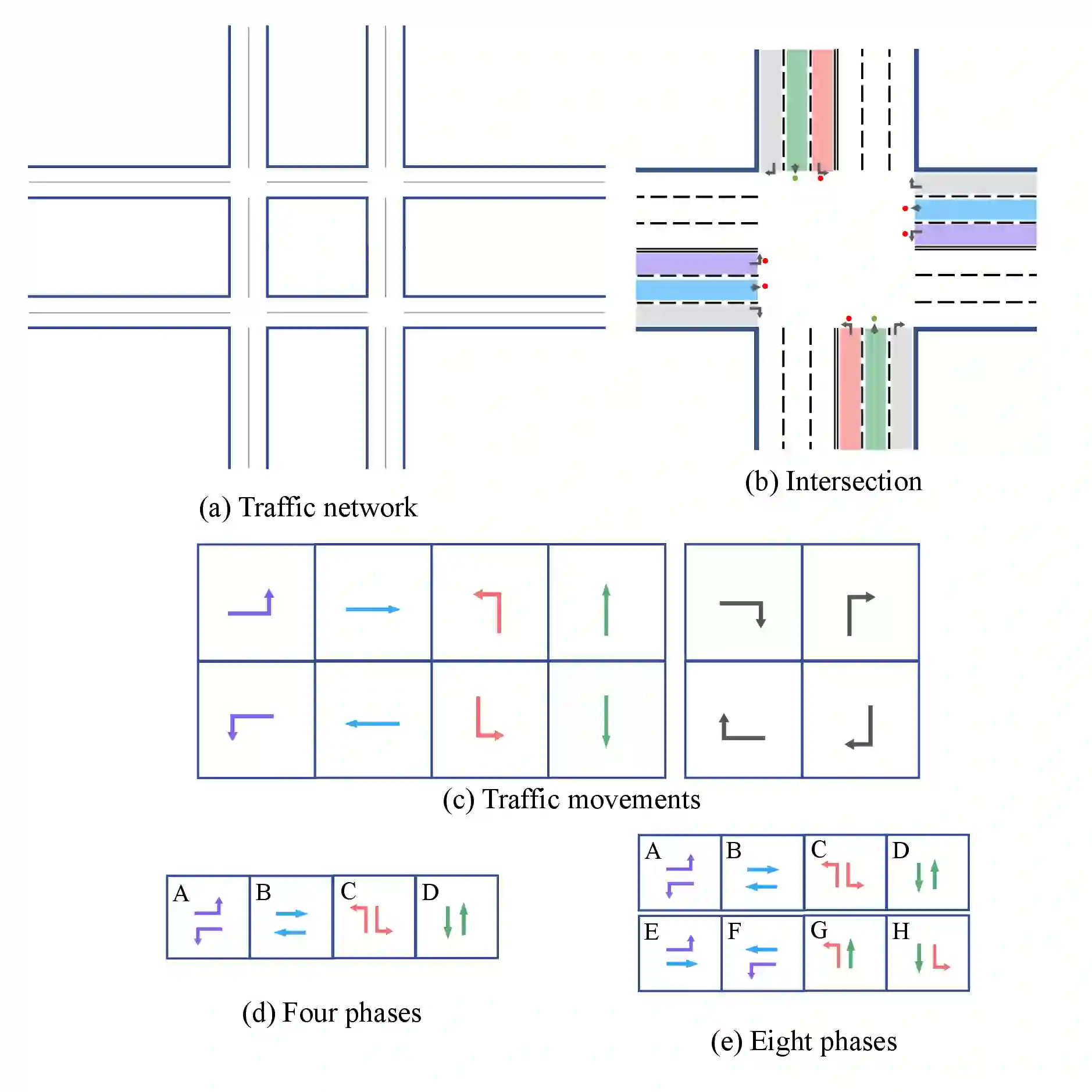
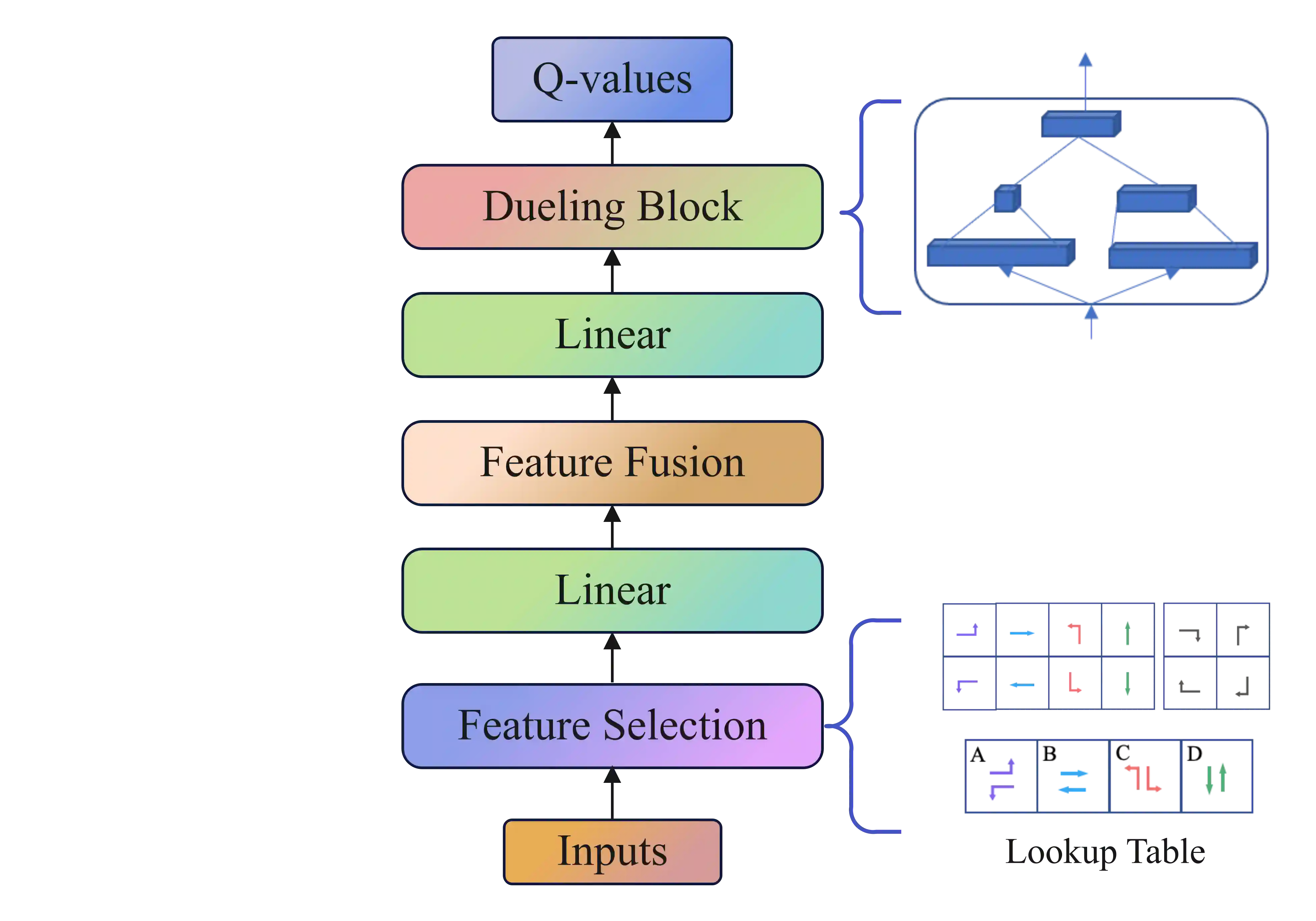
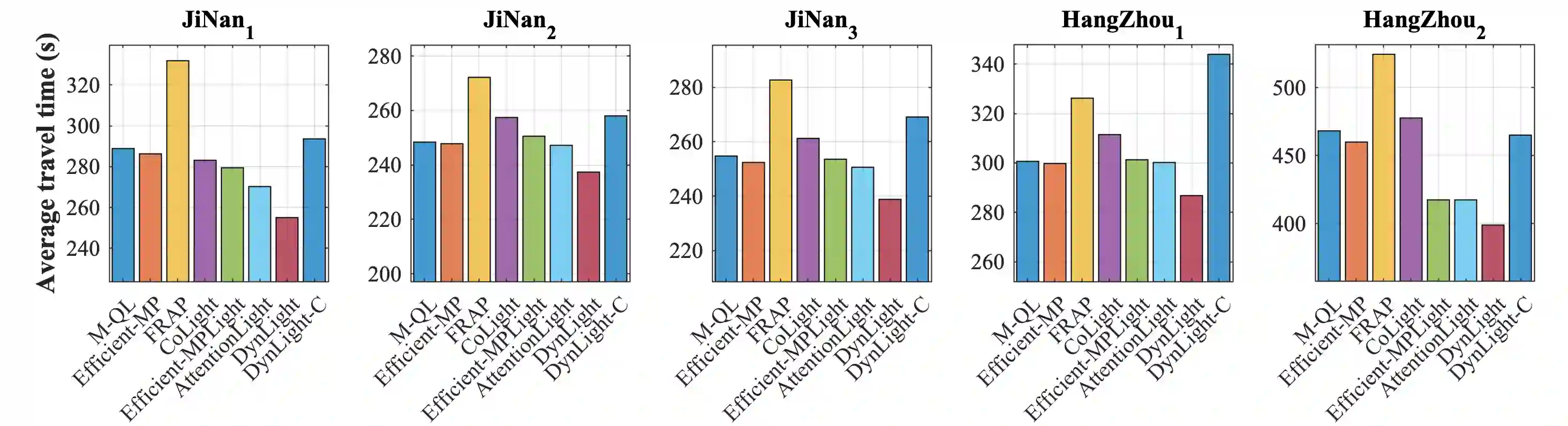
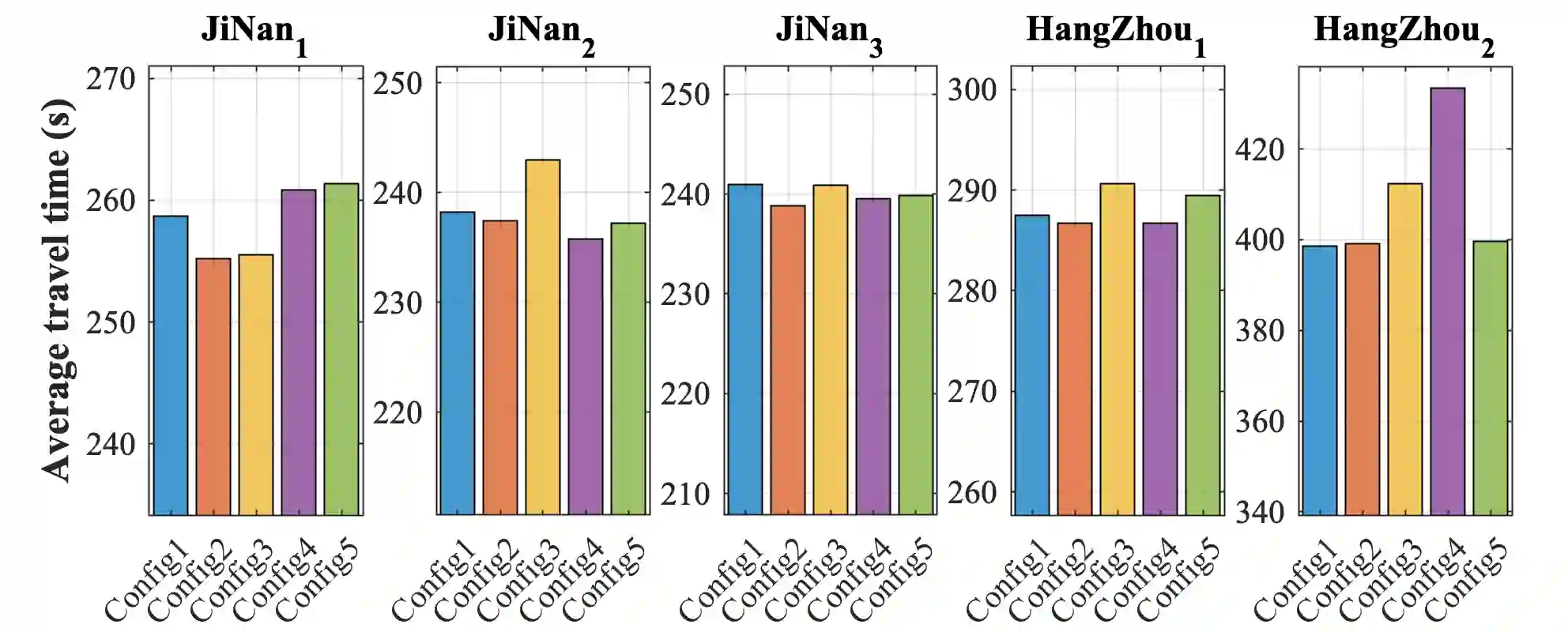
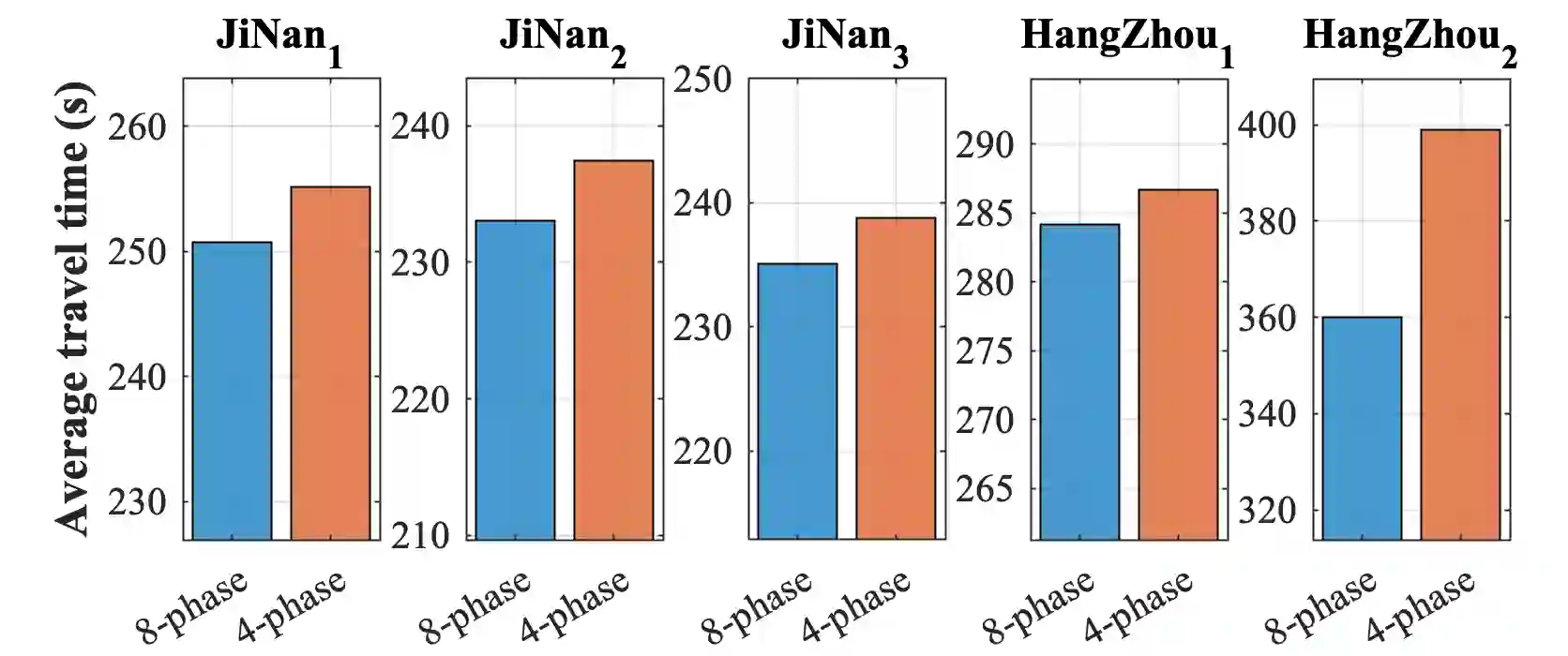
Adopting reinforcement learning (RL) for traffic signal control (TSC) is increasingly popular, and RL has become a promising solution for traffic signal control. However, several challenges still need to be overcome. Firstly, most RL methods use fixed action duration and select the green phase for the next state, which makes the phase duration less dynamic and flexible. Secondly, the phase sequence of RL methods can be arbitrary, affecting the real-world deployment which may require a cyclical phase structure. Lastly, the average travel time and throughput are not fair metrics to evaluate TSC performance. To address these challenges, we propose a multi-level traffic signal control framework, DynLight, which uses an optimization method Max-QueueLength (M-QL) to determine the phase and uses a deep Q-network to determine the duration of the corresponding phase. Based on DynLight, we further propose DynLight-C which adopts a well-trained deep Q-network of DynLight and replace M-QL with a cyclical control policy that actuates a set of phases in fixed cyclical order to realize cyclical phase structure. Comprehensive experiments on multiple real-world datasets demonstrate that DynLight achieves a new state-of-the-art. Furthermore, the deep Q-network of DynLight can learn well on determining the phase duration and DynLight-C demonstrates high performance for deployment.
翻译:在交通信号控制方面采用强化学习(RL)的做法越来越受欢迎,而RL已成为交通信号控制的一个有希望的解决办法。然而,还需要克服若干挑战。首先,大多数RL方法使用固定行动期限,并为下一个州选择绿色阶段,从而使该阶段的持续时间不那么充满活力和灵活性。第二,RL方法的阶段序列可能是任意的,影响到可能需要周期阶段结构的现实世界部署。最后,平均旅行时间和吞吐量不是评价交通信号控制绩效的公平衡量标准。为了应对这些挑战,我们提议了一个多层次交通信号控制框架,即DynLight(DynLight),它使用优化方法确定该阶段,并使用深Q-网络来确定相应阶段的期限。根据DynLight,我们进一步提议DynLight-C采用经过良好训练的深度Q-网络,以周期控制政策取代M-QL。我们提议采用一套固定周期性阶段,以达到周期性秩序,从而实现Dyn-Lyn(M-Lyn)的高级部署阶段,全面展示Dight-Lyn(Drow-L)阶段的深度运行周期阶段,从而显示跨世界数据学习阶段。