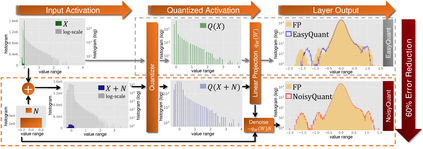
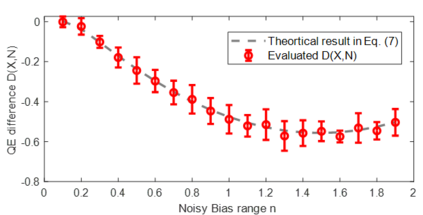
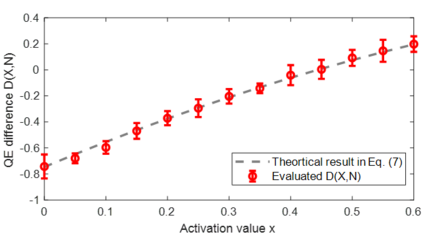
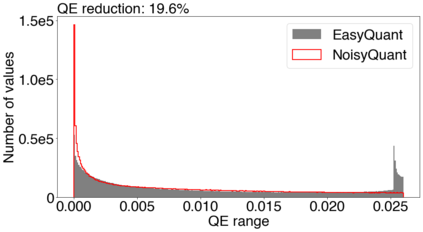
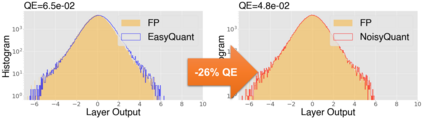
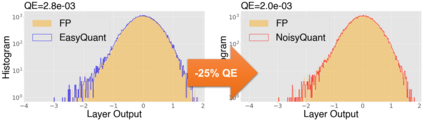
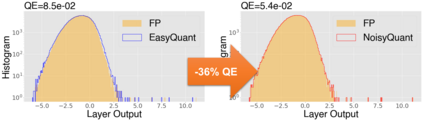
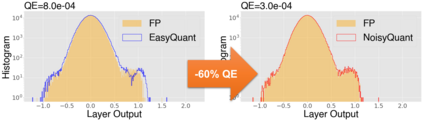
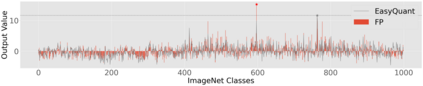
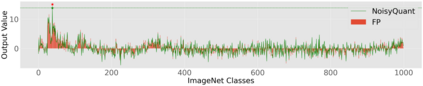
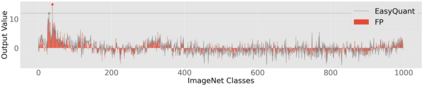
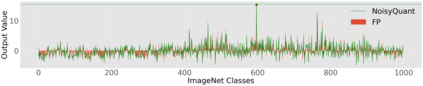
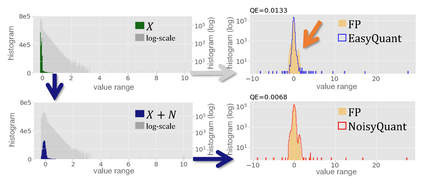
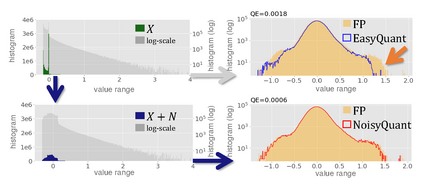
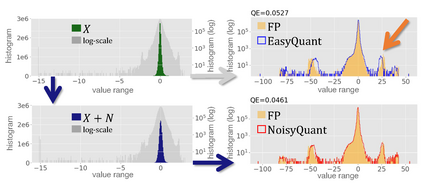
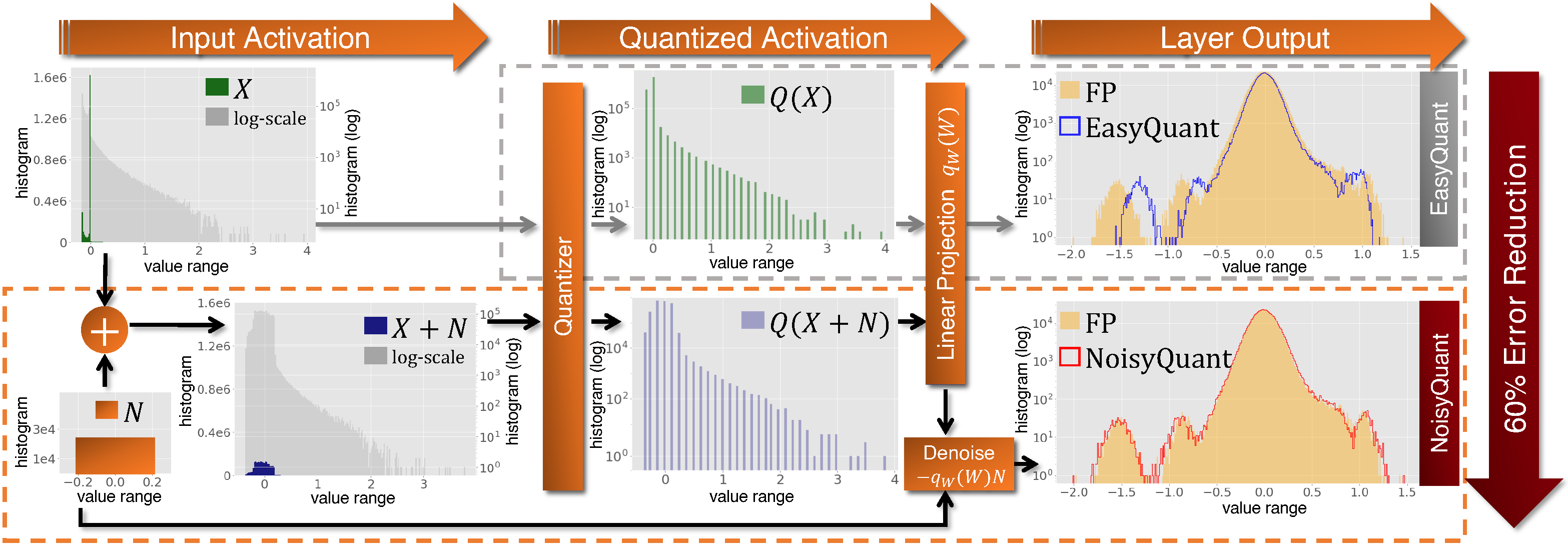
The complicated architecture and high training cost of vision transformers urge the exploration of post-training quantization. However, the heavy-tailed distribution of vision transformer activations hinders the effectiveness of previous post-training quantization methods, even with advanced quantizer designs. Instead of tuning the quantizer to better fit the complicated activation distribution, this paper proposes NoisyQuant, a quantizer-agnostic enhancement for the post-training activation quantization performance of vision transformers. We make a surprising theoretical discovery that for a given quantizer, adding a fixed Uniform noisy bias to the values being quantized can significantly reduce the quantization error under provable conditions. Building on the theoretical insight, NoisyQuant achieves the first success on actively altering the heavy-tailed activation distribution with additive noisy bias to fit a given quantizer. Extensive experiments show NoisyQuant largely improves the post-training quantization performance of vision transformer with minimal computation overhead. For instance, on linear uniform 6-bit activation quantization, NoisyQuant improves SOTA top-1 accuracy on ImageNet by up to 1.7%, 1.1% and 0.5% for ViT, DeiT, and Swin Transformer respectively, achieving on-par or even higher performance than previous nonlinear, mixed-precision quantization.
翻译:本文提出了NoisyQuant,这是一种量化器不可知的后训练活化量化性能增强方法,专为解决视觉Transformer结构复杂、训练成本高的问题而设计。然而,视觉Transformer激活分布具有重尾特征,这阻碍了以前的后训练量化方法的有效性,即使采用了先进的量化器设计。与通过调整量化器以更好地适应复杂激活分布的方法不同,本文提出了NoisyQuant。 基于理论发现,对于给定的量化器,向被量化的值添加固定均匀随机噪声偏差可以在可证明的条件下显着降低量化误差。借助这个理论认识,NoisyQuant取得了首次成功,使用加性噪声偏差积极改变重尾激活分布以适应给定的量化器。大量实验证明,NoisyQuant可以在最小的计算开销下大大提高视觉Transformer的后训练量化性能。例如,在线性均匀6位激活量化中,NoisyQuant提高了ViT、DeiT和Swin Transformer在ImageNet上的SOTA top-1精度,分别为1.7%、1.1%和0.5%,实现了与以前的非线性、混合精度量化相当甚至更高的性能。