

鉴于深度强化学习(Deep Reinforcement Learning)最近在训练智能体赢得《星际争霸》(StarCraft)和《DoTA》(Defense Of The Ancients)等复杂游戏方面产生的影响,利用基于学习的技术进行专业兵棋推演、战场模拟和建模的研究出现了热潮。实时战略游戏和模拟器已成为作战计划和军事研究的宝贵资源。然而,最近的研究表明,这种基于学习的方法极易受到对抗性扰动的影响。本文研究了在主动对手控制的环境中为指挥与控制任务训练的智能体的鲁棒性。C2 智能体在定制的《星际争霸 II》地图上使用最先进的 RL 算法--A3C 和 PPO 进行训练。我们通过经验表明,使用这些算法训练的智能体极易受到对手注入的噪声的影响,并研究了这些扰动对训练后的智能体性能的影响。工作凸显了开发更强大训练算法的迫切性,尤其是在战场等关键领域。
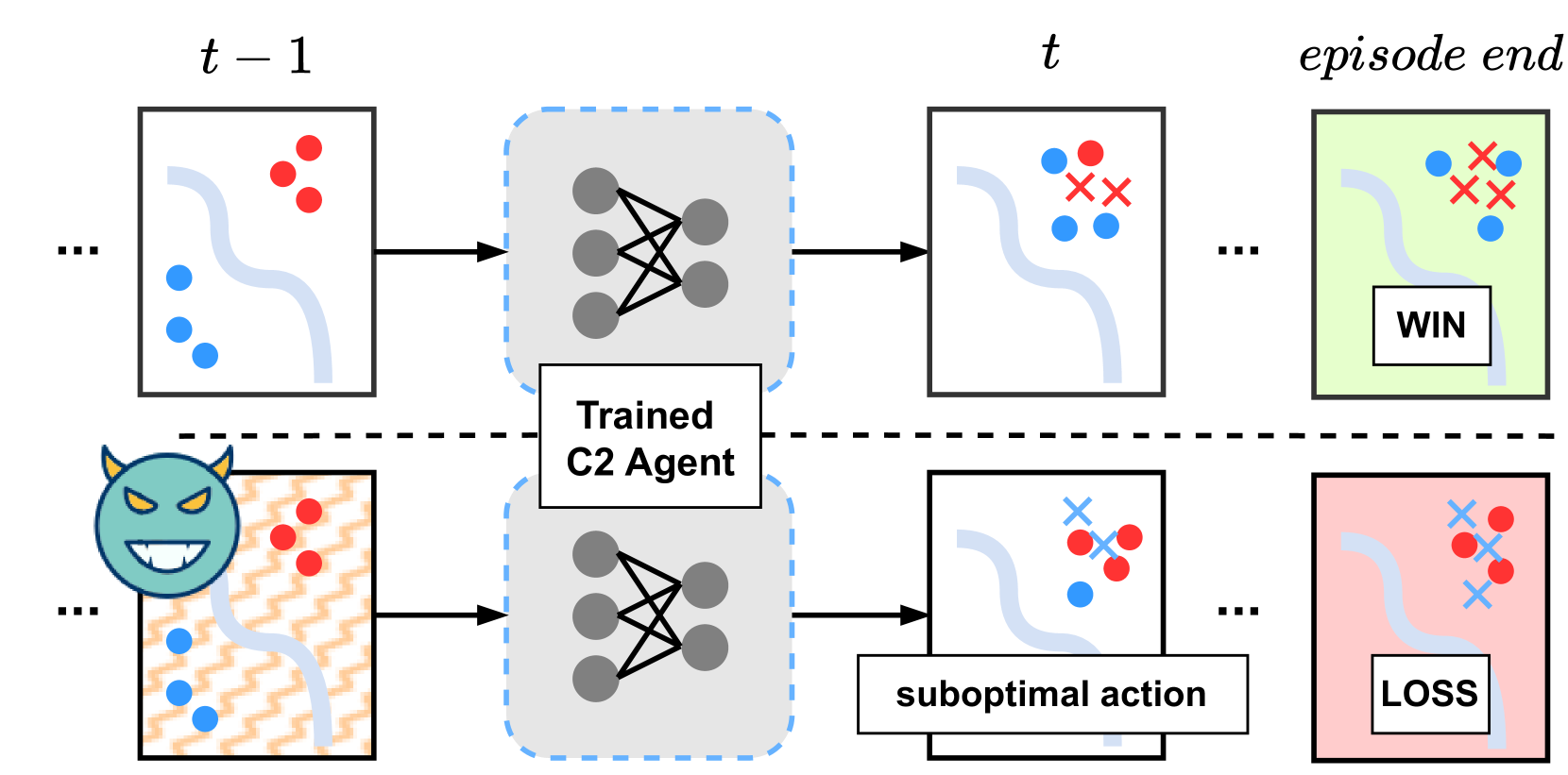
图 1:鲁棒性评估方法: 图中显示了时间步 𝑡 时良性环境(上图)与恶意环境(下图)之间的差异。在 𝑡-1 处的观测数据被输入到一个在良性环境中经过预训练的 C2 智能体。由于输入中注入了对抗性扰动(橙色),智能体采样了次优行动,最终导致 BlueForce 损失。
深度强化学习(DRL)已被成功用于训练《星际争霸》和《DoTAdota》等几款战术和即时战略游戏中的智能体,这些游戏涉及复杂的规划和决策。这些智能体通过自我博弈、模仿学习等技术,熟练地提出了与经验丰富的人类玩家不相上下的制胜策略。因此,近年来,军事研究界对将这些 RL 技术应用于作战计划和指挥与控制(C2)等任务的兴趣与日俱增。与此同时,传统的游戏引擎也被重新利用以促进自动学习,并为战场模拟开发了新的游戏引擎,创造了实际上的数字兵棋推演。这项研究背后的驱动力是改进和增强未来战场上使用的战略,预计未来战场将更加复杂和非常规,可能超出人类指挥官的认知能力。
最新研究成果表明,通过强化学习技术和合成数据训练的 C2 智能体在赢得模拟兵棋推演方面取得了相当大的成功。这在一定程度上归功于 RL 训练的可扩展性,事实证明它在探索和利用不同策略方面具有巨大优势,即使面对困难或复杂的场景,并且只给定环境的部分信息时也是如此。然而,这些评估都是在良性环境下进行的,在这种环境下,C2 智能体可用的信息被假定为未被破坏。实际上,这在战场上是不太可能的,因为在战场上,由于信息的收集方式(来自传感器或其他来源),信息可能存在固有的噪音,或者可能被敌方篡改。在这项工作中,我们将评估这种训练有素的智能体在 C2 环境中受到潜在对抗性输入时的鲁棒性。
为此,首先使用《星际争霸 II 学习环境》来模拟蓝方和红方两支队伍之间的冲突。C2 智能体指挥 "蓝方"消灭 "红方"部队,从而赢得战斗。
接下来,假设环境中存在攻击者,在将战场上收集到的观测数据提供给 C2 代理之前对其进行篡改。添加的扰动被称为对抗性扰动,其构造非常难以察觉,以躲避检测,同时最大限度地颠覆 C2 智能体的策略,使其变成有害的东西(图 1)。然后,从多个指标评估了智能体性能的下降,并从军事角度分析了行动方案的偏差。
主要贡献总结如下:
- 通过经验证明了训练有素的 C2 智能体在输入观测数据的微小对抗性扰动面前的脆弱性。我们的研究量化了一些预期趋势,并揭示了一些非显而易见的趋势。例如,我们的研究显示,部分训练的智能体似乎比完全训练的智能体更能抵抗噪声。
- 出于通用性考虑,评估了两种不同场景下的攻击效果,这两种场景分别对应 C2 智能体的攻击和防御任务。
- 还对使用 A3C 和 PPO 这两种最先进的 RL 算法训练的智能体进行了评估,并对它们对注入噪声的鲁棒性进行了评论。
- 我们通过分析策略网络预测的行动分布因攻击者的扰动而发生的变化,提供了模型输出的可解释性。
评估结果表明,vanilla RL 训练算法很容易受到敌方扰动的影响,因此需要建立稳健的训练机制,并采用复杂的检测和预防技术,尤其是在这种关键场景下。
本文的结构如下。首先,简要介绍了将 RL 用于 C2 的背景,然后在第 2.1 节中描述了星际争霸环境和两个自定义场景--虎爪和 NTC,我们使用这两个场景来训练我们的智能体。在第 4 节中,我们描述了自定义场景的状态和行动空间,以及 RL 智能体的细节。第 4.2 节和第 5 节分别介绍了攻击方法和评估。最后,我们讨论了利用对抗性鲁棒训练技术的必要性和未来工作方向。


