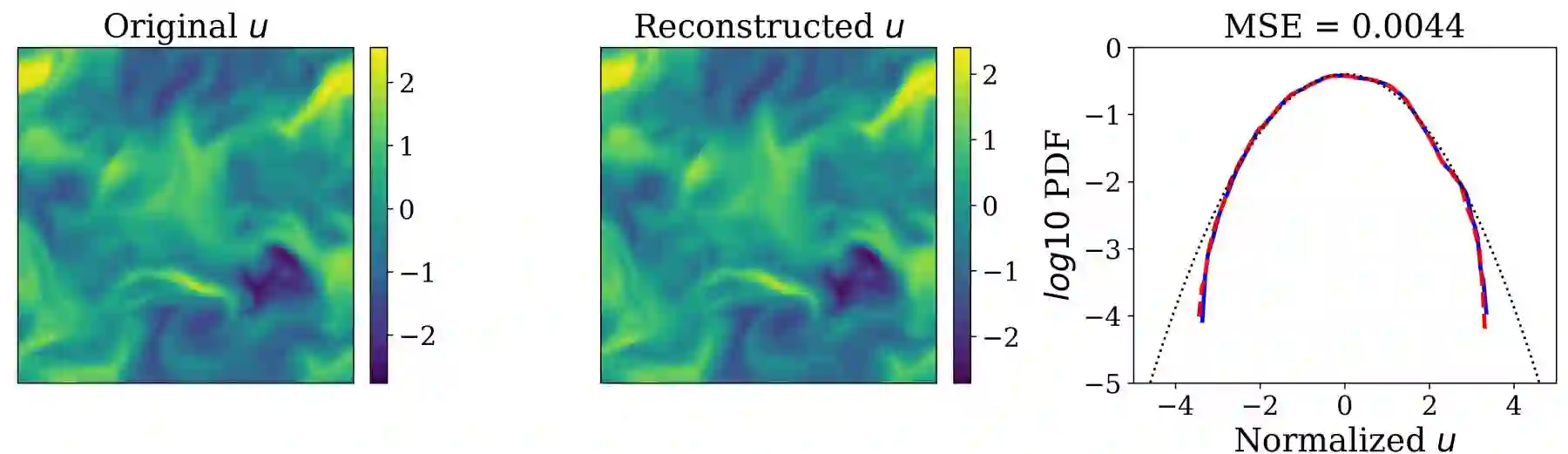
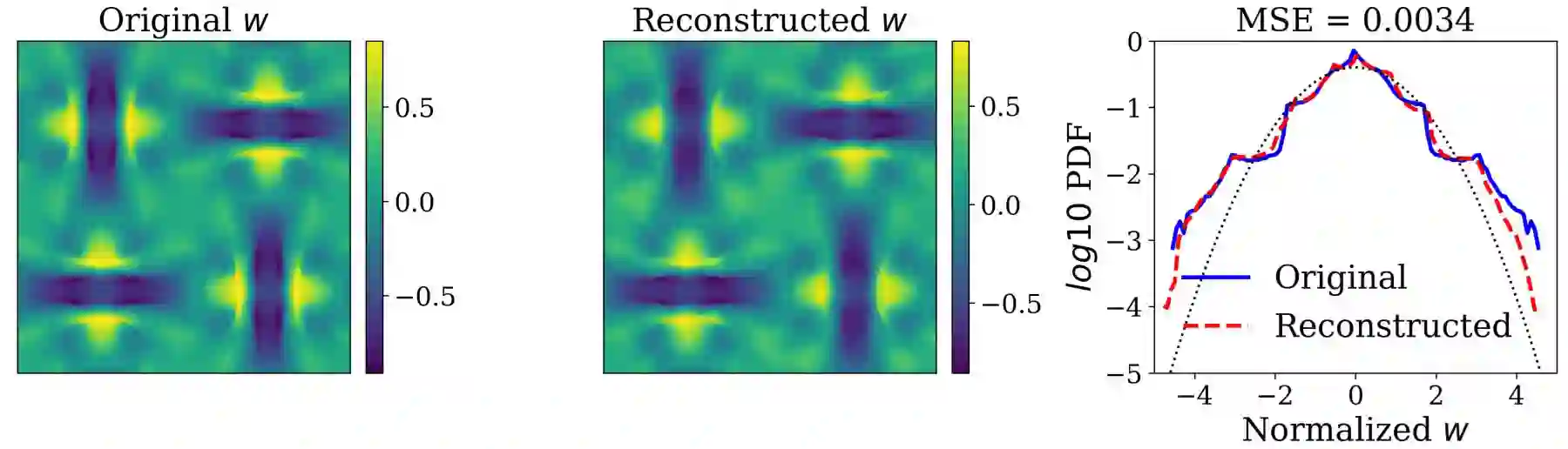
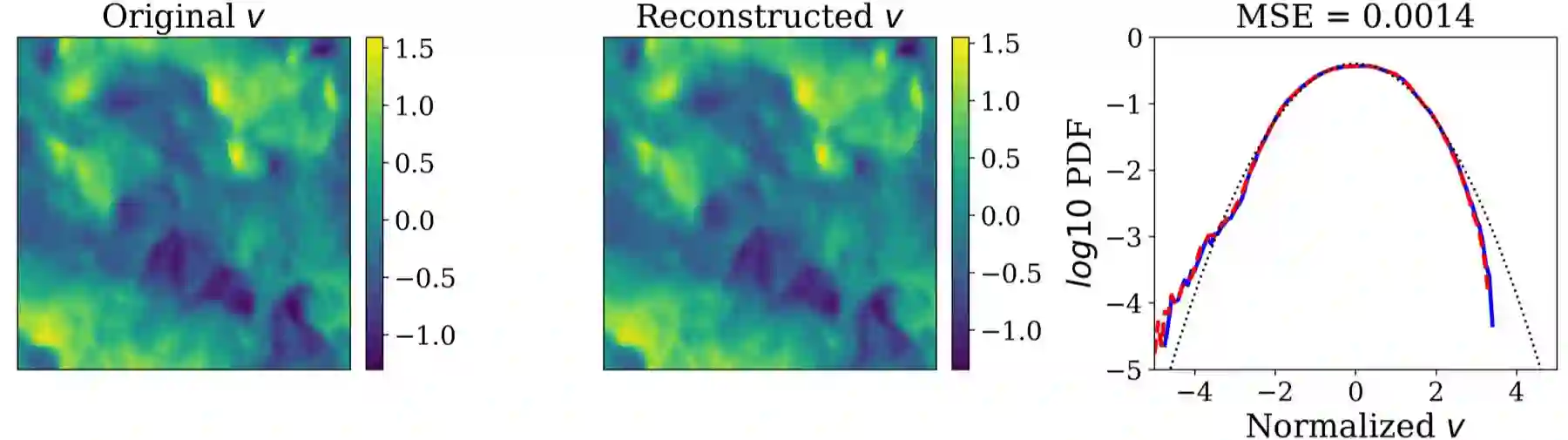
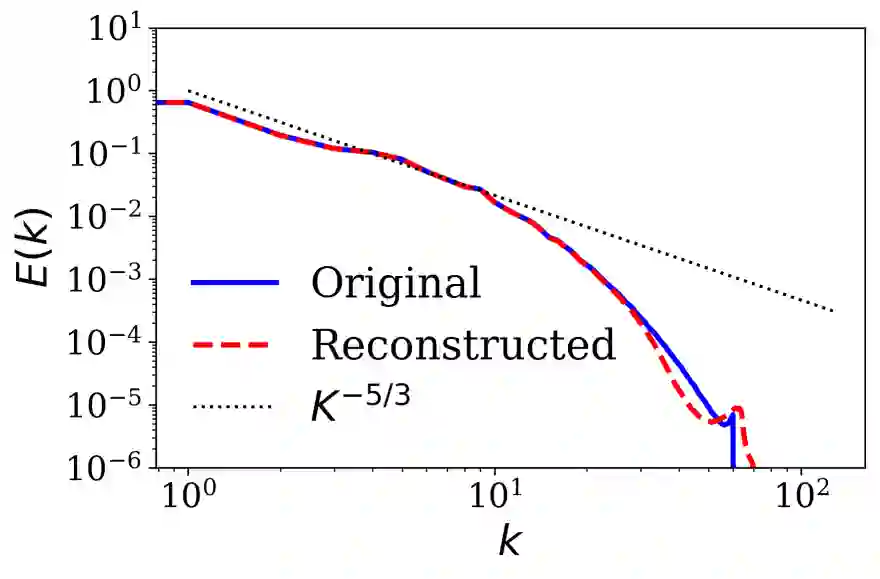
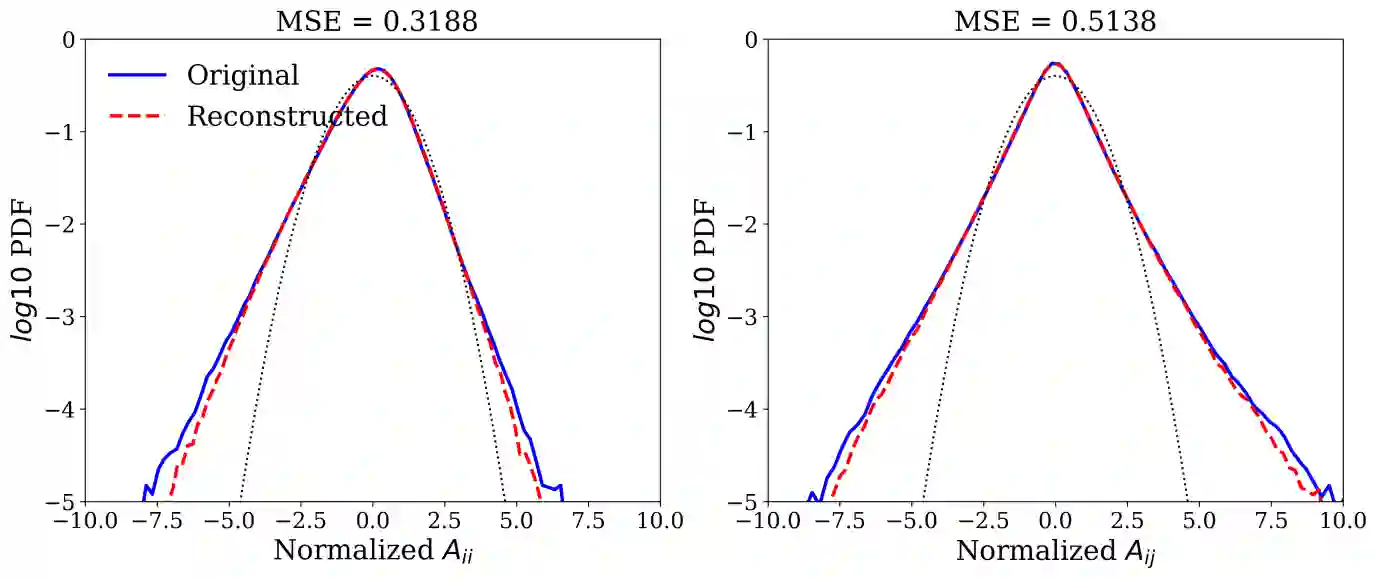
Analyzing large-scale data from simulations of turbulent flows is memory intensive, requiring significant resources. This major challenge highlights the need for data compression techniques. In this study, we apply a physics-informed Deep Learning technique based on vector quantization to generate a discrete, low-dimensional representation of data from simulations of three-dimensional turbulent flows. The deep learning framework is composed of convolutional layers and incorporates physical constraints on the flow, such as preserving incompressibility and global statistical characteristics of the velocity gradients. The accuracy of the model is assessed using statistical, comparison-based similarity and physics-based metrics. The training data set is produced from Direct Numerical Simulation of an incompressible, statistically stationary, isotropic turbulent flow. The performance of this lossy data compression scheme is evaluated not only with unseen data from the stationary, isotropic turbulent flow, but also with data from decaying isotropic turbulence, and a Taylor-Green vortex flow. Defining the compression ratio (CR) as the ratio of original data size to the compressed one, the results show that our model based on vector quantization can offer CR $=85$ with a mean square error (MSE) of $O(10^{-3})$, and predictions that faithfully reproduce the statistics of the flow, except at the very smallest scales where there is some loss. Compared to the recent study based on a conventional autoencoder where compression is performed in a continuous space, our model improves the CR by more than $30$ percent, and reduces the MSE by an order of magnitude. Our compression model is an attractive solution for situations where fast, high quality and low-overhead encoding and decoding of large data are required.
翻译:分析来自动荡流模拟的大规模数据时, 需要大量资源。 这一重大挑战凸显了数据压缩技术的必要性。 在这项研究中, 我们应用基于矢量量量的物理知情深学习技术, 以矢量量的量化为基础, 生成一个离散的、 低维的数据代表来自三维波动流的模拟数据。 深层学习框架由卷状层组成, 包含对流动的物理限制, 如保存速度梯度的压抑性和全球统计特征。 模型的准确性是通过统计、 比较基基基相似度和物理基基量的测量来评估的。 培训数据集是来自对矢量的直接数字模拟, 以矢量不压缩为根据直接数字, 以直接数字模拟为基础, 数据压缩基量的最小值值比原始数据比例的比, 高数值 。 以模型显示的是, 基量 基量 基量 的 基量 基量 和 基量 基量 基量 的 基量 数据, 以 基量 基数 基数 基 基 基 基 基 基 基 基 基 的 基 基 基 基 基 的 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基 基