

在过去的十年中,基于深度学习的算法在遥感图像分析的不同领域中得到了极大的普及。最近,最初在自然语言处理中引入的基于transformers的架构已经遍及计算机视觉领域,其中自注意力机制已经被用来替代流行的卷积算子来捕获远程依赖。受计算机视觉最近进步的启发,遥感界也见证了对视觉transformers在各种不同任务中的探索。尽管许多调查都集中在计算机视觉中的transformers上**,但据我们所知,我们是第一个对基于遥感transformers的最新进展进行系统综述的人**。我们的调查涵盖了60多种基于transformers的最新方法,用于解决遥感子领域的不同遥感问题:非常高分辨率(VHR)、高光谱(HSI)和合成孔径雷达(SAR)图像。我们通过讨论transformers在遥感中的不同挑战和开放问题来总结调研。此外,我们打算经常更新和维护遥感论文中最新的transformers,它们各自的代码: https: //github.com/VIROBO-15/Transformer-in-Remote-Sensing
https://www.zhuanzhi.ai/paper/bfb0308c1fdd624df840a15426edb230
导论
遥感成像技术在过去几十年里取得了显著的进步。现代机载传感器以更高的空间、光谱和时间分辨率对地球表面进行大范围覆盖,在生态学、环境科学、土壤科学、水污染、冰川学、陆地测量和地壳分析等众多研究领域发挥着至关重要的作用。遥感成像的自动分析带来了独特的挑战,例如,数据通常是多模态的(如光学或合成孔径雷达传感器),位于地理空间(地理位置),通常在全球范围内,数据量不断增长。
深度学习,尤其是卷积神经网络(CNNs)已经主导了计算机视觉的许多领域,包括物体识别、检测和分割。这些网络通常以RGB图像作为输入,并执行一系列卷积、局部归一化和池化操作。CNN通常依赖于大量的训练数据,然后得到的预训练模型被用作下游各种应用的通用特征提取器。基于深度学习的计算机视觉技术的成功也激励了遥感界,在许多遥感任务中取得了重大进展,包括高光谱图像分类、变化检测和高分辨率卫星实例分割。
卷积运算是CNN的主要组成部分之一,它捕获输入图像中元素(如轮廓和边缘信息)之间的局部相互作用。CNN编码的偏差,如空间连通性和翻译等方差。这些特性有助于构建可推广和高效的体系结构。然而,局部接受域在CNN限制建模的远程依赖图像(如,遥远的部分关系)。此外,卷积是内容独立的,因为卷积滤波器的权值是固定的,对所有输入应用相同的权值,而不管它们的性质。近年来,视觉transformers (ViTs)[1]在计算机视觉的各种任务中表现出了令人印象深刻的性能。ViT基于自注意力机制,通过学习序列元素之间的关系有效地捕获全局交互。最近的研究[2],[3]表明ViT具有内容依赖的远程交互建模能力,可以灵活调整其接受域以对抗数据中的干扰并学习有效的特征表示。因此,ViT及其变体已成功地用于许多计算机视觉任务,包括分类、检测和分割。
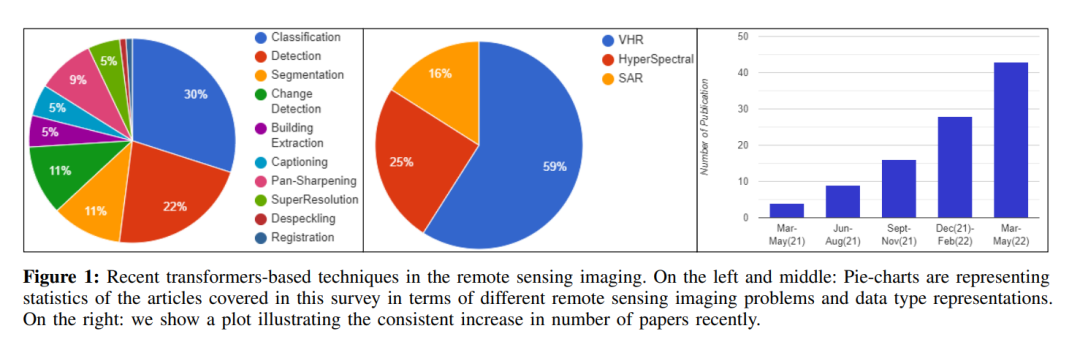
随着ViTs 在计算机视觉领域的成功,遥感界也见证了基于transformers的框架在许多任务中的应用的显著增长(见图1),如高分辨率图像分类、变化检测、平移锐化、建筑物检测和图像字幕。这开启了利用ImageNet预训练[4]-[6]或使用视觉transformers进行遥感预训练[7]的不同方法的有前景的遥感研究的新浪潮。同样,文献中也存在基于纯transformers设计[8]、[9]或基于transformers和CNN的混合方法[10]-[12]的方法。因此,由于针对不同遥感问题的基于transformers的方法迅速涌入,跟上最近的进展变得越来越具有挑战性。在这项工作中,我们回顾了这些进展,并提出了最新的基于transformers的方法在流行的遥感领域。综上所述,我们的主要贡献如下:
本文对基于transformers的模型在遥感成像中的应用进行了全面综述。据我们所知,我们是第一个在遥感中介绍transformers的调研,从而弥合了计算机视觉和遥感在这一快速增长和流行领域的最新进展之间的差距。
我们概述了CNN和transformers,讨论了它们各自的优点和缺点。
本文综述了60多项基于transformers的研究工作,讨论了遥感领域的最新进展。
在此基础上,讨论了遥感transformers面临的不同挑战和研究方向。
论文的其余部分组织如下:第二节讨论了其他有关遥感成像的调研。在第三节中,我们概述了遥感中不同的成像方式,而第四节提供了CNN和视觉transformers的简要概述。之后,我们回顾了基于transformers的方法在非常高分辨率(VHR)成像(第五节)、高光谱图像分析(第六节)和合成孔径雷达(SAR)方面的进展。在第八部分,我们总结了我们的调研,并讨论了潜在的未来研究方向。
遥感图像数据集
遥感图像通常从各种来源和数据收集技术获得。遥感影像数据的典型特征是其空间、光谱、辐射和时间分辨率。空间分辨率指的是图像中每个像素的大小,以及对应像素所代表的地球表面的面积。空间分辨率的特点是成像场景中可以分离的微小和精细特征。光谱分辨率是指传感器通过识别更细的波长来收集场景信息的能力,具有更窄的波段(如10 nm)。另一方面,辐射分辨率表征了每个像素的信息程度,传感器的动态范围越大,就意味着在图像中可以识别出更多的细节。时间分辨率是指在地面上获取的相同位置的连续图像之间所需的时间。在此,我们简要讨论常用的遥感成像类型,图2所示的例子。

Transformers 遥感图像处理
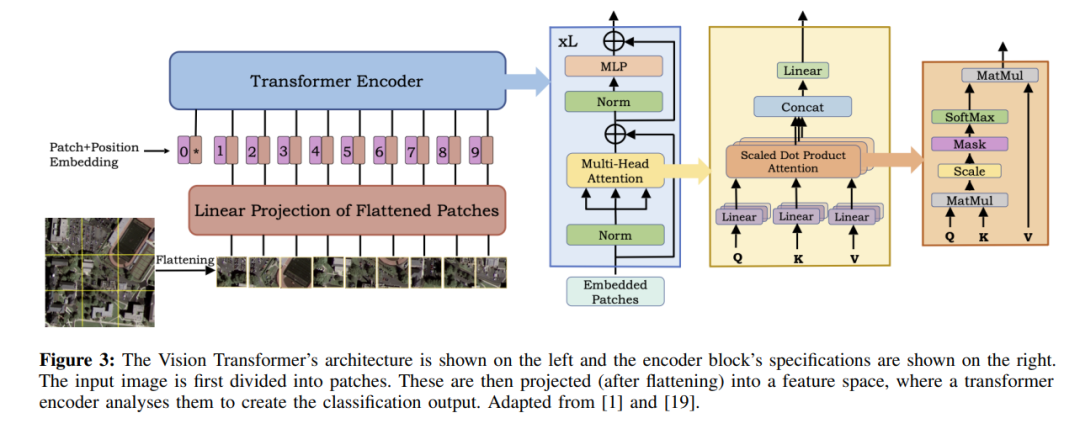
近年来,基于transformers的模型在许多计算机视觉和自然语言处理(NLP)任务中取得了很好的结果。Vaswani等人[17]首先将transformers作为注意力驱动模型引入机器翻译应用。为了捕获长距离依赖关系,transformers使用自注意力层,而不是传统的循环神经网络,后者努力编码序列元素之间的这种依赖关系。为了有效地捕捉输入图像中的远程依赖关系,[1]的工作引入视觉转换器(ViTs)来完成图像识别任务,如图3所示。ViTs[1]将图像解释为补丁序列,并通过与NLP任务中使用的类似的传统transformers编码器对其进行处理。ViT在通用视觉数据中的成功不仅激发了计算机视觉的不同领域的兴趣,也激发了遥感社区的兴趣,近年来,许多基于ViT的技术已被探索用于各种任务。
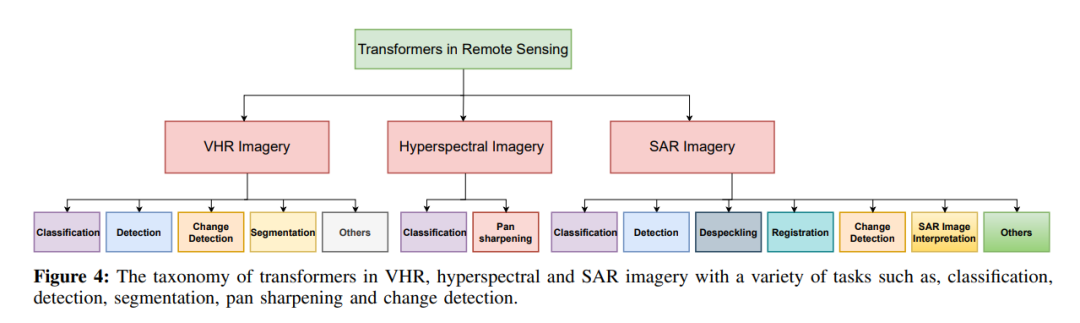
遥感场景分类是一个具有挑战性的问题,其任务是自动关联一个语义类别标签到一个给定的高分辨率图像,包括地物和不同的土地覆盖类型。在现有的基于视觉transformers的VHR场景分类方法中,Bazi等人[4]探讨了标准视觉transformers 架构1的影响,并研究了产生加法数据的不同数据增强策略。此外,他们的工作还评估了通过修剪层次来压缩网络的影响,同时保持分类精度。
在VHR成像中,由于物体的尺度变化和类别的多样性,目标的定位是一个具有挑战性的问题。这里的任务是同时识别和定位(矩形或定向边界框)图像中属于不同对象类别的所有实例。大多数现有的方法采用混合策略,结合有线电视网络和transformers 的优点在现有的两级和单级探测器。除了混合策略,最近很少有研究探讨基于DETR的transformers 目标检测范式[36]。
在遥感中,图像变化检测是探测地表变化的一项重要任务,在农业[50]、[51]、城市规划[52]、地图修订[53]等方面有着广泛的应用。这里的任务是生成通过比较多时间或双时间图像获得的变化图,所得到的二进制变化图中的每个像素根据对应位置是否发生了变化而具有0或1值。在最近的基于transformer的变化检测方法中,Chen等人[54]提出了一种双时间图像transformer,封装在一个基于深度特征差异的框架中,旨在对时空上下文信息建模。在提出的框架中,编码器被用于捕获基于标记的时空中的上下文。然后将所得到的上下文化令牌提供给解码器,在解码器中,特征在像素空间中进行细化。Guo等人[55]提出了一种深度多尺度连体结构,称为MSPSNet,利用并行卷积结构(PCS)和自我关注。本文提出的MSPSNet通过PCS对不同时间点图像进行特征集成,然后基于自注意力的特征细化,进一步增强多尺度特征。
在遥感领域,通过像素级分类自动将图像分割为语义类是一个具有挑战性的问题,其应用范围广泛,包括地质调查、城市资源管理、灾害管理和监测等。现有的基于transformers的遥感图像分割方法通常采用混合设计,目的是结合CNNs和transformers的优点。[65]提出了一种基于transformers的轻型框架Efficient-T,该框架包含隐式边缘增强技术。提出的Efficient-T采用分层式Swin-transformers和MLP头。[66]中引入了一种耦合的CNN-transformers框架,称为CCTNet,旨在将CNN捕捉到的局部细节,如边缘和纹理,以及通过transformers获得的全局上下文信息结合起来,用于遥感图像的裁剪分割。此外,还引入了测试时间增强和后处理等模块,在推理时去除孔洞和小目标,从而恢复完整的分割图像。
在这项工作中,我们介绍了遥感成像transformers的广泛概述:非常高分辨率(VHR),高光谱和合成孔径雷达(SAR)。在这些不同的遥感图像中,我们进一步讨论了基于transformers 的各种任务的方法,如分类、检测和分割。我们的调研涵盖了60多个基于transformers 的遥感研究文献。我们观察到transformers 在不同的遥感任务中获得了良好的性能,这可能是由于它们捕获远程依赖关系的能力以及它们的表示灵活性。此外,几种标准transformers 架构和主干的公开可用性使得探索它们在遥感成像问题中的适用性变得更加容易。

