

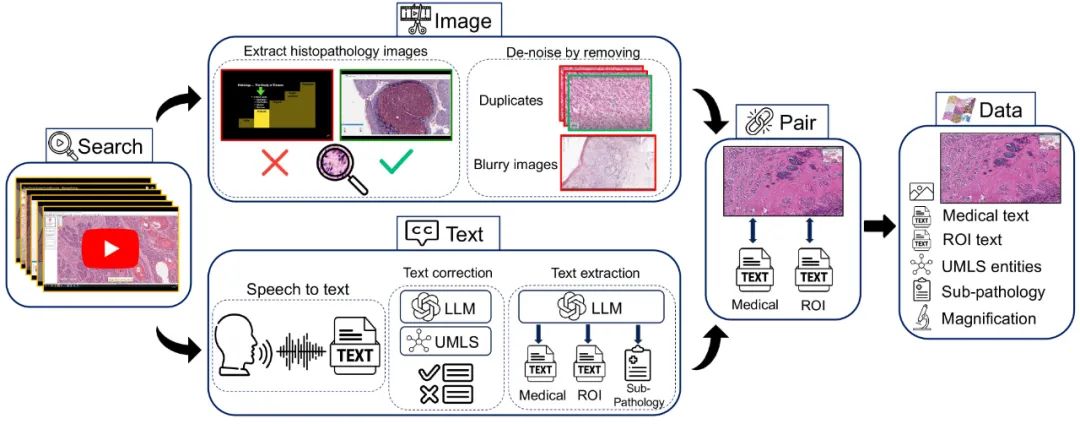
近期在多模态应用中的加速发展得益于线上大量的图像和文本数据。但是,在医学领域,特别是在组织病理学中,相似数据的稀缺性已经阻碍了类似的进展。为了在组织病理学中实现类似的表示学习,我们转向YouTube,这是一个尚未被充分利用的视频资源,提供了1,087小时来自专家临床医生的有价值的教育性组织病理学视频。从YouTube,我们策划了Quilt:一个大型的视觉-语言数据集,包括768,826对图像和文本。Quilt是使用各种模型(包括大型语言模型)、手工算法、人类知识数据库和自动语音识别自动策划的。相比之下,为组织病理学策划的最全面的数据集只有约200K样本。我们将Quilt与来自其他来源的数据集结合,包括Twitter、研究论文和互联网,创建了一个更大的数据集:Quilt-1M,它包括1M对图像-文本样本,使其成为迄今为止最大的视觉-语言组织病理学数据集。我们通过微调一个预训练的CLIP模型来展示Quilt-1M的价值。我们的模型在对13个不同的补丁级数据集的8种不同子病理学分类的零射击和线性探测任务,以及跨模态检索任务上均超过了最先进的模型。
成为VIP会员查看完整内容
相关内容
Arxiv
42+阅读 · 2023年4月19日
Arxiv
223+阅读 · 2023年4月7日
Arxiv
152+阅读 · 2023年3月29日
Arxiv
85+阅读 · 2023年3月21日
相关主题
相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
223+阅读 · 2023年4月7日
Arxiv
152+阅读 · 2023年3月29日
Arxiv
85+阅读 · 2023年3月21日