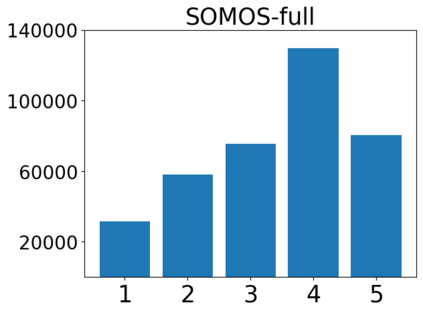
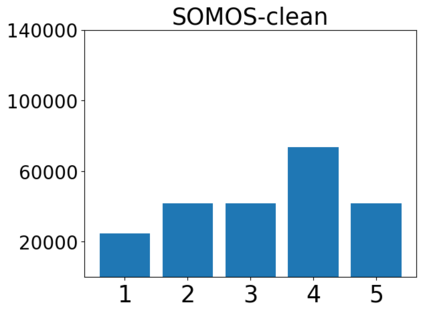
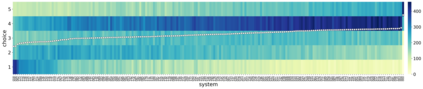
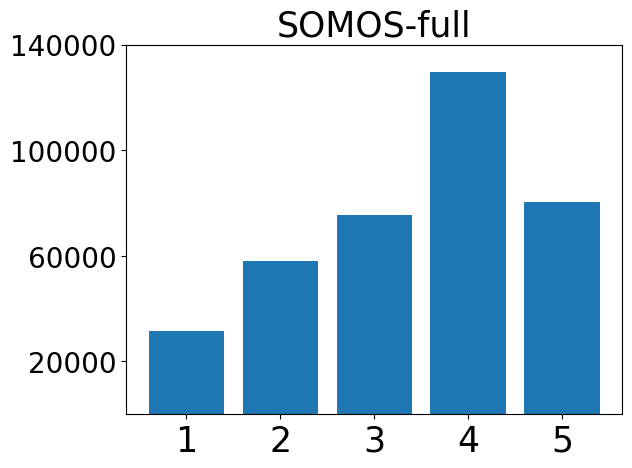
In this work, we present the SOMOS dataset, the first large-scale mean opinion scores (MOS) dataset consisting of solely neural text-to-speech (TTS) samples. It can be employed to train automatic MOS prediction systems focused on the assessment of modern synthesizers, and can stimulate advancements in acoustic model evaluation. It consists of 20K synthetic utterances of the LJ Speech voice, a public domain speech dataset which is a common benchmark for building neural acoustic models and vocoders. Utterances are generated from 200 TTS systems including vanilla neural acoustic models as well as models which allow prosodic variations. An LPCNet vocoder is used for all systems, so that the samples' variation depends only on the acoustic models. The synthesized utterances provide balanced and adequate domain and length coverage. We collect MOS naturalness evaluations on 3 English Amazon Mechanical Turk locales and share practices leading to reliable crowdsourced annotations for this task. We provide baseline results of state-of-the-art MOS prediction models on the SOMOS dataset and show the limitations that such models face when assigned to evaluate TTS utterances.
翻译:在这项工作中,我们展示了SOMOS数据集,这是第一个由神经文字到语音样本(TTS)样本组成的大型中位意见分数(MOS)数据集,可以用来培训侧重于现代合成器评估的自动MOS预测系统,并能够刺激声学模型评估的进展。该数据集由LJ Speales声音的20K合成表达式组成,这是一个公共域话语数据集,是建立神经声模型和电解器的共同基准。Utterances来自200 TTS系统,包括香草神经声学模型,以及允许产生偏差的模型。所有系统都使用了LPCNet vocoder,因此样本的变异只取决于声学模型。合成话提供了均衡和适当的域和长度覆盖。我们收集了3个英国亚马逊机械土耳其语地区的MOS自然状态评估,并分享了为这项任务提供可靠的人群源说明的做法。我们提供了SOMS预测模型的基线结果,并展示了在SOMS数据集评估时所指定的模型所面临的局限性。