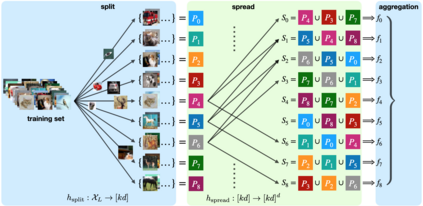
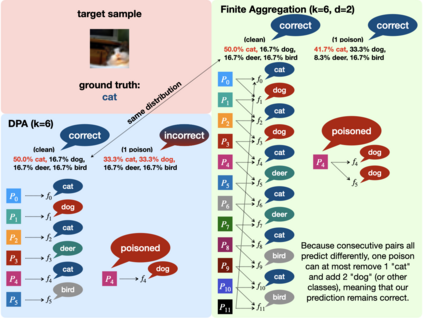
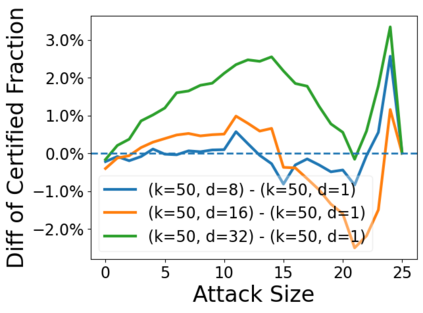
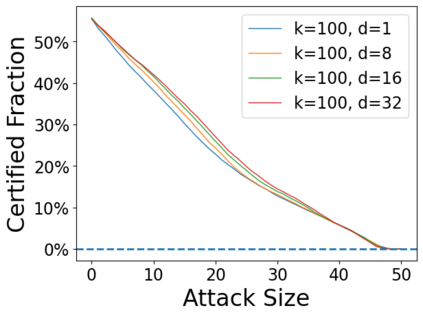
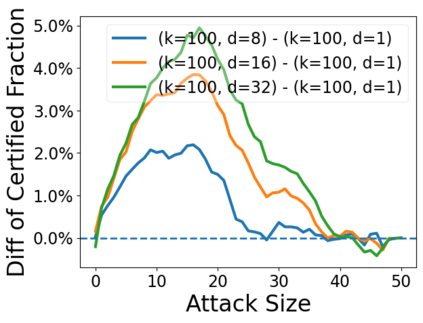
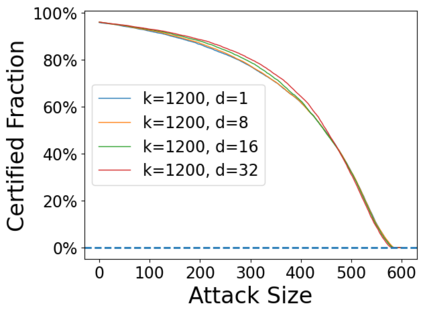
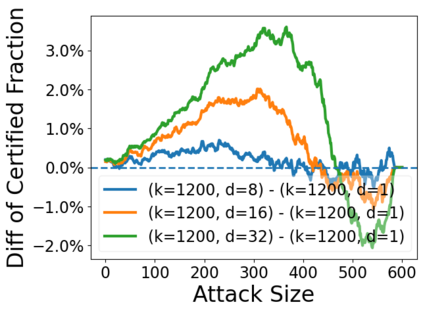
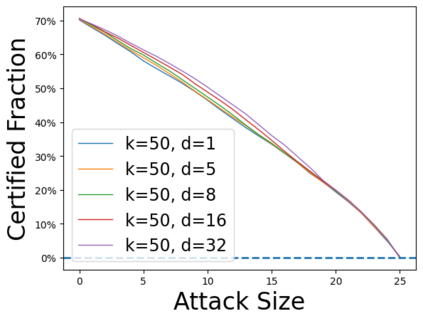
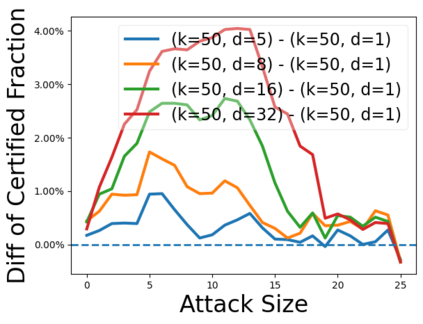
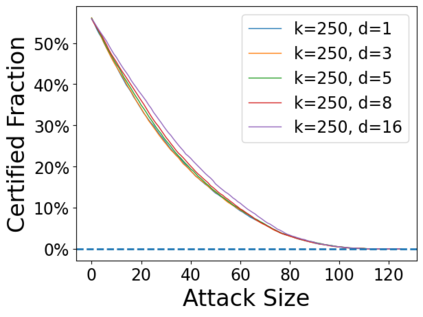
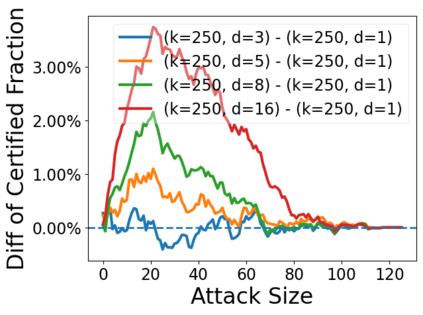
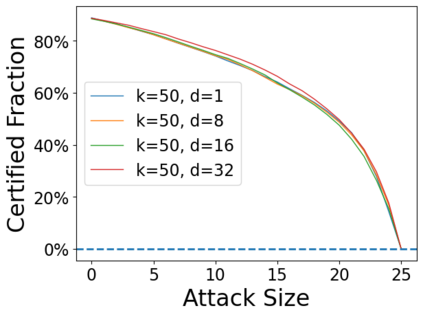
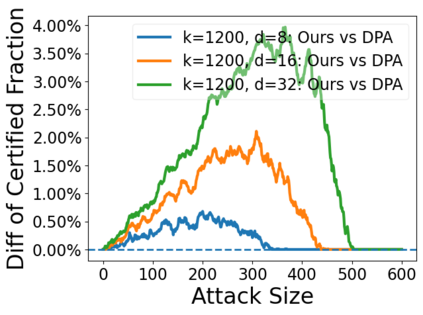
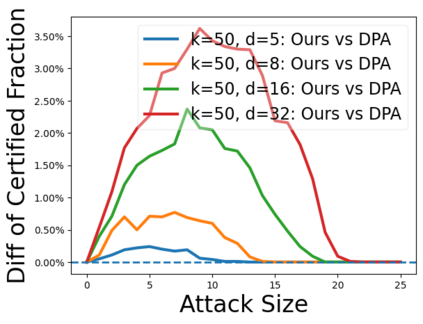
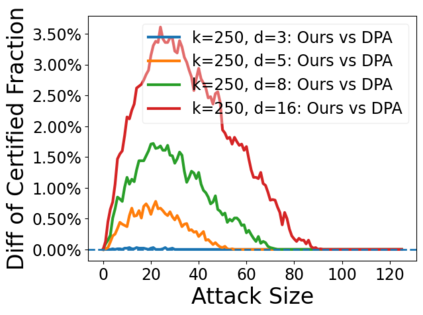
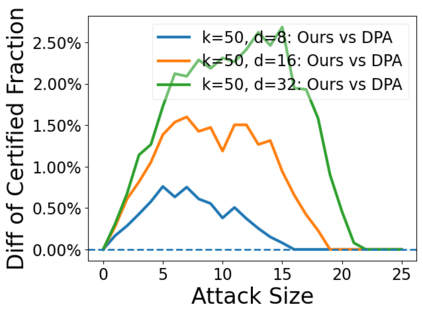
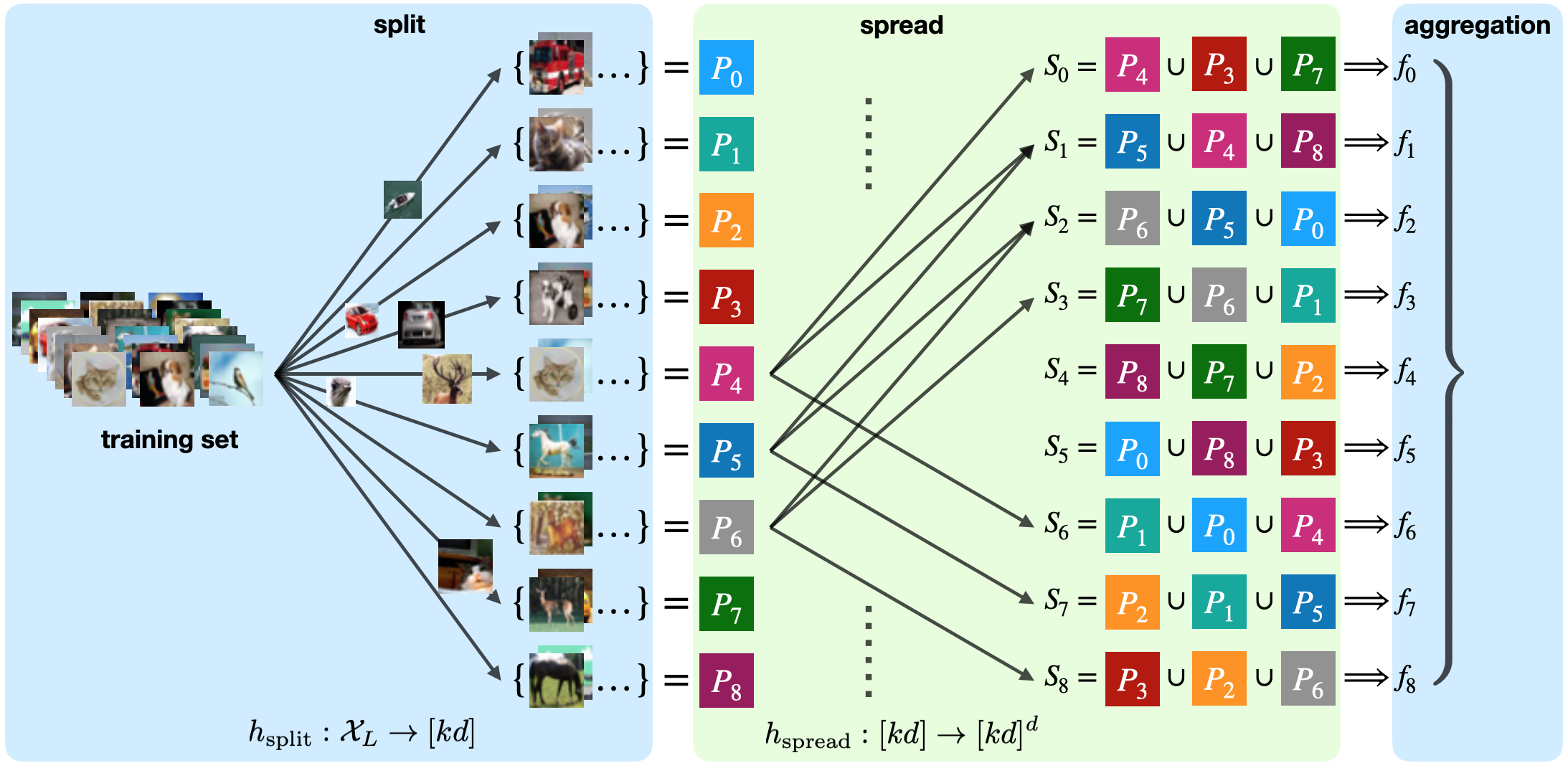
Data poisoning attacks aim at manipulating model behaviors through distorting training data. Previously, an aggregation-based certified defense, Deep Partition Aggregation (DPA), was proposed to mitigate this threat. DPA predicts through an aggregation of base classifiers trained on disjoint subsets of data, thus restricting its sensitivity to dataset distortions. In this work, we propose an improved certified defense against general poisoning attacks, namely Finite Aggregation. In contrast to DPA, which directly splits the training set into disjoint subsets, our method first splits the training set into smaller disjoint subsets and then combines duplicates of them to build larger (but not disjoint) subsets for training base classifiers. This reduces the worst-case impacts of poison samples and thus improves certified robustness bounds. In addition, we offer an alternative view of our method, bridging the designs of deterministic and stochastic aggregation-based certified defenses. Empirically, our proposed Finite Aggregation consistently improves certificates on MNIST, CIFAR-10, and GTSRB, boosting certified fractions by up to 3.05%, 3.87% and 4.77%, respectively, while keeping the same clean accuracies as DPA's, effectively establishing a new state of the art in (pointwise) certified robustness against data poisoning.
翻译:数据中毒袭击的目的是通过扭曲培训数据来操纵模型行为。 此前,曾提出过一个基于汇总的认证国防,即深分区聚合(DPA),以缓解这一威胁。 政治部通过在数据分解分解方面受过培训的基础分类人员汇总预测,从而限制数据对数据集扭曲的敏感性。 在这项工作中,我们建议改进对一般中毒袭击的认证防御,即Finite聚合。 与直接将培训分成不连子的《和平协议》相比,我们提出的方法首先将培训分解成较小的分解子组,然后将培训组的重复部分合并起来,为培训基础分类人员建立更大的(但并非脱节)子组。这减少了毒药样品最坏情况的影响,从而改善了经认证的稳健性约束。 此外,我们提出了一种替代方法,即弥合基于总毒物集中的确定性设计。 与直接将培训分解成分解成分解子组的《和平协议》,我们提议的“FIRA-10”和“GTSRB”的认证方法一致地改进了对MIT的认证分解证书,通过3.05、8.%和4.77号分别将清洁分解,同时维持新的安全数据。