

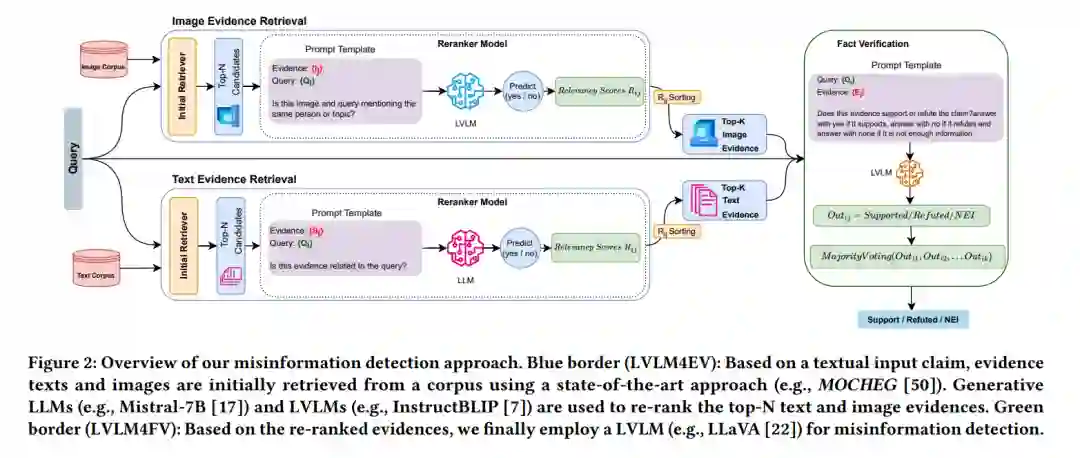
虚假信息的日益泛滥及其带来的严重影响,促使工业界和学术界开发虚假信息检测和事实核查的方法。近年来,虽然大型语言模型(LLMs)在各种任务中表现出色,但LLMs是否以及如何有助于虚假信息检测仍然相对未被充分探索。大多数现有的先进方法要么不考虑证据,仅关注与声明相关的特征,要么假定证据已经提供。少数方法将证据检索作为虚假信息检测的一部分,但依赖于微调模型。在本文中,我们研究了在零样本设置下使用LLMs进行虚假信息检测的潜力。我们将证据检索组件纳入流程,因为从各种来源收集相关信息以检测声明的真实性至关重要。为此,我们提出了一种新的使用LLMs和大型视觉语言模型(LVLM)的多模态证据检索重排序方法。检索到的证据样本(图像和文本)作为基于LVLM的多模态事实验证方法(LVLM4FV)的输入。为了实现公平评估,我们通过为现有证据检索数据集中的证据样本注释更完整的图像和文本检索证据样本,解决了证据样本的真值不完整问题。我们在两个数据集上的实验结果表明,所提出的方法在证据检索和事实验证任务中均表现优越,并且在跨数据集的泛化能力方面也优于有监督的基线。
成为VIP会员查看完整内容
相关内容
Arxiv
224+阅读 · 2023年4月7日
相关VIP内容
相关资讯
相关论文
Arxiv
224+阅读 · 2023年4月7日