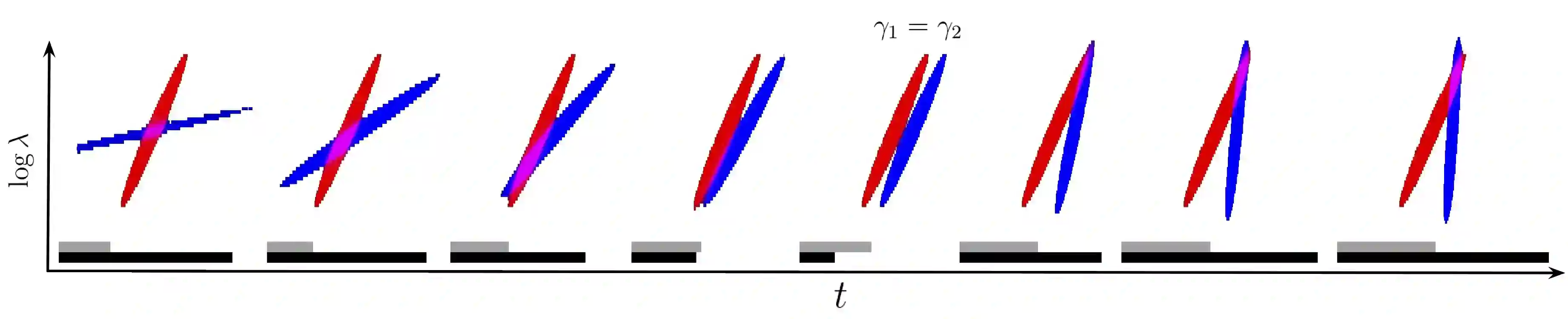
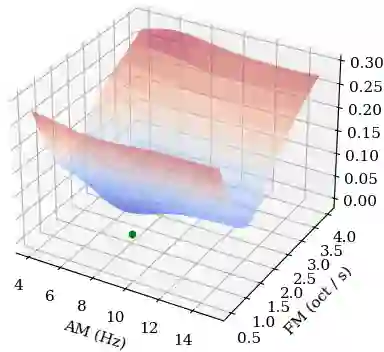
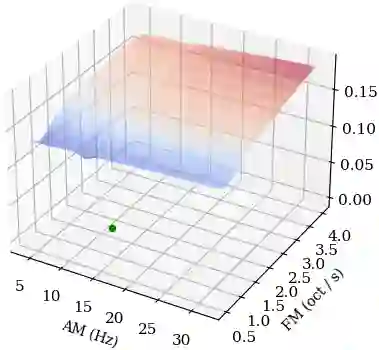
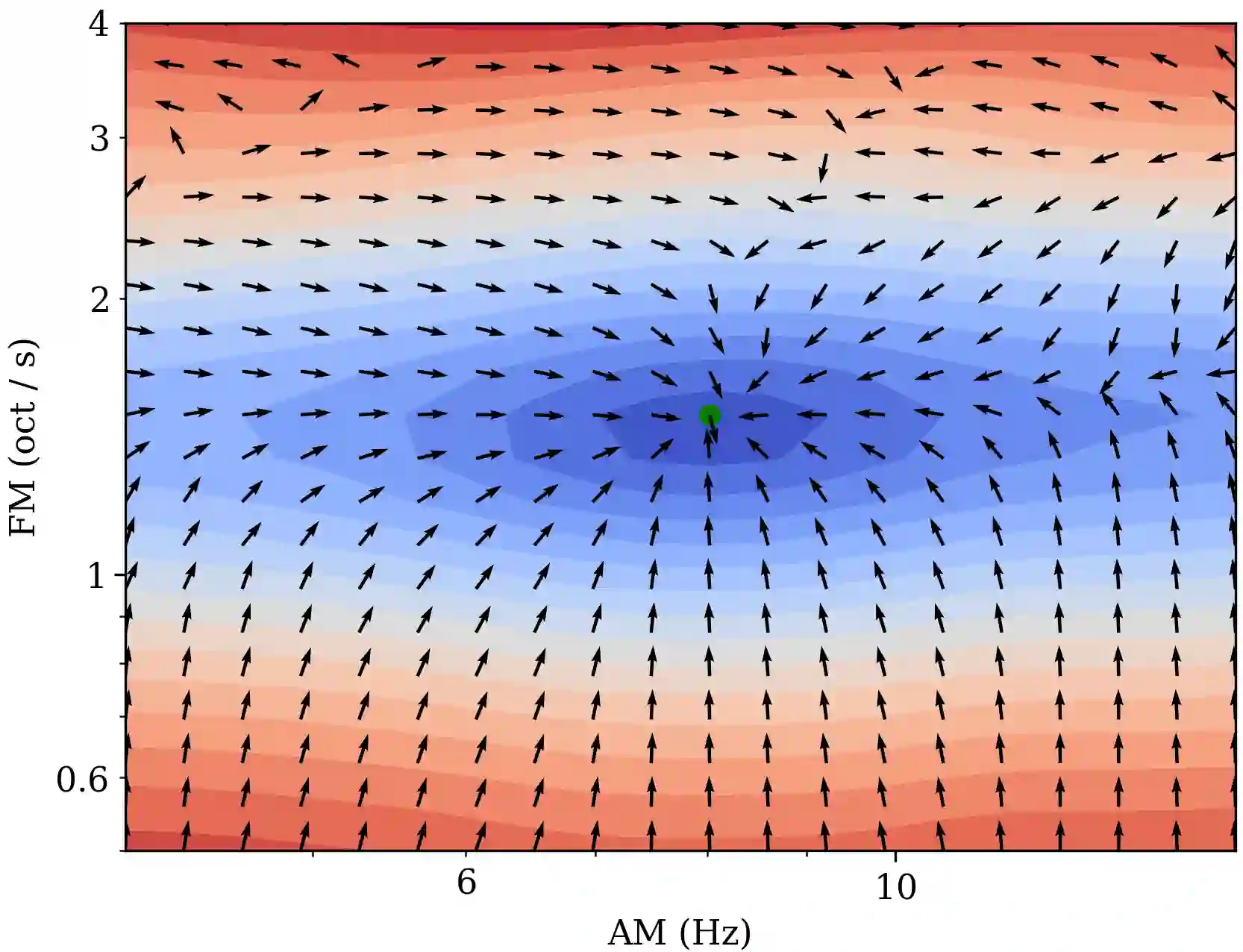
Computer musicians refer to mesostructures as the intermediate levels of articulation between the microstructure of waveshapes and the macrostructure of musical forms. Examples of mesostructures include melody, arpeggios, syncopation, polyphonic grouping, and textural contrast. Despite their central role in musical expression, they have received limited attention in deep learning. Currently, autoencoders and neural audio synthesizers are only trained and evaluated at the scale of microstructure: i.e., local amplitude variations up to 100 milliseconds or so. In this paper, we formulate and address the problem of mesostructural audio modeling via a composition of a differentiable arpeggiator and time-frequency scattering. We empirically demonstrate that time--frequency scattering serves as a differentiable model of similarity between synthesis parameters that govern mesostructure. By exposing the sensitivity of short-time spectral distances to time alignment, we motivate the need for a time-invariant and multiscale differentiable time--frequency model of similarity at the level of both local spectra and spectrotemporal modulations.
翻译:计算机音乐家认为中观结构是波形微结构与音乐形式宏观结构之间的中间交汇层。 中观结构的例子包括旋律、 旋律、 同步、 多声组合和质谱对比。 尽管他们在音乐表达中起着核心作用,但在深层学习中却受到的关注有限。 目前, 自动演算器和神经音频合成器仅受到微结构规模的培训和评估: 即, 本地振幅变化可高达100毫秒左右左右。 在本文中, 我们通过不同可调制和时频分散的组合来制定和解决中观结构音量建模问题。 我们从经验上表明, 时频分散是管理中观结构的合成参数之间相似性的不同模型。 通过暴露短时光谱距离与时间对齐的敏感度,我们提出需要在当地光谱和光谱光谱和光谱模模模的类似性时频模型。