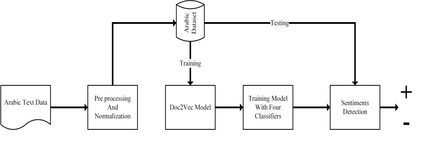
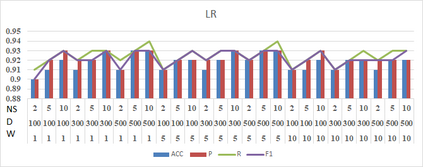
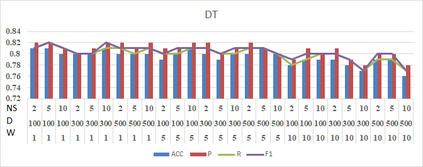
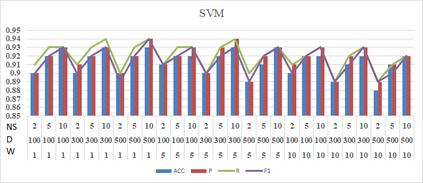
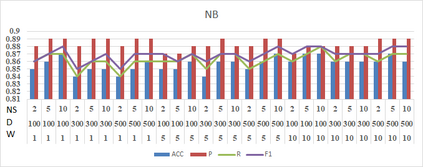
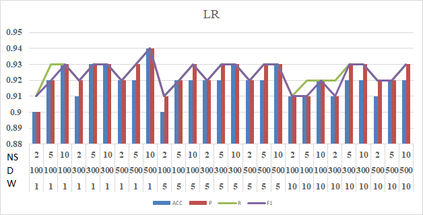
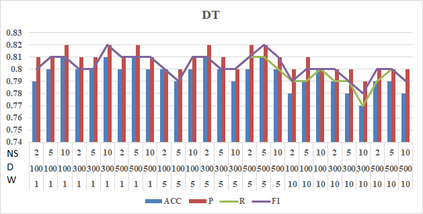
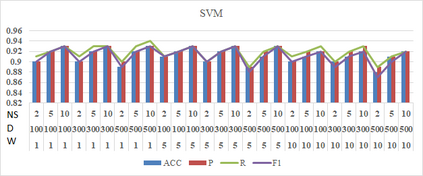
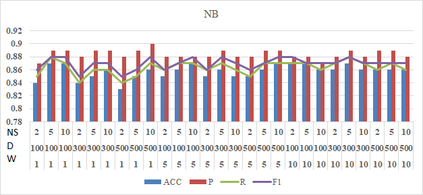
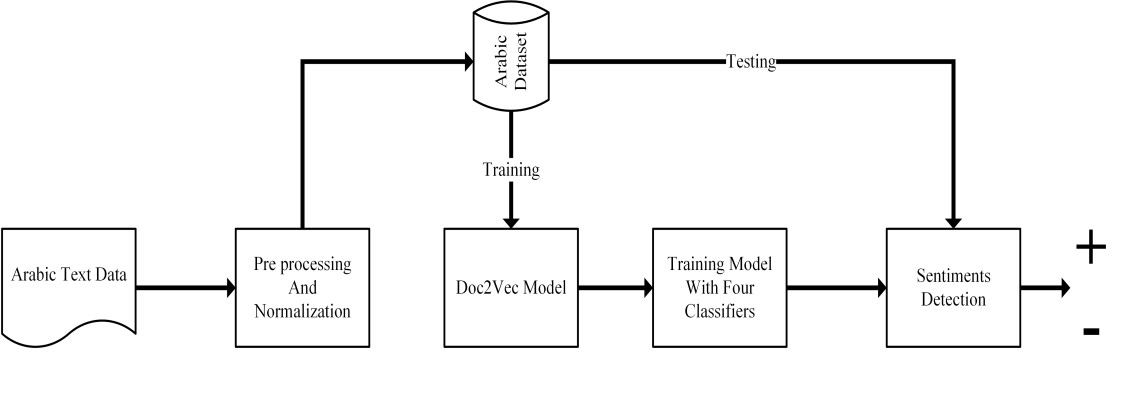
Social media such as Twitter, Facebook, etc. has led to a generated growing number of comments that contains users opinions. Sentiment analysis research deals with these comments to extract opinions which are positive or negative. Arabic language is a rich morphological language; thus, classical techniques of English sentiment analysis cannot be used for Arabic. Word embedding technique can be considered as one of successful methods to gaping the morphological problem of Arabic. Many works have been done for Arabic sentiment analysis based on word embedding, but there is no study focused on variable parameters. This study will discuss three parameters (Window size, Dimension of vector and Negative Sample) for Arabic sentiment analysis using DBOW and DMPV architectures. A large corpus of previous works generated to learn word representations and extract features. Four binary classifiers (Logistic Regression, Decision Tree, Support Vector Machine and Naive Bayes) are used to detect sentiment. The performance of classifiers evaluated based on; Precision, Recall and F1-score.
翻译:社交媒体,如Twitter、Facebook等,产生了越来越多的载有用户意见的评论。感知分析研究涉及这些评论,以得出正面或负面的意见。阿拉伯语是一种丰富的形态语言;因此,英语情绪分析的古典技术不能用于阿拉伯语。文字嵌入技术可以被视为弥合阿拉伯语形态问题的成功方法之一。许多基于文字嵌入的阿拉伯情绪分析工作已经完成,但没有研究以变量参数为重点。这项研究将讨论使用 DBOW 和 DMPV 结构进行阿拉伯语情绪分析的三个参数(温多、矢量尺寸和负抽样)。以前为学习文字表达和摘要特征而制作的大量作品。使用四种二进制分类器(Logistric Returation、决定树、支持矢量机器和养蜂湾)来检测情绪。根据精度、回调和F1-分数评估的分类器的性能。