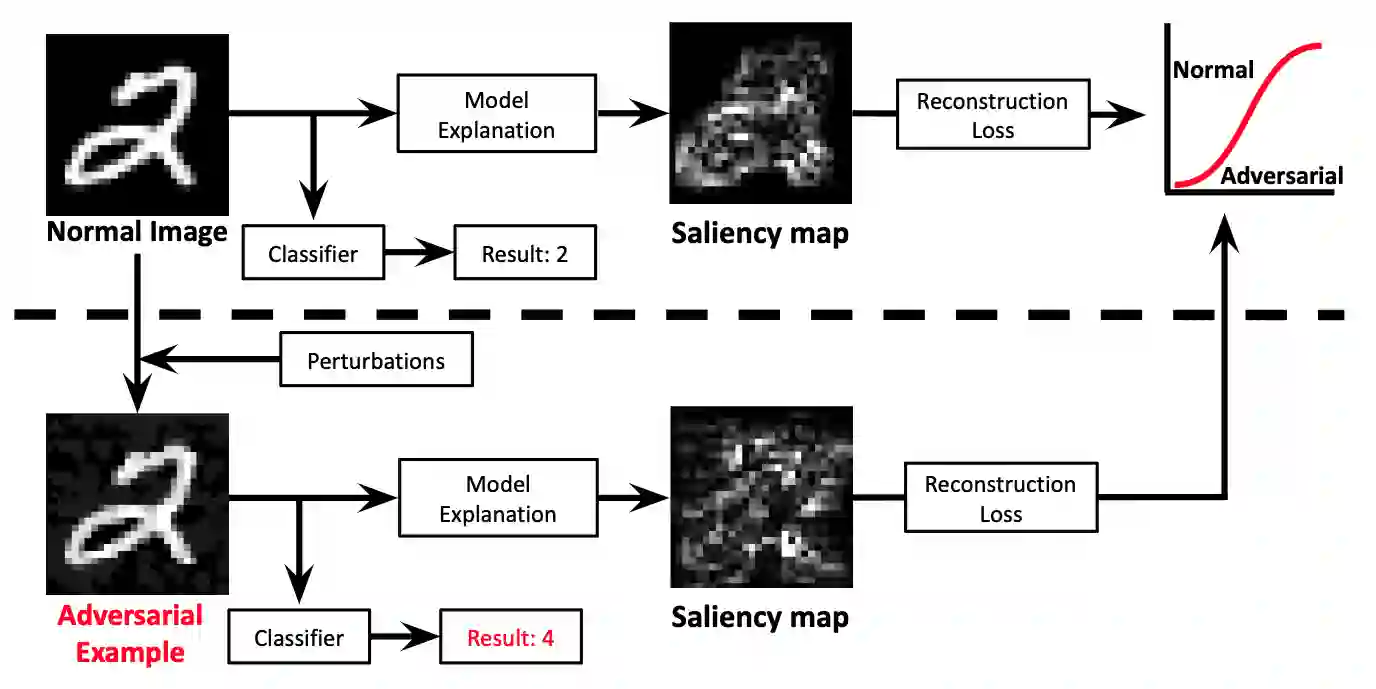
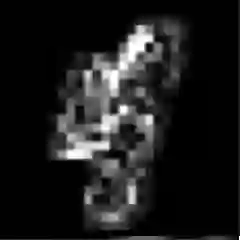
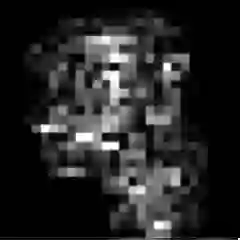
Deep Neural Networks (DNNs) have shown remarkable performance in a diverse range of machine learning applications. However, it is widely known that DNNs are vulnerable to simple adversarial perturbations, which causes the model to incorrectly classify inputs. In this paper, we propose a simple yet effective method to detect adversarial examples, using methods developed to explain the model's behavior. Our key observation is that adding small, humanly imperceptible perturbations can lead to drastic changes in the model explanations, resulting in unusual or irregular forms of explanations. From this insight, we propose an unsupervised detection of adversarial examples using reconstructor networks trained only on model explanations of benign examples. Our evaluations with MNIST handwritten dataset show that our method is capable of detecting adversarial examples generated by the state-of-the-art algorithms with high confidence. To the best of our knowledge, this work is the first in suggesting unsupervised defense method using model explanations.
翻译:深神经网络(DNN)在各种机器学习应用中表现出了显著的成绩。 但是,众所周知,DNN很容易受到简单的对抗性干扰,导致输入分类模型错误。 在本文中,我们提出了一个简单而有效的方法来检测对抗性实例,使用开发的方法来解释模型的行为。我们的主要观察是,增加小的、人类无法察觉的干扰可能导致模型解释的急剧变化,从而导致不同寻常或不正常的解释形式。我们从这一角度出发,我们建议对对抗性实例进行不受监督的检测,使用重建网络,只对良性实例进行示范解释。我们对MNIST手写数据集的评估表明,我们的方法能够非常自信地探测由最先进的算法生成的对抗性实例。据我们所知,这项工作是在建议使用模型解释的非超强防御方法方面所做的第一项工作。