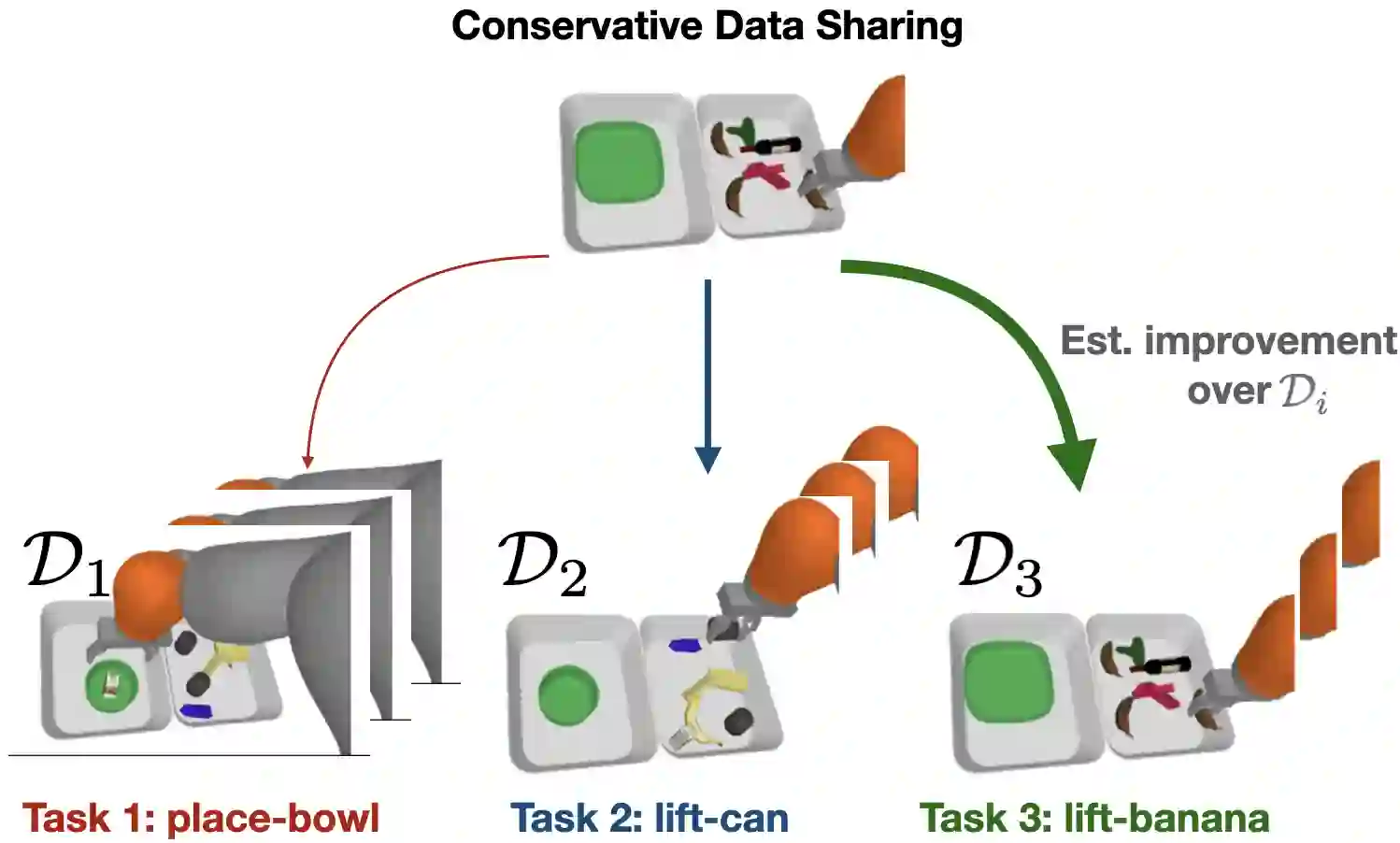
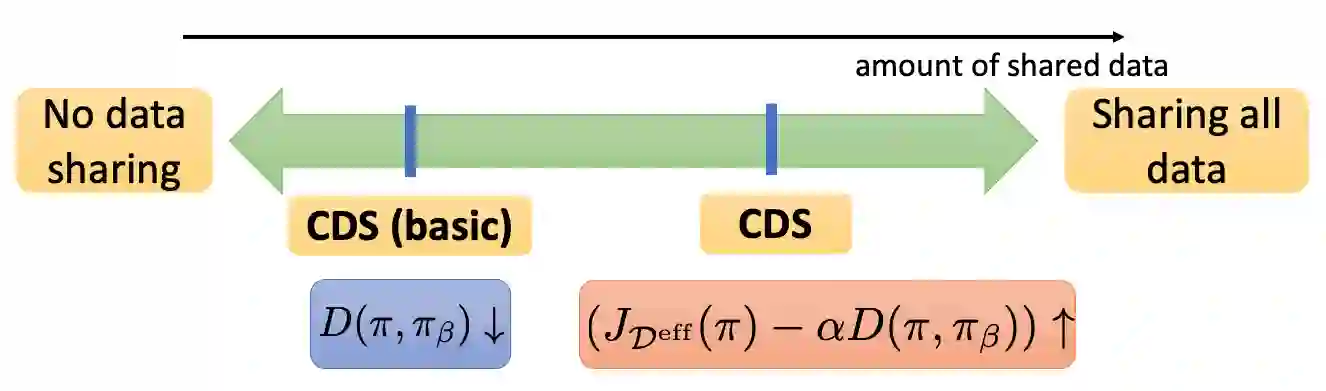
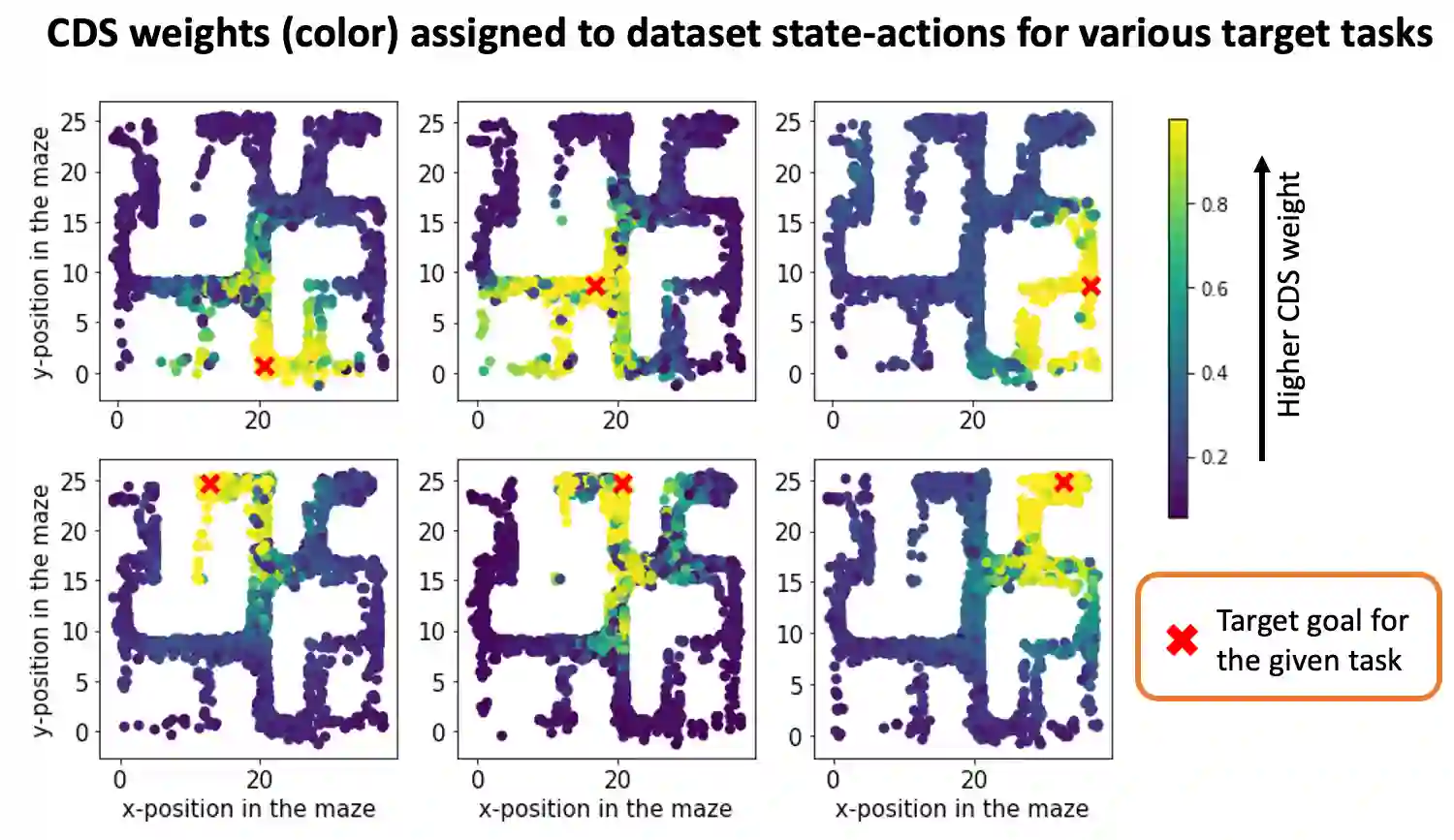
Offline reinforcement learning (RL) algorithms have shown promising results in domains where abundant pre-collected data is available. However, prior methods focus on solving individual problems from scratch with an offline dataset without considering how an offline RL agent can acquire multiple skills. We argue that a natural use case of offline RL is in settings where we can pool large amounts of data collected in various scenarios for solving different tasks, and utilize all of this data to learn behaviors for all the tasks more effectively rather than training each one in isolation. However, sharing data across all tasks in multi-task offline RL performs surprisingly poorly in practice. Thorough empirical analysis, we find that sharing data can actually exacerbate the distributional shift between the learned policy and the dataset, which in turn can lead to divergence of the learned policy and poor performance. To address this challenge, we develop a simple technique for data-sharing in multi-task offline RL that routes data based on the improvement over the task-specific data. We call this approach conservative data sharing (CDS), and it can be applied with multiple single-task offline RL methods. On a range of challenging multi-task locomotion, navigation, and vision-based robotic manipulation problems, CDS achieves the best or comparable performance compared to prior offline multi-task RL methods and previous data sharing approaches.
翻译:离线强化学习(RL)算法在具备大量事先收集的数据的领域显示了有希望的成果。然而,先前的方法侧重于通过离线数据集解决个别问题,而没有考虑离线RL代理商如何获得多种技能。我们争辩说,离线RL的自然使用案例是在各种情景中收集的大量数据可用于解决不同任务的环境下发生的,并利用所有这些数据来学习所有任务的行为,而不是孤立地对每个任务进行培训。然而,在多任务离线下线RL的所有任务中共享数据的做法在实践上表现得令人惊讶。索洛夫实证分析发现,共享数据实际上会加剧所学政策和数据集之间的分配变化,而这反过来又会导致所学政策的差异和业绩不佳。为了应对这一挑战,我们开发了一个在多任务离线下数据共享中进行数据共享的简单技术,根据对具体任务数据的改进,我们称之为保守的数据共享(CDDS),并且可以应用多任务离线的多任务共享数据共享。我们发现,共享数据共享数据实际上会加剧所学政策和数据集之间的分布式变化,在具有挑战性前的多任务管理方法上,实现具有挑战性的多任务前的多任务管理。