

一. 前言
最近研究社区紧追随OpenAI的步伐,想要 follow ChatGPT, GPT-4这一系列工作。本人更关注多模态相关的工作,因此,这里整理了一些 类GPT4模型(多模态LLM) 的相关技术细节。这里的多模态LLM, 换言之,利用LLM来做多模态任务,训练视觉编码器等额外结构以适配LLM。更加详细的一些解释可以参考这篇博客 胡安文:利用LLM做多模态任务(二)—— mPLUG-Owl vs Mini-GPT4 vs LLaVA yaya的理解:
现在的大语言模型LLM,如ChatGPT具备两个优秀的能力:
容纳的知识相当丰富,语义理解能力超强,以open-ended 生成的文本质量很高(eg, 翻译质量好,或者生成的答案是符合逻辑推理的)。该能力来自于第一阶段基于大量数据的pre-training。
有很好的 instruction understanding 能力,可以跟据你的任务要求,来给出相应的 response,即对各种提任务的方式都有适应能力,如 help me to rewrite xxx, or, can you polish xxx。该能力来自于第二阶段的 instruction tuning。
对于 类GPT-4模型 也希望其具备两个能力:
对图像/视频的语义理解,并生成相关的response
具有 instruction understanding 的能力。
那么直观地,为了获得想要的多模态大模型(类GPT-4模型)我们是否可以继承LLM模型的能力 (eg, reasoning, open-ended text generation, instruction understanding, ),并通过多模态数据的训练,使其进一步学习到对视觉的语义理解能力呢?总的来说,最近的几篇工作 (mPLUG-Owl, LLaVA, Mini-GPT4),都是基于这种思想来做的。在mPLUG-Owl 中,称之为 equips LLMs with multi-modal abilities。
二. 类GPT4模型的模型结构
整体的模型结构,一般会由三部分组成,(1) visual encoder, (2) LLM, (3) 其他可调整参数 以mPLUG-Owl 来分析,其 visual encoder 采用 ViT-L/14, LLM 采用 LLaMA。另外还有一个 visual abstractor module 和 low-rank adaption (LoRA)。其中 visual abstractor 是希望用少量的 learnable token来表征 视觉长序列的特征,有更好的视觉特征抽象的能力。
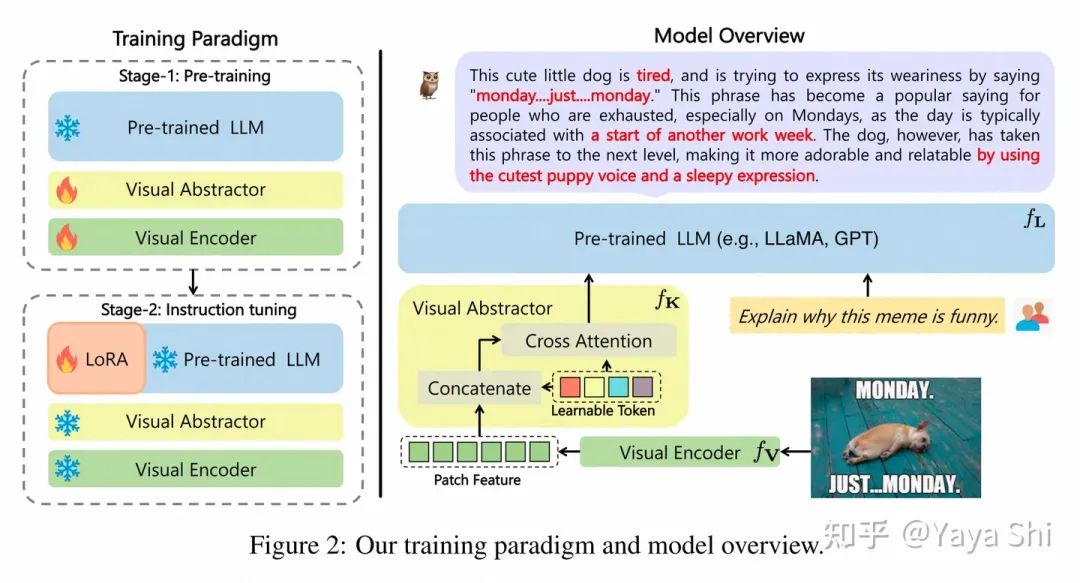
Model overview of mPLUG_Owl
三. 类GPT4模型的训练策略
类GPT4模型的训练策略,与LLM的训练是类似的, 采用pre-training和 instruction tuning 的两阶段训练。下面仍然以mPLUG-Owl 为例进行解释:
第一阶段是用大量的图文对数据进行训练,使得模型具备对视觉信息的理解能力。
mPLUG-Owl 在第一阶段只冻住 LLM 的参数,采用 LAION-400M, COYO-700M, CC 以及 MSCOCO 训练 visual encoder 模块和 visual abstractor 模块。在这种训练之下,可以使得LLM能够理解视觉特征,也可以称之为学习到了视觉和语⾔模态间的对⻬。
第二阶段是用 instruction data 来做 fine-tuning
由于 instruction data 需要人工标注,所以这部分数据是相当少量的。在LLaVA 和 mini-GPT4中都提到过如何收集数据,各位看官可以移步相应论文去看。
mPLUG-Owl 在第⼆阶段的指令微调训练中同时采用了纯文本的指令数据 (52kfrom Alpaca+90k from Vicuna+50k from Baize) 和多模态的指令数据 (150k from LLaVA)。第⼆阶段中visual encoder 模块、visual abstractor模块和原始 LLM 的参数都被冻住,参考 LoRA,只在 LLM 引⼊少量参数的 adapter 结构用于指令微调。
四. Showcase
更多case可以看论文原文,清晰大图,hhh 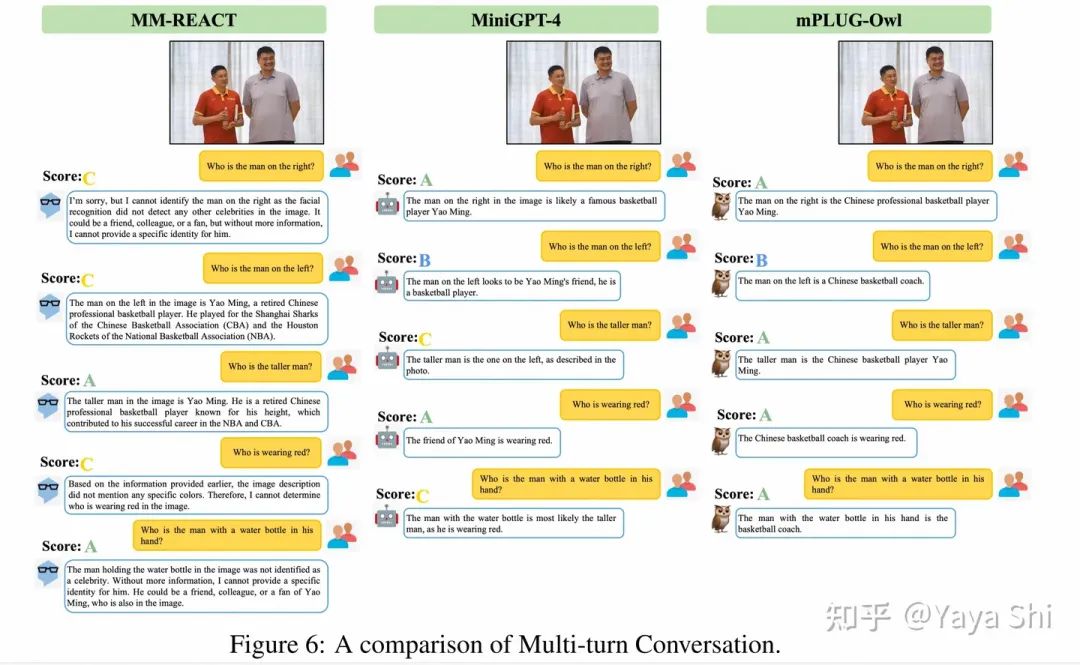
五. 定量评测
为了方便的对各种 类GPT-4模型 进行评测,在mPLUG-Owl 这篇文章中提出了一个多模态指令评测集OwlEval。 * 该评测集基于来自不同模型论文中提到的50张图像以及82个手工设计的问题来组成。其中部分图像有多个问题,因为可能涉及多轮对话。这些问题全面地评测了模型各维度的能力,比如,指令理解、视觉理解、图片上文字理解以及推理等。 * 另外为了给出定量得分,但受限目前并没有合适的自动化指标,该文参考Self-Intruct对模型的回复进行人工评测,打分规则为:A="正确且令人满意";B="有一些不完美,但可以接受";C="理解了指令但是回复存在明显错误";D="完全不相关或不正确的回复"。
yaya:目前并没有合适的自动化指标 我们可以看到,以前的常规的无论是理解型VQA, 还是生成型的Image Captioning, 在这种 类GPT-4 模型的范式下,都是以 open-ended text generation 的方式来呈现的。那么评测方式就会发生一些质的变革。
首先,对于理解型任务VQA,以往的方式预测一个类别可以通过 Accuracy 来评测,但是现在以 generated text 的方式呈现 predicted answer 则不再可以使用 Acc.
其次,对于生成式 Image Captioning, 以往的方式都在特定的benchmark (MSCOCO)上进行微调,并评测。生成的句子风格较为固定,someone doing something; 句子长度也较为统一,十几个单词。可以使用 CIDEr, BLEU-4 这些指标来评测。但是现在的 类GPT-4 模型不拘泥于特定的benchmark,其生成的captioning 更加灵活(语言风格,句子长度等),使得传统的评测 如CIDEr 可能不准确。其次这些评价方式需要 reference- text,使得评测过程也不够方便。
因此,急需提出一种适合这种范式的评测体系,包括 评测benchmark 和 评测指标。
论文:
https://www.zhuanzhi.ai/paper/58193267d58ca3014d9c3c4398dc982b

大型语言模型(LLMs)已在各种开放性任务中展示出令人印象深刻的零样本能力,而近期的研究也探索了使用LLMs进行多模态生成。在这项研究中,我们引入了mPLUG-Owl,一种新型的训练范式,通过对基础LLM、视觉知识模块和视觉抽象模块的模块化学习,为LLMs赋予多模态能力。这种方法可以支持多种模态,并通过模态协作促进各种单模态和多模态能力。
mPLUG-Owl的训练范式涉及到一个两阶段的方法,用于对齐图像和文本,该方法在LLM的帮助下学习视觉知识,同时保持甚至提高LLM的生成能力。在第一阶段,视觉知识模块和抽象模块与冻结的LLM模块一起训练,以对齐图像和文本。在第二阶段,使用仅语言和多模态监督数据集,通过冻结视觉知识模块,共同在LLM和抽象模块上微调低秩适应(LoRA)模块。
我们精心构建了一个与视觉相关的指令评估集OwlEval。实验结果表明,我们的模型超越了现有的多模态模型,展示了mPLUG-Owl令人印象深刻的指令和视觉理解能力、多轮对话能力和知识推理能力。此外,我们观察到一些意想不到和激动人心的能力,如多图像关联和场景文本理解,这使得我们有可能将其应用于更难的实际场景,如仅视觉的文档理解。
我们的代码、预训练模型、指令调优模型和评估集在 https://github.com/X-PLUG/mPLUG-Owl 可用。在线演示可在 https://www.modelscope.cn/studios/damo/mPLUG-Owl 查看。

