网络组成的超级计算机,花费数十天完成深度神经网络参数的训练。这一阶段的核心难点在于如何构建训练数据以及如何高效地进行分布式训练。
有监督微调阶段利用少量高质量的数据集,其中包含用户输入的提示词(Prompt)和对应的理想输出结果。提示词可以是问题、闲聊对话、任务指令等多种形式和任务。这个阶段是从语言模型向对话模型转变的关键,其核心难点在于如何构建训练数据,包括训练数据内部多个任务之间的关系、训练数据与预训练之间的关系以及训练数据的规模。 奖励建模阶段的目标是构建一个文本质量对比模型,用于对于同一个提示词,对有监督微调模型给出的多个不同输出结果进行质量排序。这一阶段的核心难点在于如何限定奖励模型的应用范围以及如何构建训练数据。 强化学习阶段根据数十万提示词,利用前一阶段训练的奖励模型,对有监督微调模型对用户提示词补全结果的质量进行评估,并与语言模型建模目标综合得到更好的效果。这一阶段的难点在于解决强化学习方法稳定性不高、超参数众多以及模型收敛困难等问题。 除了大语言模型的构建,本书还进一步介绍了大语言模型的应用和评估方法。主要内容包括如何将大语言模型与外部工具和知识源进行连接、如何利用大语言模型进行自动规划完成复杂任务,以及针对大语言模型的各类评估方法。

It's Just the Beginning
虽然本书写作时间只有 8 个月,但是章节内部结构也是几易其稿,经过几次大幅度调整和重写。受限于我们的认知水平和所从事的研究工作的局限,对其中一些任务和工作的细节理解可能存在不少错误,也恳请专家、读者批评指正!
转发福利
点击转发并获赞满50个
截图加微信:Dreams21111617
并注明“集赞满50以上”
前10名可免费获得签名版纸质《自然语言处理导论》!

责任编辑:窦士涵、刘妍


