
© 作者|闵映乾 机构|中国人民大学研究方向|大语言模型 为了帮助开源社区共同研究类o1慢思考系统的实现方法,我们开源了在技术报告Imitate, Explore, and Self-Improve: A Reproduction Report on Slow-thinking Reasoning Systems中使用的训练数据和模型。 文章也同步发布在 AI Box 知乎专栏(知乎搜索 AI Box 专栏),欢迎大家在知乎专栏的文章下方评论留言,交流探讨!
资源简介
为了帮助开源社区共同研究类o1慢思考系统的实现方法,我们开源了在技术报告Imitate, Explore, and Self-Improve: A Reproduction Report on Slow-thinking Reasoning Systems中使用的训练数据和模型。
-
训练数据包括3.9K数学领域和1K混合领域(代码、科学和自然语言谜题)的长程思维链。其中3.9K数学领域数据有2.3K来自DeepSeek-R1,1.6K来自于QwQ(经过我们的模型改写成与R1同样的格式,详情参考论文);1K混合领域数据均来自于R1。
-
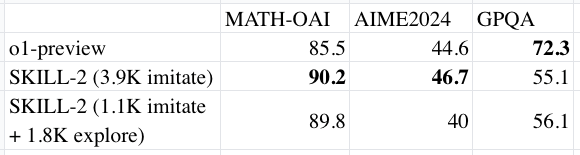
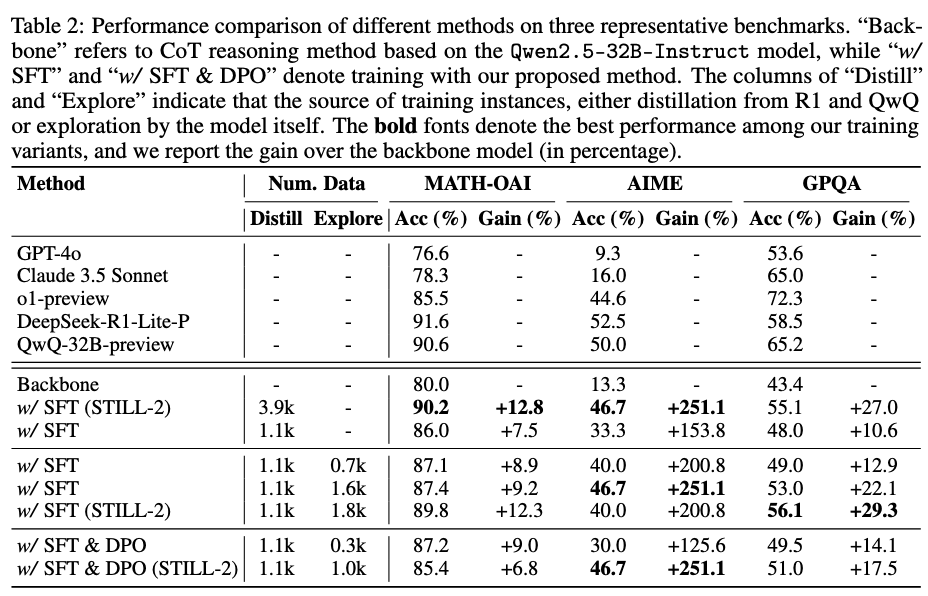
模型在选取的基准测试集达到了与o1-preview整体接近的效果。
通过使用模仿,探索,再自我改进的方式,我们发现:
- 通过使用少量高质量的示范数据进行训练,可以有效引导长时间思考的能力。一旦建立,这种能力似乎能够自然地跨领域泛化。
- 数学领域的示范数据特别适合提升大语言模型的长时间思考能力,而包含较长思考过程的数据在提升模型解决复杂问题的能力方面显得尤为有效。
- 与大语言模型在快速思考模式下生成的正式回应不同,思考过程通常以灵活、非正式的方式表达,旨在引导模型走向正确的解决路径。
- 通过探索和自我改进,可以有效增强慢思考能力,而离线学习方法的改进似乎主要发生在初始迭代中,尤其是在处理复杂任务时。
资源链接
- STILL-1: https://arxiv.org/abs/2411.11694
- STILL-2: https://arxiv.org/abs/2412.09413
- Github仓库(内含数据模型等相关资源): https://github.com/RUCAIBox/Slow_Thinking_with_LLMs
STILL: Slow Thinking with LLMs 项目进展回顾
近年来,类似于 OpenAI 的 o1 等慢思考(slow-thinking)推理系统在解决复杂推理任务方面展现了卓越的能力。这些系统在回答查询之前,经过较长时间的思考与推理,能够生成更加全面、准确且有理有据的解决方案。然而,这些系统主要由工业界开发和维护,其核心技术尚未公开披露。因此,越来越多的研究工作开始致力于探索这些强大推理系统背后的技术基础。在此背景下,我们的团队致力于实现类似于 o1 的推理系统——STILL: Slow Thinking with LLMs,希望开发一个技术开放的慢思考推理模型。 我们先后从两个可能的方面对复现类o1的慢思考系统做出了探索。
-
STILL-1: 通过奖励引导的外置树搜索增强大型语言模型的推理能力;(2024年11月18日)
-
STILL-2: 通过内化慢思考过程长程思维链,使用“模仿、探索和自我改进”的框架来增强大语言模型的推理能力。(2024年12月12日)


STILL-1: Enhancing LLM Reasoning with Reward-guided Tree Search
为了探索外置搜索树的可行性,我们设计并实现了了一个针对数学问题的推理框架,该框架框架包括策略模型、奖励模型和搜索算法。在训练过程中,我们实现了策略模型和奖励模型的互相迭代提升;在推理过程中,策略模型奖励模型的引导下,得到一个动态扩展的树以找到数学问题的正确解答。
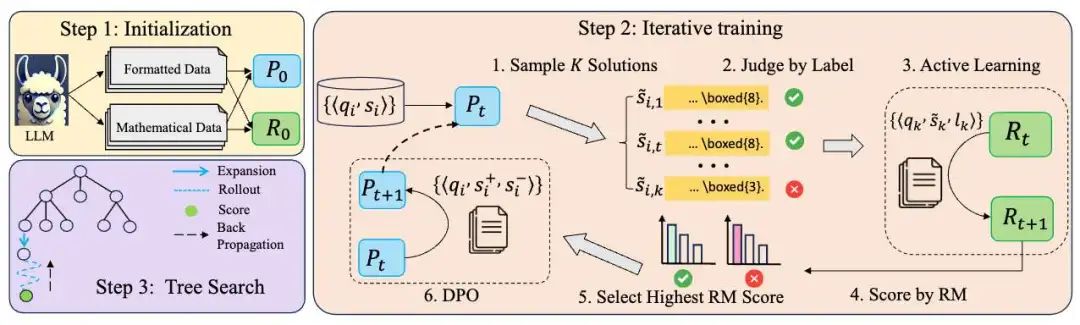
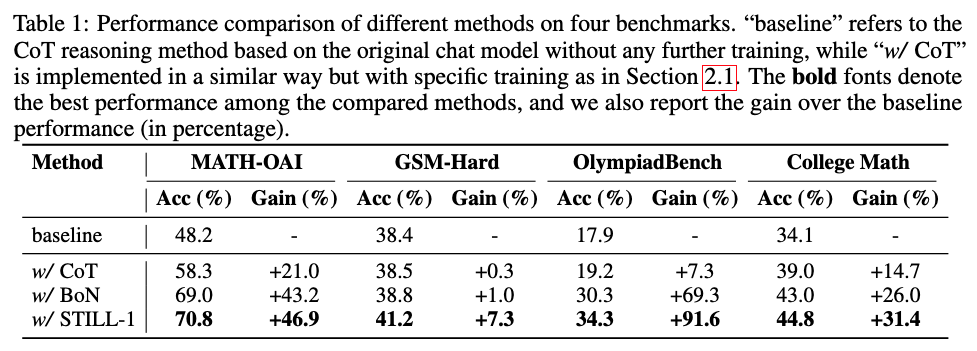
我们对实施该系统所探索的训练和推理方法进行了广泛讨论。如下表所示,该方法在LLaMA-3.1-8B-Instruct上实现了数学领域的性能飞跃。
尽管如此,我们很快意识到,这样的方法可能并不是类o1系统的正确路径。我们主要发现了三个主要问题:
- 首先,我们训练的特定领域奖励模型在不同领域之间的泛化能力较差。
- 其次,在推理阶段执行树搜索非常耗时,使其在实际应用中较为困难。
- 第三,尽管测试时间缩放有效,但我们仍无法实现训练时间缩放以提高模型性能。
这促使我们进行了第二阶段对于内化慢思考过程的探索。
STILL-2: Imitate, Explore, and Self-Improve
近期,DeepSeek和Qwen发布了类似o1系统的API或检查点,使我们能够深入研究实际的思维过程。这对我们获得初始标注数据以进行初步尝试尤为重要。其次,我们实证发现,用少量长链思维数据微调LLMs可以显著提升它们在复杂推理任务中的表现,我们推测o1可能采用了一种将慢思考内化到“一次解码”过程的方式。因此我们进行了第二阶段的尝试。具体而言,我们采用了一种“模仿、探索和自我改进”的框架作为主要技术方法来训练推理模型。
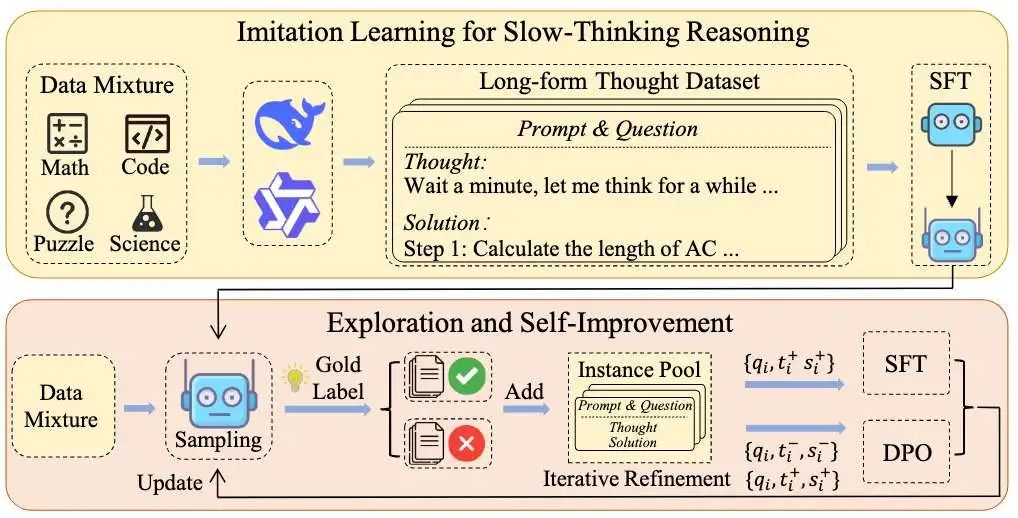
- 在初始阶段,我们使用提炼的长篇思考数据来微调推理模型,使其能够调用慢思考模式。
- 然后,通过生成多个推演过程,鼓励模型探索难题,这可以导致产生越来越多高质量的轨迹,最终得出正确答案。
- 此外,模型通过迭代改进其训练数据集来进行自我提升.
为了验证这种方法的有效性,我们在三个具有挑战性的基准测试上进行了广泛的实验。实验结果表明,我们的方法在选择的评测集上达到了与o1-preview整体接近的效果
我们深知现有的探索还不足以搭建一个完整的类o1推理系统,例如强化学习等技术我们还暂未涉足, 因此我们仍将继续致力于此。欢迎感兴趣的朋友一同交流。同时,我们也开源了过程中使用到的训练数据以及最终的模型,欢迎大家使用。(仅可用于个人科研用途)