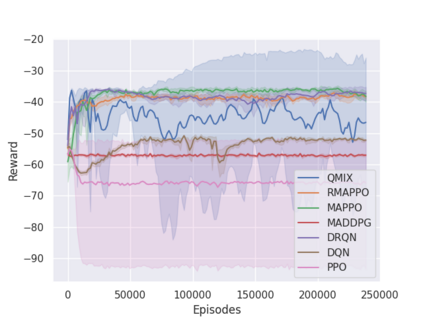
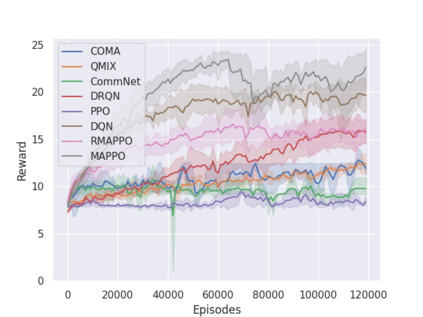
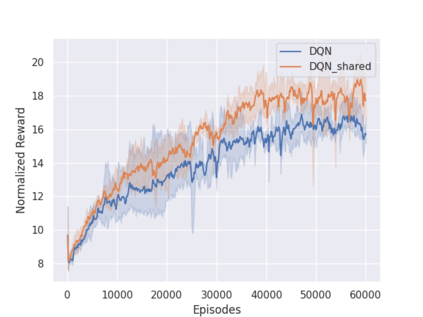
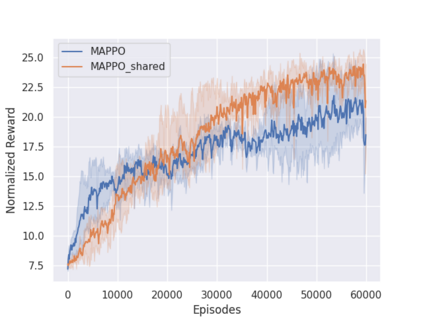
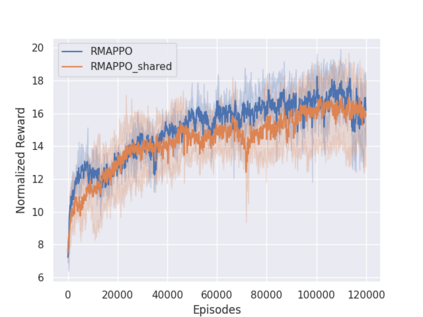
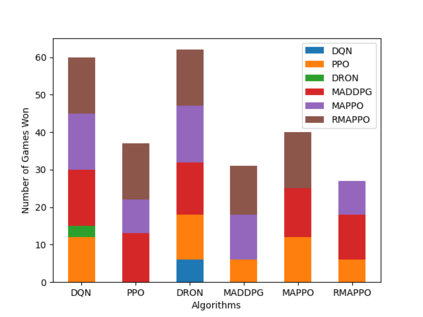
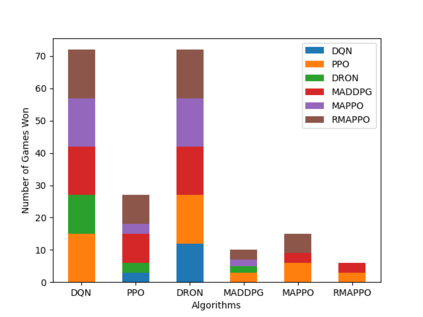
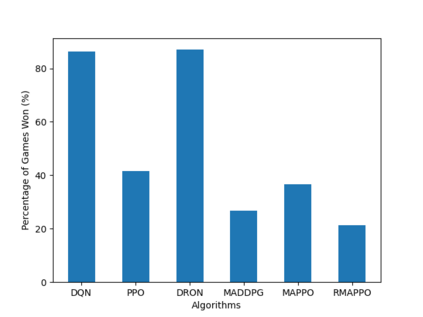
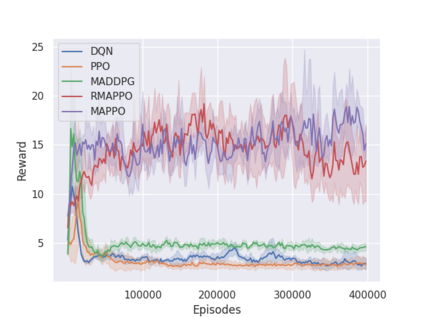
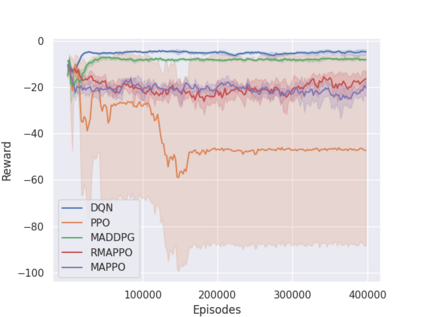
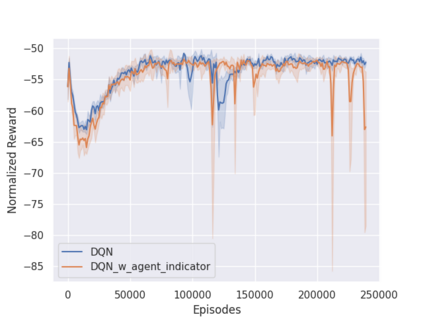
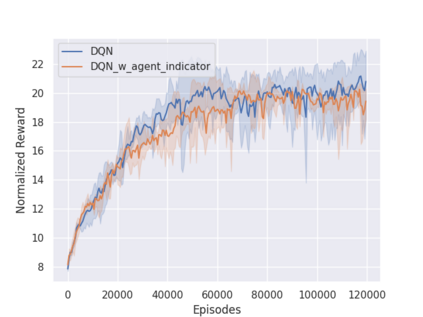
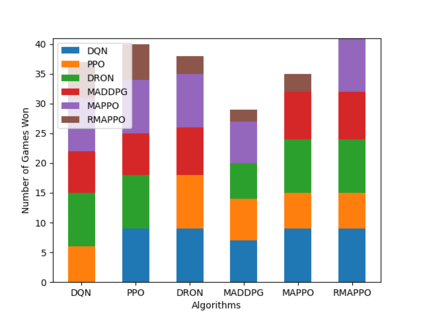
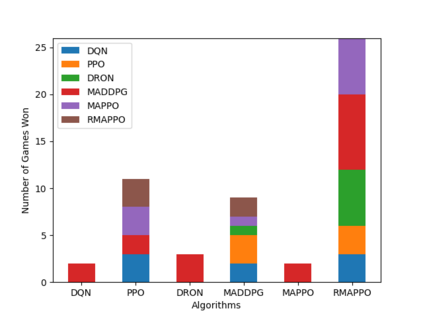
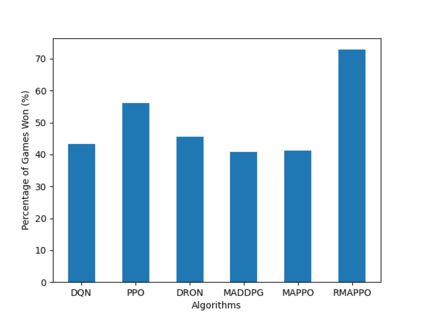
Independent reinforcement learning algorithms have no theoretical guarantees for finding the best policy in multi-agent settings. However, in practice, prior works have reported good performance with independent algorithms in some domains and bad performance in others. Moreover, a comprehensive study of the strengths and weaknesses of independent algorithms is lacking in the literature. In this paper, we carry out an empirical comparison of the performance of independent algorithms on four PettingZoo environments that span the three main categories of multi-agent environments, i.e., cooperative, competitive, and mixed. We show that in fully-observable environments, independent algorithms can perform on par with multi-agent algorithms in cooperative and competitive settings. For the mixed environments, we show that agents trained via independent algorithms learn to perform well individually, but fail to learn to cooperate with allies and compete with enemies. We also show that adding recurrence improves the learning of independent algorithms in cooperative partially observable environments.
翻译:独立强化学习算法没有在多试剂环境下找到最佳政策的理论保障,但在实践中,以前的工作报告在某些领域采用独立算法的业绩良好,而在另一些领域则表现不佳。此外,文献中缺乏对独立算法的优缺点的全面研究。在本文中,我们对四个多试剂环境主要类别即合作、竞争和混合的宠物动物环境的独立算法的绩效进行了经验比较。我们表明,在完全可观测的环境中,独立算法可以在合作和竞争性环境中与多试剂算法同等地运作。在混合环境中,我们显示,通过独立算法培训的代理人学会了个人良好表现,但是没有学会与盟友合作,也没有与敌人竞争。我们还表明,在合作部分可观察的环境中,再增加独立算法的学习会改善部分可观察的合作环境中的独立算法的学习。