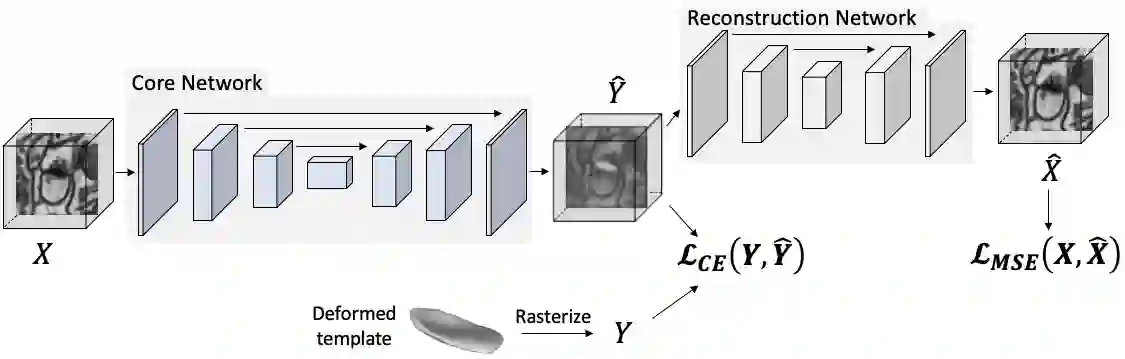
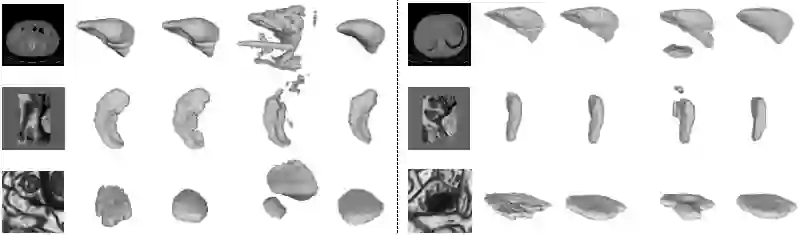
There are many approaches to weakly-supervised training of networks to segment 2D images. By contrast, existing approaches to segmenting volumetric images rely on full-supervision of a subset of 2D slices of the 3D volume. We propose an approach to volume segmentation that is truly weakly-supervised in the sense that we only need to provide a sparse set of 3D points on the surface of target objects instead of detailed 2D masks. We use the 3D points to deform a 3D template so that it roughly matches the target object outlines and we introduce an architecture that exploits the supervision it provides to train a network to find accurate boundaries. We evaluate our approach on Computed Tomography (CT), Magnetic Resonance Imagery (MRI) and Electron Microscopy (EM) image datasets and show that it substantially reduces the required amount of effort.
翻译:对 2D 图像部分的网络进行监管薄弱的培训有许多方法。 相反, 分解体积图像的现有方法依赖于3D 音量的2D 片段的全视。 我们建议对体积分解采取一种真正受监管薄弱的方法, 也就是说我们只需在目标对象表面提供一套稀疏的3D 点, 而不是详细的 2D 面罩。 我们用 3D 点来变形一个 3D 模板, 以便大致匹配目标对象的轮廓, 我们引入一个架构, 利用它所提供的监督来训练一个网络以找到准确的边界 。 我们评估了我们关于 Computut Tomgraphy (CT)、 Maget Resonance 图像(MRI) 和 电磁显微镜(EM) 图像数据集的方法, 并显示它大大降低了所需的工作量 。