通过集成 XNNPACK 实现推理速度飞跃

文 / Marat Dukhan,Google Research
利用 CPU 运行 ML 推理可在边缘设备空间中实现最大覆盖范围。因此,提高 CPU 上的神经网络推理性能一直是 TensorFlow Lite 团队的首要任务。我们听取了社区的需求,并很高兴告诉大家,将 XNNPACK 库集成到 TensorFlow Lite 中后,浮点推理的速度平均可提升 2.3 倍。
-
为了向移动设备上的 TensorFlow Lite 用户提供最佳性能,所有算子都已针对 ARM NEON 进行优化。最关键的部分(卷积、深度卷积、转置卷积、全连接)已针对手机中常用的 ARM core(如 Pixel 2 中的 Cortex-A53/A73 和 Pixel 3 中的 Cortex-A55/A75)对指令集进行优化,。 -
对于 x86-64 设备上的 TensorFlow Lite 用户,XNNPACK 已添加对 SSE2、SSE4、AVX、AVX2 和 AVX512 指令集的优化。 XNNPACK 不会逐一执行 TensorFlow Lite 算子,而是着眼于整个计算图,并通过算子融合对其进行优化。例如,在 TensorFlow Lite 中,通过 VALID 填充模式组合 PAD 算子和 CONV_2D 算子,以此表示使用显式填充的卷积。XNNPACK 检测到这样的算子组合,然后将这两个算子融合为使用显式指定填充的单个卷积算子。
-
XNNPACK 库
https://github.com/google/XNNPACK
适用于 CPU 的 XNNPACK 后端已加入 TensorFlow Lite 的推理加速引擎系列,可用于 移动 GPU、Android 的神经网络 API、Hexagon DSP、Edge TPU 和 Apple Neural Engine。此 XNNPACK 后端提供了可在所有移动设备、桌面系统和 Raspberry Pi 开发板上使用的强基线。
-
Android 的神经网络 API
https://www.tensorflow.org/lite/performance/nnapi
在 TensorFlow 2.3 版本中,XNNPACK 后端已包含在针对 Android 和 iOS 的 TensorFlow Lite 预构建二进制文件中,只需更改单行代码即可启用。Windows、macOS 和 Linux 版 TensorFlow Lite 也支持 XNNPACK 后端,可通过构建时的选择加入机制 (opt-in mechanism) 启用。经过更广泛的测试并听取社区反馈后,我们计划在后续的版本中,将所有平台的 XNNPACK 后端设置为默认启用。
性能提升
TensorFlow Lite 中经 XNNPACK 加速的推理已应用于生产环境的 Google 产品,我们也观察到其在各种神经网络架构和移动处理器上的速度得到了显著提升。XNNPACK 后端将 Pixel 3a Playground 中的背景分割速度提高了 5 倍,并将 ARCore 中 Augmented Faces API 的神经网络模型速度提升了 2 倍。
-
Pixel 3a Playground
https://www.blog.google/products/google-ar-vr/see-your-world-differently-playground-and-google-lens-pixel-3/
Augmented Faces API
https://developers.google.com/ar/develop/java/augmented-faces
-
MobileNet v2 图像分类 -
MobileNet v3-Small 图像分类 -
DeepLab v3 分割 -
BlazeFace 人脸检测 -
SSDLite 2D 对象检测 -
Objectron 3D 对象检测 -
Face Mesh 特征点 -
MediaPipe Hands 特征点 KNIFT 局部特征描述符
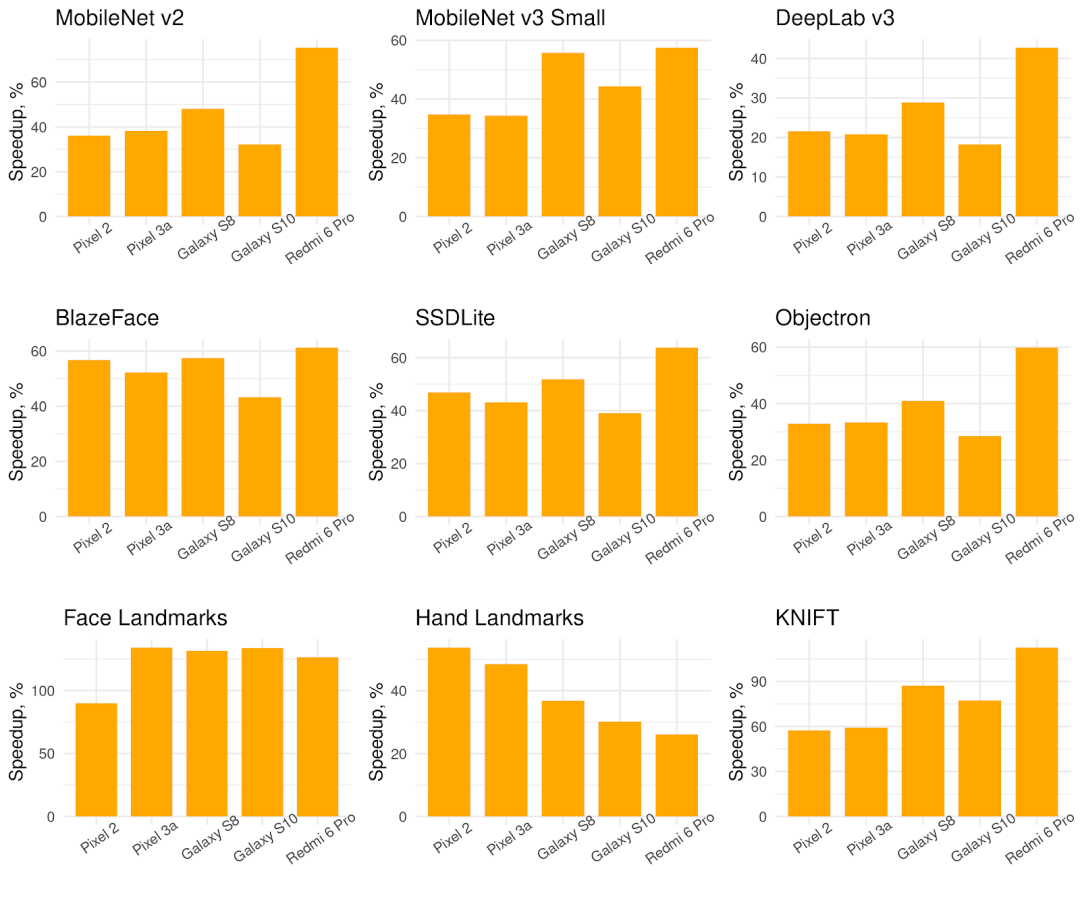
相较于 5 款手机上的默认后端,使用 XNNPACK 后端的 TensorFlow Lite 的单线程推理速度有所提高(数值越高越好)
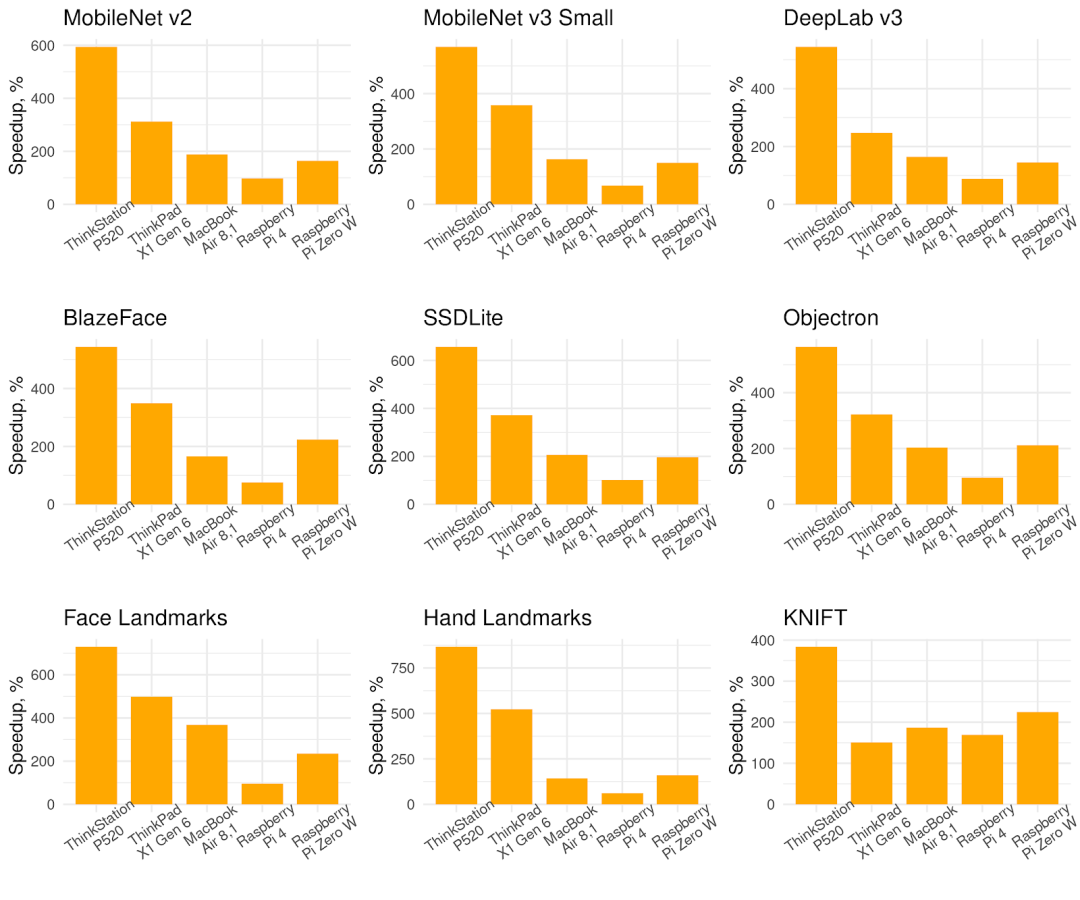
相较于 5 款桌面设备、笔记本电脑和嵌入式设备的默认后端,使用 XNNPACK 后端的 TensorFlow Lite 的单线程推理速度有所提高(数值越高越好)
如何使用 XNNPACK 后端?
XNNPACK 后端已包含在 TensorFlow Lite 2.3 预构建二进制文件中,但是需要通过显式运行时选择加入机制来启用。我们正在努力在将来的版本中默认启用它。
预构建的 TensorFlow Lite 2.3 Android 归档 (AAR) 已包含 XNNPACK,只需一行代码即可在 InterpreterOptions 对象中启用:
Interpreter.Options interpreterOptions = new Interpreter.Options();interpreterOptions.setUseXNNPACK(true);Interpreter interpreter = new Interpreter(model, interpreterOptions);
针对 iOS 的预构建 TensorFlow Lite 2.3 CocoaPods 同样也包含 XNNPACK,同时具有在InterpreterOptions类中启用此后端的机制:
var options = InterpreterOptions()options.isXNNPackEnabled = truevar interpreter = try Interpreter(modelPath: "model/path", options: options)
在 iOS 上,XNNPACK 推理可通过 Objective-C 或TFLInterpreterOptions类中的新属性启用 :
TFLInterpreterOptions *options = [[TFLInterpreterOptions alloc] init];= YES;NSError *error;TFLInterpreter *interpreter =alloc] initWithModelPath:@"model/path"options:optionserror:&error];
Windows、Linux 和 Mac 上的 XNNPACK 后端可通过构建时选择加入机制启用。在使用 Bazel 构建 TensorFlow Lite 时,只需添加--define tflite_with_xnnpack=true即可启用 XNNPACK 后端,默认情况下 TensorFlow Lite 解释器将使用此后端。
您可以使用 TensorFlow Lite 基准测试工具,通过 XNNPACK 来评估 TensorFlow Lite 模型的性能。即使在构建基准测试工具时没有加入--define tflite_with_xnnpack=trueBaze 选项,您也可以通过如下--use_xnnpack=true标记轻松启用 XNNPACK。
adb shell /data/local/tmp/benchmark_model \--graph=/data/local/tmp/mobilenet_quant_v1_224.tflite \--use_xnnpack=true \--num_threads=4
-
基准测试工具
https://github.com/tensorflow/tensorflow/tree/master/tensorflow/lite/tools/benchmark
可加速哪些操作?
XNNPACK 后端目前支持 TensorFlow Lite 浮点算子的子集(请参阅文档,了解详细信息和限制)。XNNPACK 支持 32 位浮点模型和使用 16 位浮点量化进行加权的模型,但不支持对权重或激活进行定点量化的模型。但是,您无需将模型限制为仅使用 XNNPACK 支持的算子:任何不受支持的算子都将以透明方式回退到 TensorFlow Lite 中的默认实现。
-
文档
https://github.com/tensorflow/tensorflow/blob/master/tensorflow/lite/delegates/xnnpack/README.md
研究展望
-
Fast Sparse ConvNets 算法集成 -
最新 ARM 处理器上的半精度推理 定点表示中的量化推理
-
Fast Sparse ConvNets
https://arxiv.org/abs/1911.09723
希望您能在 GitHub 和 StackOverflow 页面上积极发表您的想法和建议。
-
GitHub
https://github.com/tensorflow/tensorflow/issues StackOverflow
https://stackoverflow.com/questions/tagged/tensorflow-lite
致谢
衷心感谢 Frank Barchard、Chao Mei、Erich Elsen、Li Yunlu、Jared Duke、Artiosim Ablavatski、Juhyun Lee、Andrei Kulik、Matthias Grundmann、Sameer Agarwal、Lawrence Chan 和 Sarah Sirajuddin
如果您想详细了解 本文提及 的相关内容,请参阅以下文档。这些文档深入探讨了这篇文章中提及的许多主题:
MobileNet v2 图像分类
https://ai.googleblog.com/2018/04/mobilenetv2-next-generation-of-on.html
https://tfhub.dev/tensorflow/lite-model/mobilenet_v2_1.0_224/1/default/1MobileNet v3-Small 图像分类
https://storage.googleapis.com/mobilenet_v3/checkpoints/v3-small_224_1.0_float.tgzDeepLab v3 分割
https://ai.googleblog.com/2018/03/semantic-image-segmentation-with.html
https://tfhub.dev/tensorflow/lite-model/deeplabv3/1/metadata/1BlazeFace 人脸检测
https://google.github.io/mediapipe/solutions/face_detection.html
https://github.com/google/mediapipe/blob/master/mediapipe/models/face_detection_front.tfliteSSDLite 2D 对象检测
https://arxiv.org/abs/1801.04381
https://github.com/google/mediapipe/blob/master/mediapipe/models/ssdlite_object_detection.tfliteObjectron 3D 对象检测
https://github.com/google/mediapipe/blob/master/mediapipe/models/object_detection_3d_chair.tfliteFace Mesh 特征点
https://github.com/google/mediapipe/blob/master/mediapipe/models/face_landmark.tfliteMediaPipe Hands 特征点
https://github.com/google/mediapipe/blob/master/mediapipe/models/hand_landmark.tfliteKNIFT 局部特征描述符
https://github.com/google/mediapipe/blob/master/mediapipe/models/knift_float.tflite
了解更多请点击 “阅读原文” 访问官网。

分享 💬 点赞 👍 在看 ❤️
以“三连”行动支持优质内容!



