■Sora是文生视频的集大成者,核心创新点在于时空编码和DiT模型。
Sora是Open AI推出的首个文本生视频模型,视频生成长度、逼真度等均远超现有竞品。从技术上看,Sora的核心创新点在于时空编码和Diffusion Transformer模型的应用。1)Spacetime patches时空编码将一个完整视频切分成带有时间维度的一系列Tokens输入Transformer模型,时空编码的引入是Sora能够进行大规模视频数据训练的关键,同时为Sora的生成结果具备三维一致性奠定了基础。2)DiT模型结合了Diffusion扩散模型和Transformer模型的优点,将传统扩散模型中采用的U-Net网络结构替换成Transformer,使得模型更擅长捕捉长距离的相关关系。
■ Sora验证了Diffusion+Transformer的技术路线或是通往世界模型的有效技术路径。
神经网络模型的预测结果是概率输出,目前尚不具备因果关系的推断能力,因此推理结果可能会出现常识错误或者违背现实物理规律。而学界提出的世界模型概念旨在希望神经网络模型可以像人类一样理解世界,具体可概括为具备以下三个特点:1)理解物理世界运行规律,像人一样具备常识。2)具备泛化到训练样本以外的能力。3)可以基于记忆进行自我演进。目前关于世界模型的技术路径尚有争议,但从Open AI的官方展示视频来看,Sora已经具备了世界模型的雏形,对于真实物理世界有一定的模拟能力。因此我们认为Sora采用的Diffusion+Transformer的技术路线或许是通往世界模型的有效技术路径。
■特斯拉同样基于与Sora相似的技术路径已开始对于世界模型的探索。
早在2023年6月召开的CVPR会议上,特斯拉已经分享了对于世界模型的探索,Demo展示效果效果惊艳:1)可以同时对车身周围八个摄像头周围未来情况进行预测;2)可以精准的模拟过去难以描述的场景(如烟尘);3)可以根据动作指令调节;4)可以用来做分割任务。根据特斯拉CVPR上的演讲及马斯克推特的公开回复,可以推断特斯拉大概率和Open AI一样采用的是Diffusion+Transformer生成式AI的技术路线。而Sora的成功已经率先在AGI领域验证了这条技术路线的可行性,由此我们认为World Model应用于智能驾驶的时代亦将加速到来。
** ■ **世界模型中短期内应用于仿真环节,长期作为智驾基座大模型,引领行业迈向L5时代。
世界模型在智能驾驶中的应用有望最先在仿真环节落地,推动仿真场景泛化能力提升。当前智能驾驶仿真采用NeRF+素材库排列组合+游戏引擎的技术路线,虽然保证了场景的真实性但泛化性不足。世界模型能够理解物理世界运行规律、同时具备泛化到训练样本以外的能力,因此世界模型能够迅速生成非常真实和多样化的驾驶场景用于智能驾驶仿真。长期来看世界大模型有望成为智驾的基座大模型,所有的智能驾驶下游任务都可以通过简单的插入任务头来实现。届时,智能驾驶将不再存在corner case,智能驾驶的驾驶安全性、驾驶效率都将占优于人类驾驶员。
■风险提示:技术进步不及预期、市场竞争加剧。
目录

1 **Sora验证了DiT模型的有效性,**具备世界模型的雏形
**1.1 Sora是文生视频技术的集大成者,**核心创新点在于时空编码及DiT模型
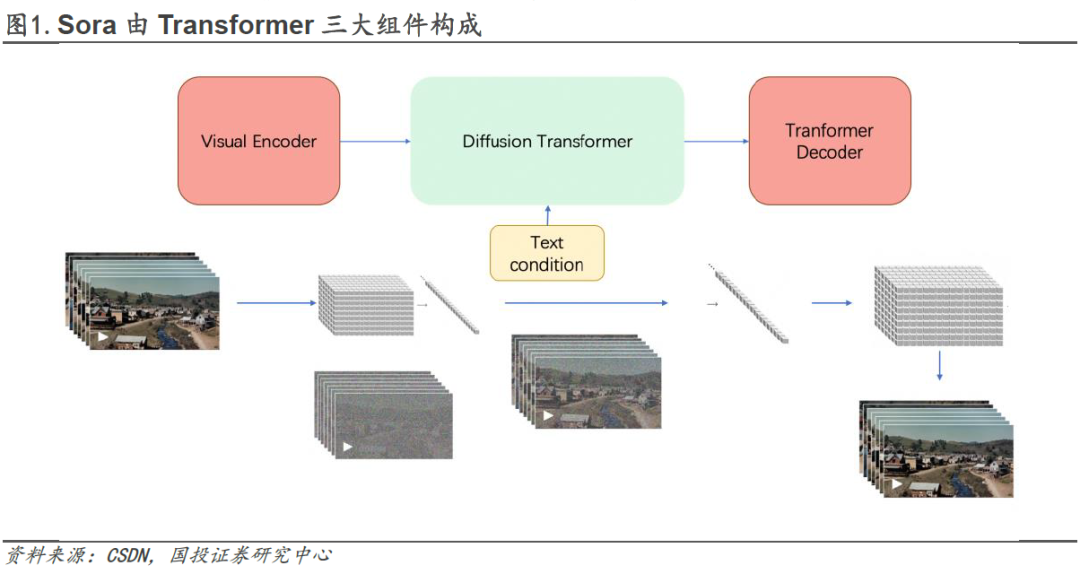
**Sora是Open AI推出的首个文生视频模型,效果远超现有竞品。**一方面Sora大幅提升了行业视频生成长度,Sora可一次性生成60s高质量视频,远超此前Pika的3秒、Runaway Gen2的16秒。并且Sora可在单个视频中进行多镜头切换,并保证了场景、物体在3D空间内的一致性。**从技术原理上看,Sora本质上依然是基于Transformer模型,由Transformer三大组件构成。**包括:1)Visual Encoder 模块:根本目的是将一个视频通过一系列操作进行Token化(即时空编码Spacetime patches);2)Diffusion Transformer模块:用于视频的生成;3)Transformer Decoder:将生成的潜在表示映射回像素空间。其中Sora的核心创新点在于时空编码和Diffusion Transformer模型的应用。(关于Transformer模型的分析解读可参考我们此前的报告《AI大模型在自动驾驶中的应用》)
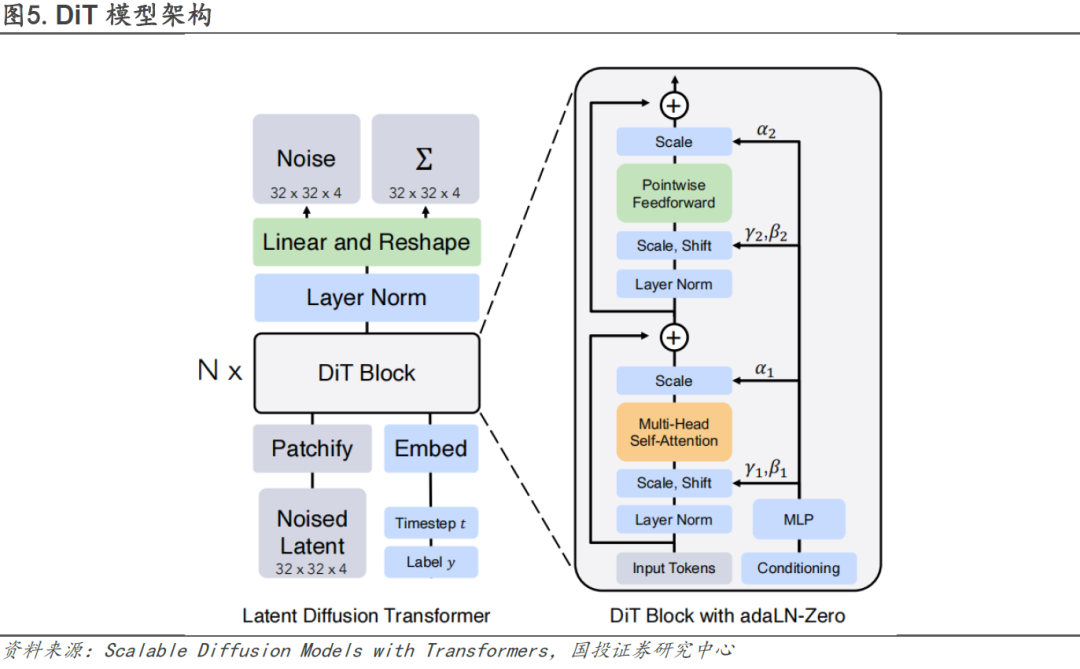
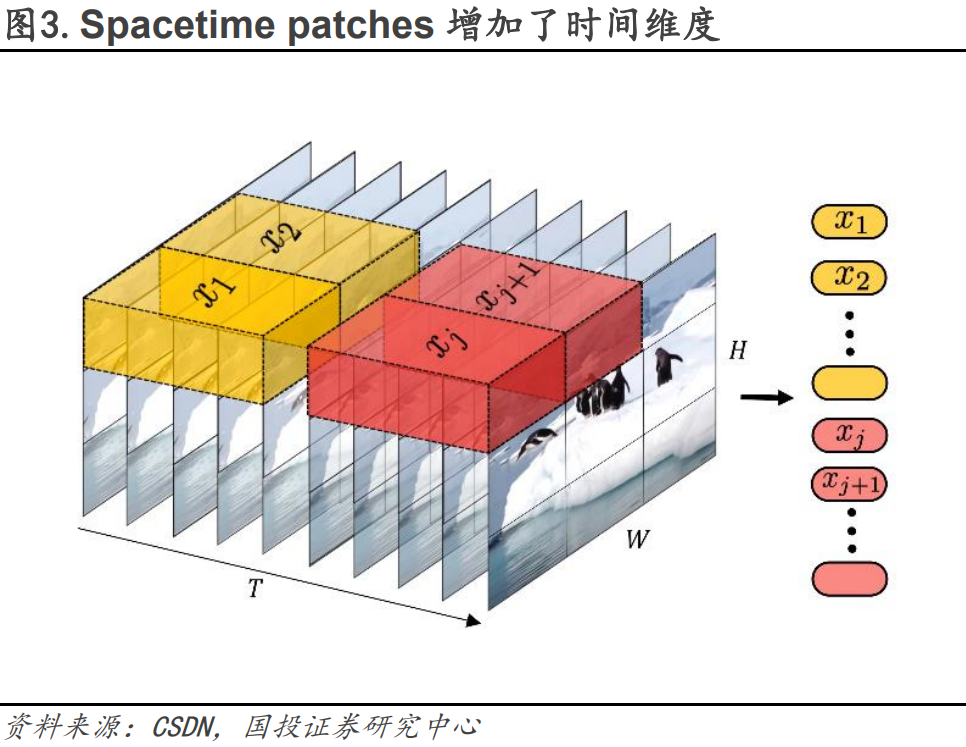
**Spacetime patches(时空编码)的引入是Sora能够进行大规模视频数据训练的关键,同时为Sora的生成结果具备三维一致性奠定了基础。**Open AI认为LLM范式的成功部分得益于对Tokens的使用,这些Token统一了代码、数学和各种自然语言等不同模态的文本,语言模型中的Token代表文本的最小单位,可以是单词、词组或者是标点符号等。将这个概念应用到视频领域,Sora引入了Spacetime patches(时空编码)作为视频的最小单位。Spacetime Patches技术建立在ViT(Vision Transformer)的研究基础之上。ViT模型的思路是将图片切成了多个Patches(小块,类似于九宫格),再拉平成一系列Tokens输入Transformer模型(目前自动驾驶行业中主流应用的“BEV+Transformer”也是以ViT为基础)。而Spacetime Patches在此基础上增加了时间维度,可以理解为Sora模型的一个Patch是一个小立方体。Spacetime patches的引入使得Sora高效地训练大体量的视频数据(包括各种时长、分辨率、长宽比的视频数据)。并且Spacetime patches保证了前后帧之间的强相关关系,为Sora的生成结果具备三维一致性奠定了基础。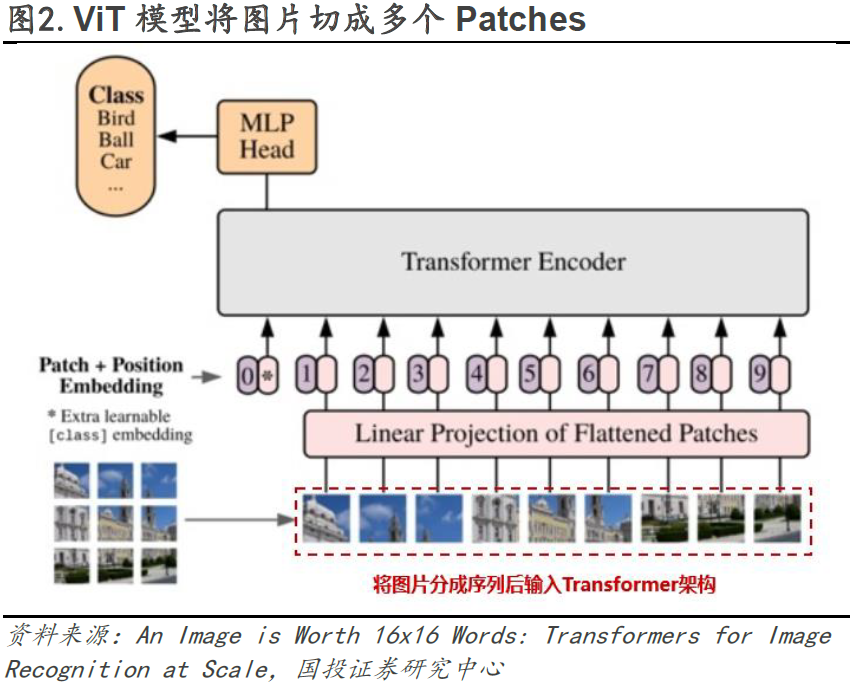
**DiT模型结合了Diffusion扩散模型和Transformer模型的优点。**Diffusion扩散模型本质作用,就是学习训练数据的分布,产出尽可能符合训练数据分布的真实图片。可以理解为根据文本指令或者有噪音的图片模型“脑补”出完整图片/视频。“脑补”过程的思路是,从清晰没有噪声的图像开始,每一步(timestep)都往上加一点噪声,得到噪声越来越大、越来越模糊的图像;同时在每一步里,都让模型根据当前步加噪后的图像去恢复出加噪前的图像,也就是让模型学会去噪(加噪后的图像作为输入,加噪前的图像作为监督的正确答案,模型本质上是根据加噪前后的图像来学习拟合所添加的噪声)。这样训练完毕后,模型就可以从一张纯噪声图像一步步还原出原始图片。在上述步骤里,一步步加噪的过程,就被称为Diffusion Process;一步步去噪的过程,就被称为Denoise Process。传统的Diffusion模型采用U-Net网络架构,本质上是卷积神经网络。Sora的创新之处在于用Transformer模型架构作为主干网络,通过Transformer来估测每一步加的噪音。这样做的好处在于将视频数据转换成Token之后,Transformer更擅长捕捉长距离的相关关系