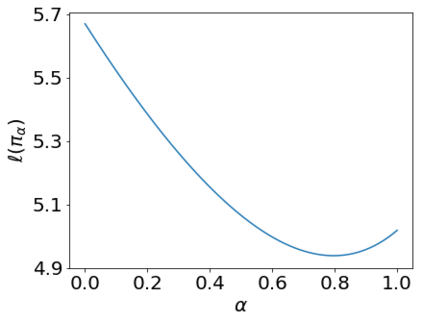
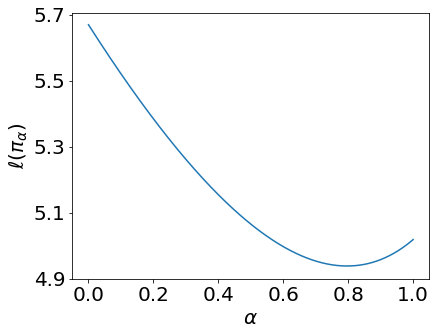
We revisit the finite time analysis of policy gradient methods in the one of the simplest settings: finite state and action MDPs with a policy class consisting of all stochastic policies and with exact gradient evaluations. There has been some recent work viewing this setting as an instance of smooth non-linear optimization problems and showing sub-linear convergence rates with small step-sizes. Here, we take a different perspective based on connections with policy iteration and show that many variants of policy gradient methods succeed with large step-sizes and attain a linear rate of convergence.
翻译:在最简单的环境之一,我们重新审视政策梯度方法的有限时间分析:有限状态和行动 MDP, 包含由所有随机政策和精确梯度评价组成的政策类别。最近,我们做了一些工作,将这一环境视为一个平稳的非线性优化问题的例子,并用小步尺显示次线性趋同率。在这里,我们从与政策迭代的关联出发,从不同的角度看待政策梯度方法的许多变体以大步尺成功并达到线性趋同率。