谷歌&HuggingFace| 零样本能力最强的语言模型结构

文 | iven
从 GPT3 到 Prompt,越来越多人发现大模型在零样本学习(zero-shot)的设定下有非常好的表现。这都让大家对 AGI 的到来越来越期待。
但有一件事让人非常疑惑:19 年 T5 通过“调参”发现,设计预训练模型时,Encoder-Decoder 的模型结构 + MLM 任务,在下游任务 finetune 效果是最好的。可是在 2202 年的当下,主流的大模型用的都是仅 decoder 的模型结构设计,比如 OpenAI 的 GPT 系列、Google 的 PaLM [1]、Deepmind 的 Chinchilla [2] 等等。这是为什么?难道这些大模型设计都有问题?
今天带来一篇 Hugging Face 和 Google 的文章。这篇文章与 T5 在实验上的思路相似,通过大量对比设计,得到一个重磅结论:要是为了模型的 zero-shot 泛化能力,decoder 结构 + 语言模型任务最好;要是再 multitask finetuning,encoder-decoder 结构 + MLM 任务最好。
除了找到最好的训练方式,作者通过大量的实验,还找到了最好的同时还能最节省成本的训练方式。训练计算量只需要九分之一!
论文题目:
What Language Model Architecture and Pretraining Objective Work Best for Zero-Shot Generalization?
论文链接:
https://arxiv.org/abs/2204.05832
![]() 模型设计
模型设计![]()
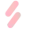 模型设计
模型设计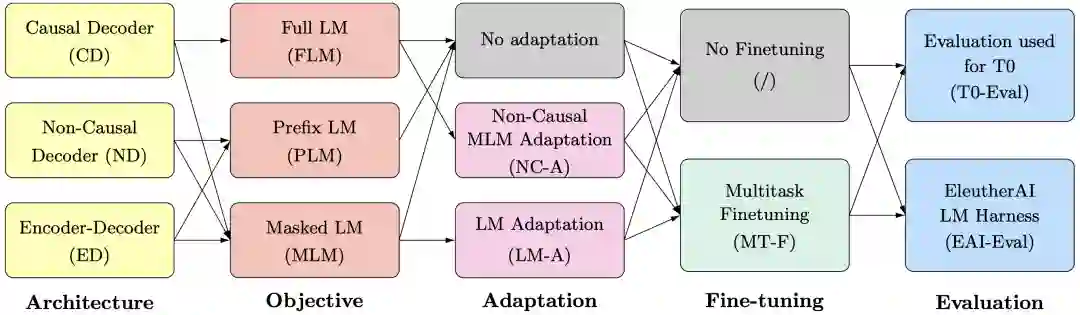
模型设计可以分成图中的四个方面,即选什么结构?什么训练目标?要不要搞 adaptation?multitask finetuning?文章还在两个 benchmark 进行了评测。
模型结构 Architecture
模型结构都基于 transformer,有三个选项,如图所示:
-
Causal decoder-only (CD):直接只用 transformer decoder。这类模型大多使用语言模型的训练目标,即通过上文预测当前 token。代表作有 GPT 系列。 -
Non-causal decoder-only (ND):为了能在给定条件下生成或基于输入生成,训练时可以让前面一部分 token 可见。 -
Encoder-decoder (ED):这就是原始 transformer 的结构,输入一个序列,encoder 输出同样长度的向量表示序列,decoder 基于 encoder 的输出做有条件的自回归生成。
小结一下,CD 是只用 decoder,ND 是给提示的 decoder,ED 是 encoder-decoder。后面将用缩写表示。
训练目标 Objective
与模型结构对应,训练目标也有三种:

-
Full language modeling (FLM):CD 类的模型架构常用 FLM,通过上文预测当前 token。在训练时,每个 token 可以并行计算出 loss,预测时要迭代预测。 -
Prefix language modeling (PLM):ND 类和 ED 类的模型架构可以用 PLM。首先在 attention 矩阵中定义一段 prefix,训练时要求模型生成 prefix 后面的 tokens。 -
Masked language modeling (MLM):只用 Encoder 的模型常用 MLM 目标。后来在 T5 这个 seq2seq 模型里,也使用了整段 mask 的 MLM 任务。
小结一下,FLM 就是语言模型目标,PLM 是带提示的语言模型目标,MLM 是掩码目标。后面也会用缩写表示。
适应任务 Adaptation
适应任务是预训练之后,换一个新的训练目标,继续训练。与 finetune 不同的是,适应的过程并没有使用新的下游任务的数据,只是继续使用预训练的数据。适应任务也可以分成两类。
-
Language modeling adaptation (LM-A):预训练用 MLM,后面再用 PLM 或 FLM 继续训练。MLM + FLM 就是 T5 采用的方式,而 MLM + PLM,就是之前非常火的连续化 prompt-tuning 的方法,比如 prefix-tuning 等等。 -
Non-causal MLM adaptation (NC-A) :预训练用的是 PLM,后面再用 FLM 继续训练。这个方法是本文首次提出的,给 decoder 前面一部分 prefix 固定住,用 PLM 目标训练,相当于给 GPT 做 prefix-tuning。
多任务微调 Multitask finetuning
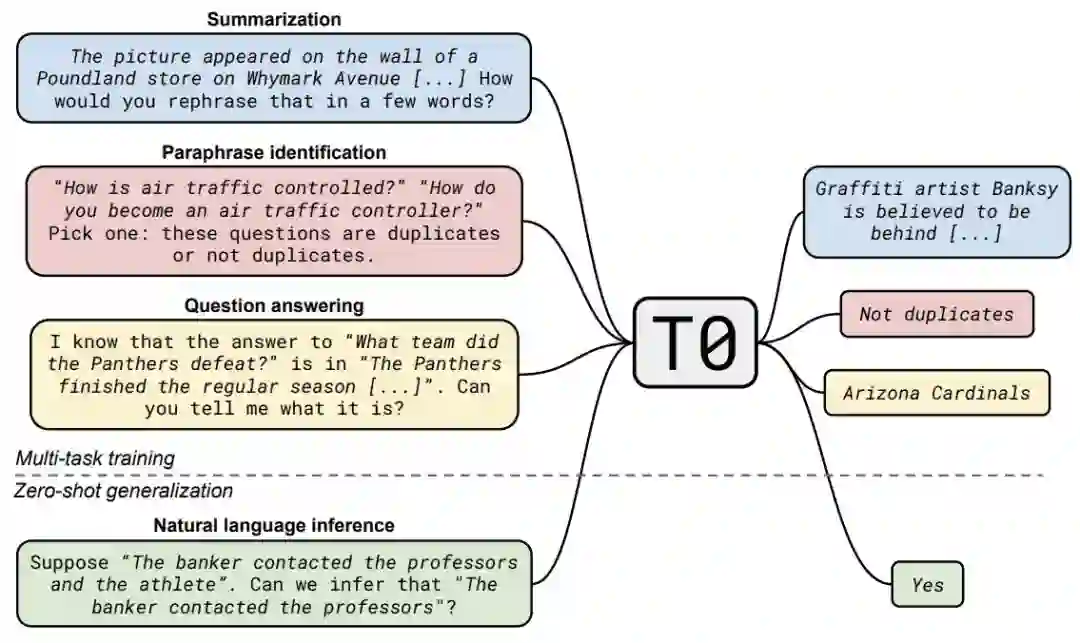
多任务微调 multitask finetuning (MT-F) 是 Hugging Face 去年年底的工作 [3],即拿到预训练模型,给他在 171 个任务上用 prompt 的方式同时 finetune。这种方式可以极大地增加预训练模型的 zero-shot 能力。
![]() 实验和结论
实验和结论![]()
评测任务
这篇文章用了两个 benchmark:
-
EleutherAI LM Evaluation Harness (EAI-Eval):这个任务是用来评测语言模型(也就是本文中使用 FLM 训练目标的模型)的 zero-shot 能力。 -
T0 的测试集 (T0-Eval):就是 Hugging Face 之前 multitask finetuning 工作使用的测试集。
这两个测试集都是用 prompt 的方式进行测试,即直接构建 prompt 输入给预训练模型,让模型生成预测结果。两个测试集不同的地方在于,EAI-Eval 的每个任务只给了一个 prompt,因此评测受 prompt 波动影响比较大,因此在本文的测试里,作者们为每个任务多设计了一些 prompts,来消除随机性。
结论
实验得到如下结论:
-
只无监督预训练时:
CD 的模型结构 + FLM 训练目标 = zero shot 最好的模型。
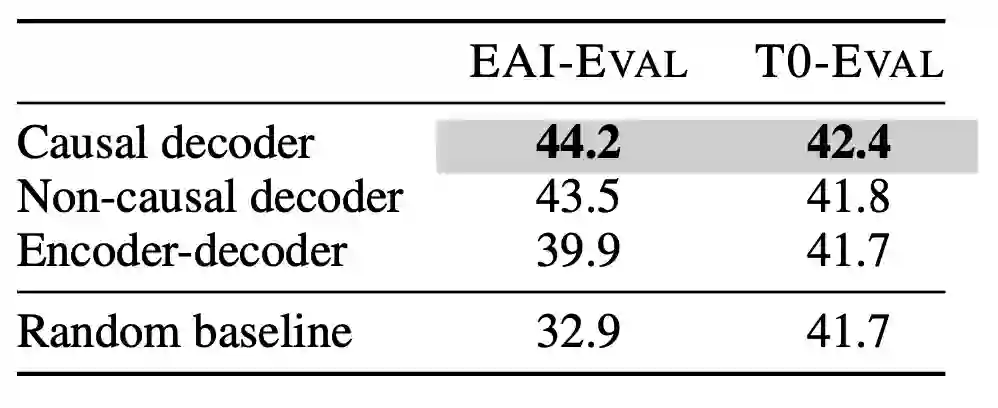
这里就跟现在的大模型对上了。大模型都用的是这个组合,有最好的零样本泛化能力。
-
预训练之后再加上多任务微调时:
ED 的模型结构 + MLM 训练目标 = zero shot 最好的模型。
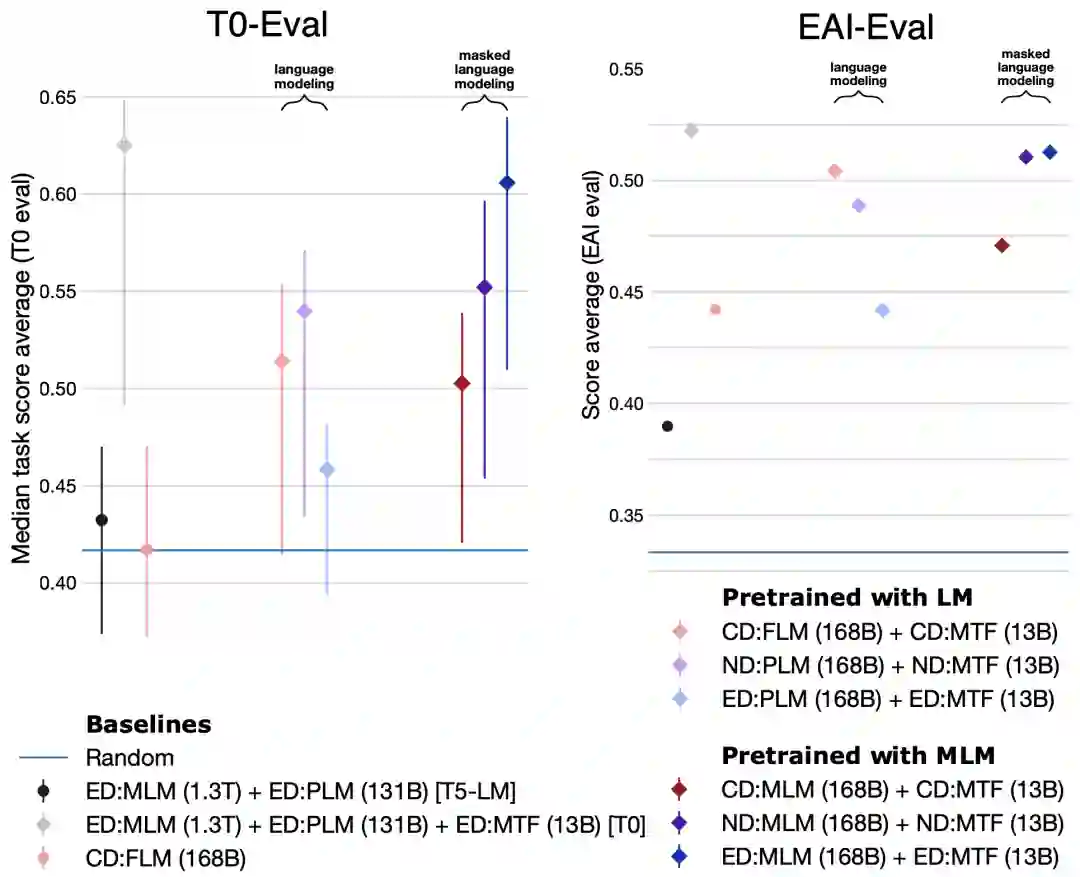
这张图左右表示两个评测集。每张图上都有九个点,代表九个模型架构和训练目标的组合。左边 T0-Eval 上结果非常明显:可以将九个组合分成三组,左边是几个 baseline,中间是三种模型结构 + 语言模型训练目标,右边是三种模型结构 + MLM 训练目标。可以明显看到,MLM 训练目标明显更好,MLM + ED 最好。
-
适应任务的作用:
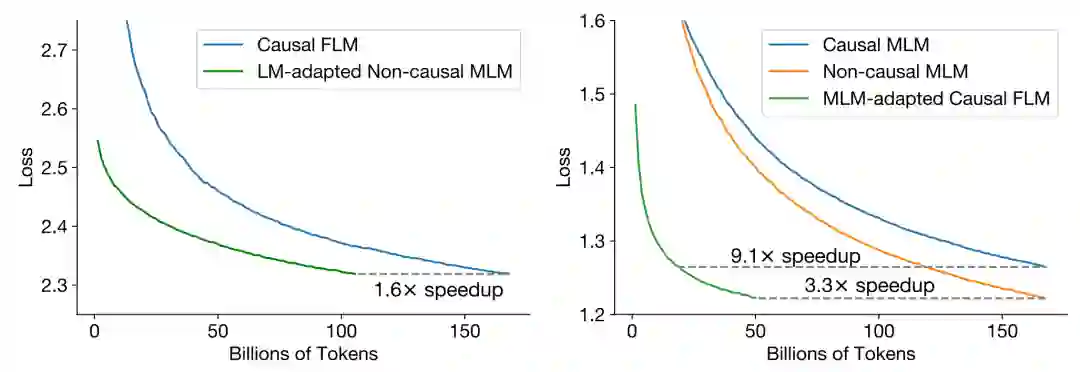
预训练之后,换一个新的训练目标,继续训练,这带来的主要是训练成本的降低。比如左图,本身我们想要一个 CD + FLM 的结合,那就先训一个 ND + MLM,然后改成 CD + FLM 再做适应任务,这样可以总体提速 1.6 倍。
经过一系列实验,作者最后总结出一个结论:如果想最低成本的构建效果好的大模型,那就用 CD + FLM 预训练,然后再改用 ND + MLM 做适应任务,最后再使用多任务微调。这样的训练方式要比直接训练提速 9.1 倍,同时效果最好。
![]() 总结
总结![]()
这篇文章跟 T5 非常像,也是用调参的感觉在设计实验,最终找到最好的模型设计和训练方式。这样的论文读下来也感觉逻辑清晰严谨。
但是从另外一个角度想,这样的文章似乎也有些无聊:现在大模型的使用,变成了找 prompt 的特征工程。这篇文章的训练和设计也变成了调参,而失去了创新的灵机一动。这可能代表了大模型领域的内卷吧。
萌屋作者:𝕚𝕧𝕖𝕟
在北大读研,目前做信息抽取,对低资源、图网络都非常感兴趣。希望大家在卖萌屋玩得开心 ヾ(=・ω・=)o
作品推荐
 萌屋作者:𝕚𝕧𝕖𝕟
萌屋作者:𝕚𝕧𝕖𝕟
后台回复关键词【入群】
加入卖萌屋NLP、CV、搜推广与求职讨论群
后台回复关键词【顶会】
获取ACL、CIKM等各大顶会论文集!
![]()
[1] Aakanksha Chowdhery, et. el., "Palm: Scaling language modeling with pathways.", https://arxiv.org/abs/2204.02311
[2]Jordan Hoffmann, et. al., "Training Compute-Optimal Large Language Models.", https://arxiv.org/abs/2203.15556
[3]Victor Sanh, et. al., "Multitask Prompted Training Enables Zero-Shot Task Generalization", https://arxiv.org/abs/2110.08207
 后台回复关键词【入群】
后台回复关键词【入群】