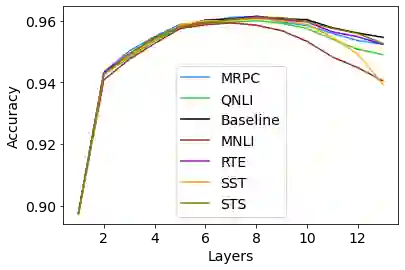
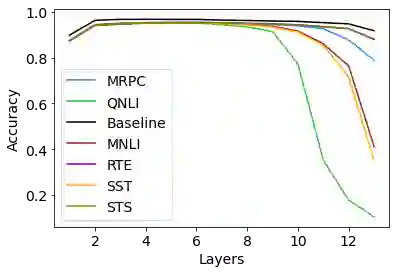
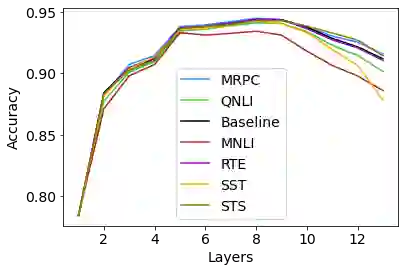
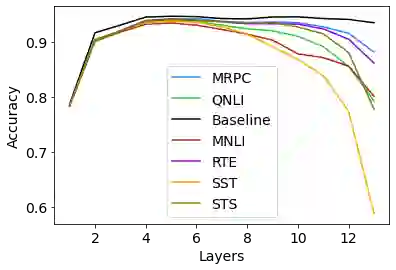
Transfer learning from pre-trained neural language models towards downstream tasks has been a predominant theme in NLP recently. Several researchers have shown that deep NLP models learn non-trivial amount of linguistic knowledge, captured at different layers of the model. We investigate how fine-tuning towards downstream NLP tasks impacts the learned linguistic knowledge. We carry out a study across popular pre-trained models BERT, RoBERTa and XLNet using layer and neuron-level diagnostic classifiers. We found that for some GLUE tasks, the network relies on the core linguistic information and preserve it deeper in the network, while for others it forgets. Linguistic information is distributed in the pre-trained language models but becomes localized to the lower layers post fine-tuning, reserving higher layers for the task specific knowledge. The pattern varies across architectures, with BERT retaining linguistic information relatively deeper in the network compared to RoBERTa and XLNet, where it is predominantly delegated to the lower layers.
翻译:从受过训练的神经语言模型向下游任务转移学习是国家语言平台最近的一个主要主题。一些研究人员已经表明,深入的国家语言平台模型学习的是非三轨语言知识,在模型的不同层面捕获。我们调查了如何微调下游国家语言平台的任务,如何影响所学的语言知识。我们利用层级和神经级诊断分类师,对受过训练的模型BERT、RoBERTA和XLNet进行了一项研究。我们发现,对于一些GLUE任务,网络依靠核心语言信息,在网络中将其保存得更深,而对于其他任务来说,网络则忘记了这一点。语言信息在经过训练的语文模型中传播,但被本地化到较低层次的调整后,为具体任务知识保留更高的层次。不同结构的格局各不相同,与RBERTA和XLNet相比,网络保留的语言信息在网络中较深得多,而后者主要被下放到较低层次。