
机器之心发布 机器之心编辑部
嘿,各位开发小伙伴,今天要给大家安利一个全新的开源项目 ——VLM-R1!它将 DeepSeek 的 R1 方法从纯文本领域成功迁移到了视觉语言领域,这意味着打开了对于多模态领域的想象空间!这个项目的灵感来自去年 DeepSeek 开源的那个 R1 方法,靠着 GRPO(Group Relative Policy Optimization)强化学习方法,在纯文本大模型上取得了惊人的效果。现在,VLM-R1 团队直接把它应用到了视觉语言模型上,打开了一扇新的大门! **VLM-R1 验证结果惊艳 **
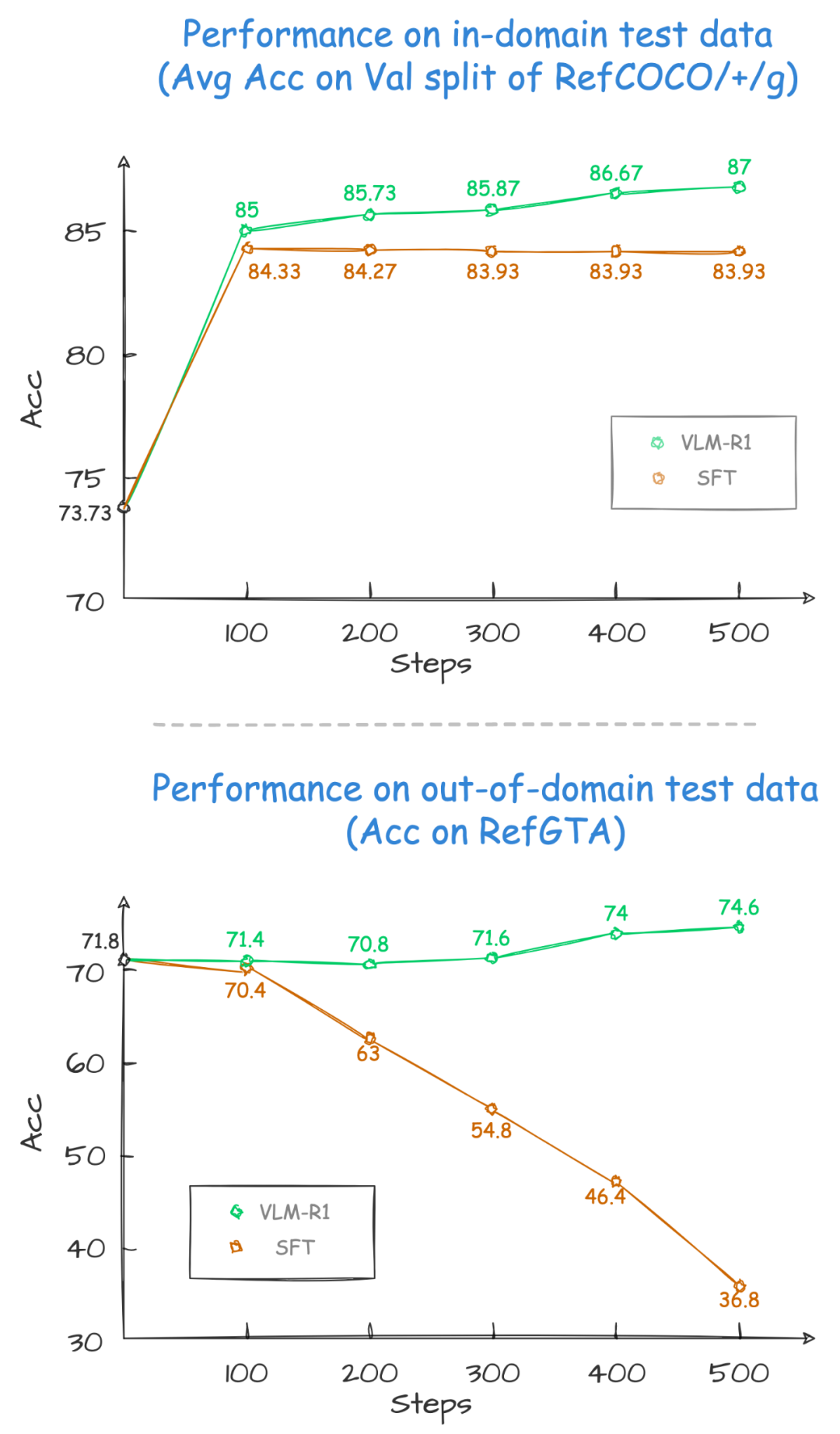
这个项目的团队在 Qwen2.5-VL 的基础上,同时对比了 R1 和传统的 SFT 方法。结果相当惊艳: 1、稳定性拉满:R1 方法在各种复杂场景下都能保持稳定的高性能,这在实际应用至关重要! 2. 泛化能力卓越:更让人震惊的是,在领域外的测试数据上,随着训练步数增加,传统 SFT 模型的性能开始下滑,而 R1 模型却能持续提升!这意味着 R1 方法帮助模型真正 “学会” 了理解视觉内容,而不是简单地记忆! 

图片里展示了一桌子丰盛的美食,包括各种蔬菜、面饼和点心。针对图片,我们向模型提出了一个问题:“在图片中找出蛋白质含量最高的食物”。 模型不仅回答得准确: “图片中展示了桌上的各种菜品,包括蔬菜、面饼和点心。从蛋白质含量来看,面饼或面点可能含量最高,因为它们通常由全谷物制成,面粉中含有蛋白质。虽然蔬菜也含有蛋白质,但比起这些主食来说含量较少。” 更厉害的是,它还精准地在图片中框选出了那个蛋白质含量最高的鸡蛋饼! 这种精确的视觉理解能力和推理能力,让人印象深刻! 完美展示了 VLM-R1 在实际应用中的优势:
准确的视觉识别能力 * 专业的知识推理能力 * 清晰的文本表达能力
全新思路
作为一个 AI 领域的观察者,VLM-R1 的出现也为开发者和行业提供了许多新的思路,比如: 1、证明了 R1 方法的通用性,不止文本领域玩得转;2、为多模态模型的训练提供了新思路;3、或许能够引领一种全新的视觉语言模型训练潮流; 完全开源
最棒的是,这个优秀的项目完全开源! 项目地址:VLM-R1