

https://link.springer.com/book/10.1007/978-3-319-73531-3
文本分析是一个集信息检索、机器学习和自然语言处理于一体的领域。这本书仔细地涵盖了一个条理清晰的框架。
从这些交叉的主题。本书的章节涵盖了三大类:
-
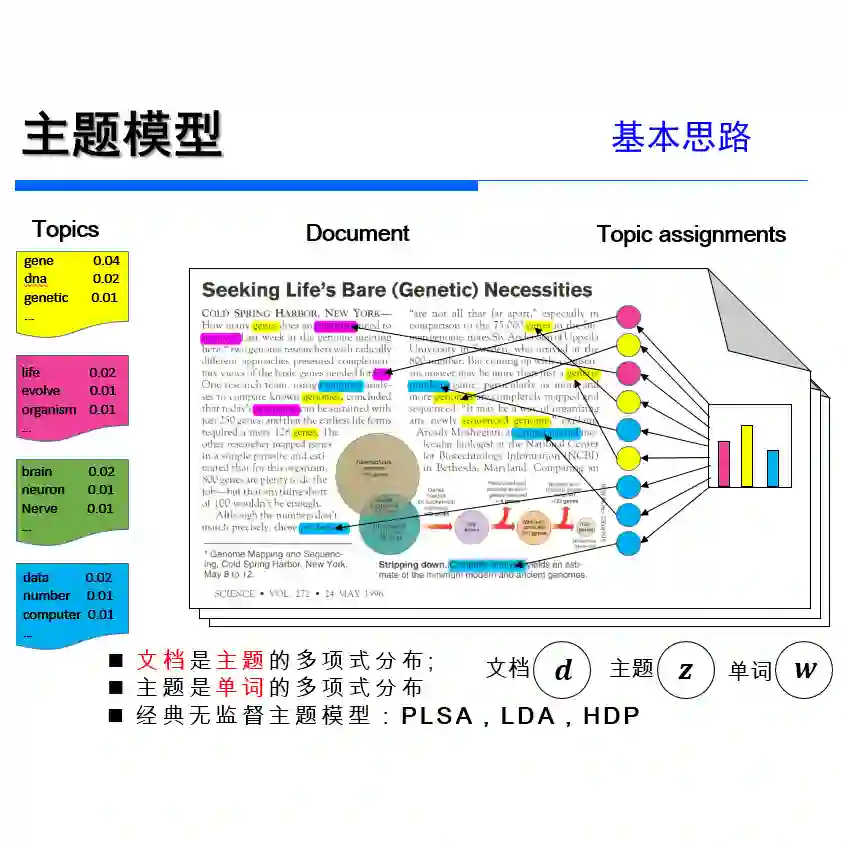
基本算法:第1章到第8章讨论了文本分析的经典算法,如预处理、相似度计算、主题建模、矩阵分解、聚类、分类、回归和集成分析。
-
领域敏感学习:第8章和第9章讨论了异类设置下的学习模型,例如文本与多媒体或Web链接的组合。本文还讨论了信息检索和Web搜索问题与排序和机器学习方法的关系。
3.以序列为中心的挖掘:第10章到第14章讨论了各种以序列为中心的和自然语言的应用,如特征工程、神经语言模型、深度学习、文本摘要、信息提取、意见挖掘、文本分割和事件检测。
这本书涵盖了从简单到高级的文本分析和机器学习主题。
由于内容广泛,同一本书可以提供多种课程,
成为VIP会员查看完整内容

相关主题


相关VIP内容
相关资讯
相关论文