论文 | 中文词向量论文综述(二)
| 作者:黑龙江大学nlp实验室研究生刘宗林
论文来源
这是一篇2016年发表在NAACL-HLT(Annual Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies)会议上的论文,作者来自于中国科学技术大学 --- Jian Xu。
Abstract
这篇论文的做法比较奇特,而且中间步骤很多。 已经在前面提到的两篇论文表明中文汉字内部的包含了丰富的语义信息,对中文词向量的表示有着很重要的作用,这篇论文也是基于此来进行相关工作。
具体来说,是基于前面的CWE模型,虽然CWE已经考虑了词的内部组成,增加了语义信息的表示,然而,却忽略了一些问题,在每一个词和他们的组成部分(单字)之间,CWE把单字和词之间的贡献作为一致的,这篇论文提出,他们之间的贡献度应该是不同的,CWE忽略了这一问题,本文要利用外部语言来获取语义信息,计算词与单字之间的相似度来表示其贡献的不同,完善相关工作。
论文提出了联合学习词与字的方法,该方法可以消除中文单字的歧义性,也可以区别出词内部无意义的组成,实验结果表明在 Word Similarity 和 Text Classification 上验证了其有效性。
Methodology and Model
论文提出的方法可以分为以下几个阶段,Obtain translations of Chinese words and characters,Perform Chinese character sense disambiguation,Learn word and character embeddings with our model。
Obtain translations of Chinese words and characters
对中文训练语料使用分词工具进行分词,分词工具可以采用jieba,Zpar,thulac,对分词之后的数据进行词性标注(Part-of-Speech tagging),词性标注的目的是识别出所有的实体(这里的实体,应该是词性),因为实体词是没有语义信息的,这些词被定义为non-compositional word,也就是词的内部组成是没有意义的。
这里使用了字频来做了下面的一个筛选,提出计算不同词内部单字出现的数量,我称之为字频,字频较低的那些词被认定为是single-morpheme multi-character words (像徘徊,琵琶這样的词语,其中的单字很难在其他的词语中使用),定义为 non-compositional word。
下一步的工作让人意想不到,把中文词语翻译成了英文,但是这里面并不包含无意义的词(non-compositional word),翻译成英文是为了下面的工作 --- Perform Chinese character sense disambiguation。
Perform Chinese character sense disambiguation
这里的工作主要是对中文一字多义的单字消除歧义性,对上文得到的英文语料,通过CBOW模型对这份语料进行训练,得到一份英文词向量,对其中区别不是很大的字符进行合并。
在中文中,相同的词和字符,虽然被应用为不同的词性,但是想要表达的语义信息是一样的。因此,这些被合并为一个,共用一个语义表示。如下图,多个乐字可能仅仅在不同的词性之间有所不同,然而语义信息几乎相同。
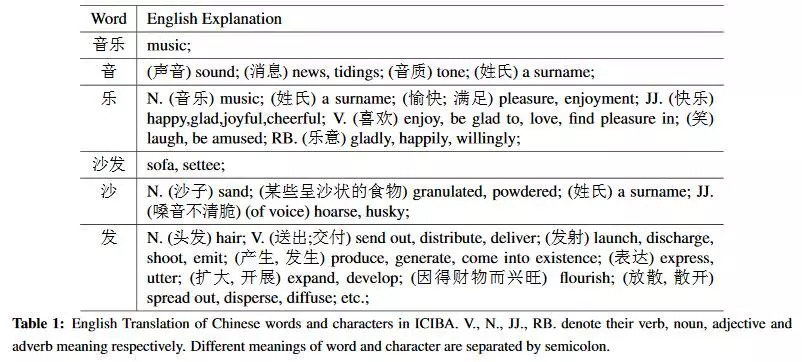
通过计算相似度来消除歧义,具体的公式如下, 其中c_i,c_j代表的是某个词中的第几个字,Trans(c_i)表示这个字的英文,stop-words(en)代表英文的停用词,x是Trans中的英文,具体来说,看上图,对于音乐这个词,c_1表示音,c_2表示乐,Trans(c_2)表示的是乐在上图中的英文集合,x_3就是pleasure或者是enjoyment。
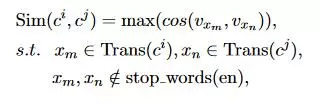
根据上图的公式就可以计算出字之间的相似度,如果这个值超过了某一个阈值,合并为同一个语义表示。对此,还进行了简化,都是针对一个词被翻译成多个英文的处理,其中一个是把字英文集合取平均值然后计算similarity,另外一个是在所有的候选英文词对中选择相似度值最大的,根据实验表明,后一种方案效果更佳。根据相似度,就可以把简单的解决一下字的歧义性。
如果max(Sim(x_t, c_k)) > w, c_k是x_t中的第几个字,这样x_t就被定义为 compositional word,对于 compositional word 定义如下图,对于音乐这个词来说,就被定义为(“音乐”, {Sim(“音乐”, “音”), Sim(“音乐”, “ 乐”)},{1,1})。
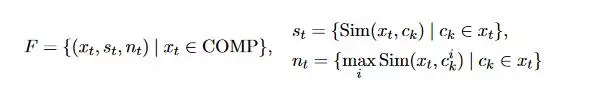
Learn word and character embeddings with our model --- SCWE
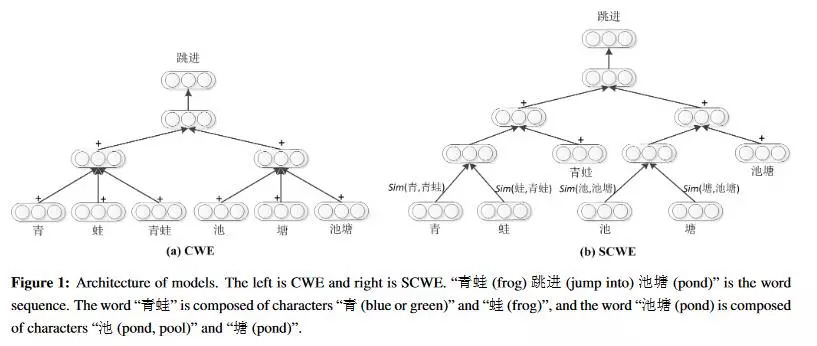
下图是论文中给出的CWE和SCWE的模型图, 根据上文的几个阶段和SCWE的模型图,应该可以理解这篇论文的意图。
在SCWE中词的向量被表示为下图,
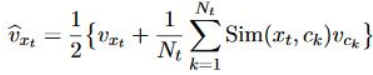
在SCWE的基础之上,又提出了SCWE+M模型,和SCWE差不多,只是根据上文提供的F的最后一个元素特征,对于字的不同意义采用不同的character embedding,具体词向量表示如下图。
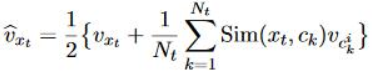
Experiment Result
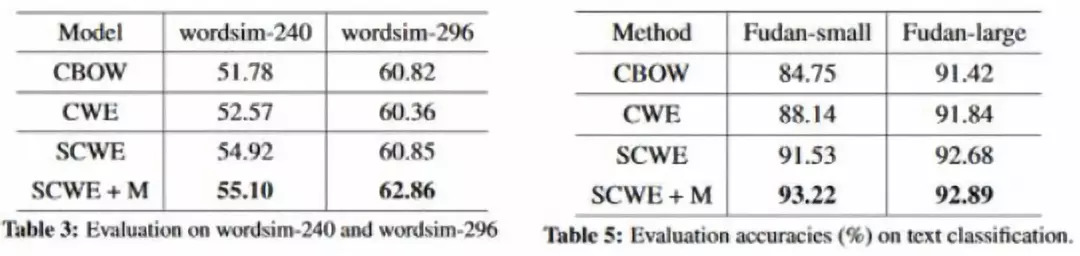
在 Word Similarity 和 Text Classification 上验证了其有效性,Word Similarity同样采用的评测文件是wordsim-240,wordsim-296,Text Classification采用的是 Fudan Corpus,具体的实验结果如下图:
论文来源
这是一篇2016年发表在EMNLP(Empirical Methods in Natural Language Processing)会议上的论文,作者来自于信息内容安全技术国家工程实验室 --- 殷荣超。
Abstract
与英文等西方语言相比,一个中文词通常有很多单个汉字组成,汉字又可以分解成许多的组件,部首就是其中的一个组件,而且其内部丰富的语义信息更能表达词的意义,在目前存在的中文词向量模型中,并没有充分的利用這一特征。基于此,提出了multi-granularity embedding (MGE)模型,其核心思想是充分利用其word-character-radical组成部分,更加细粒度的结合character和radical(部首)来增强词的向量表示。在word similarity 和 analogical reasoning任务上验证了其有效性。
Model
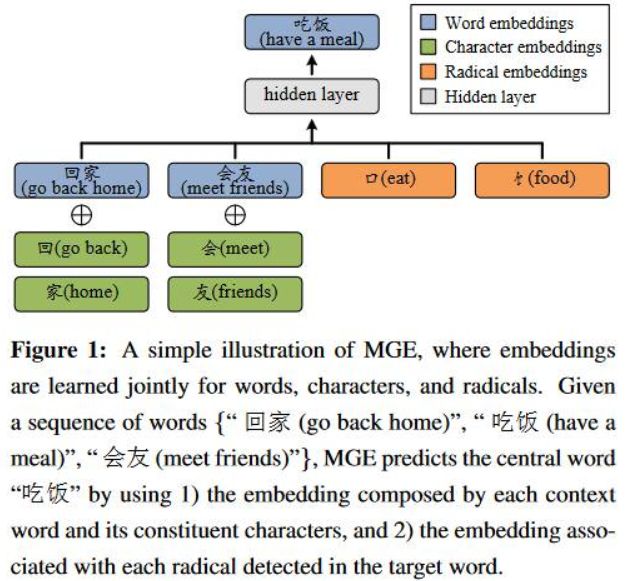
MGE的目的是联合学习word,character,radical,模型的结构是基于CBOW来完成的,如下图所示, 其中蓝色部分是上下文,绿色部分是上下文词的character,黄色部分是目标词的radical。根据图中的例子,给定的序列是 :”回家,吃饭,会友“,目标词是会友。
具体的表示如下,MGE的目标函数如下图,
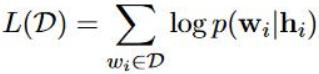
h_i是一个隐层表示,具体表示如下图,具体来说就是对于每一个上下文的词, 对其所有的character embedding求和取平均,然后和word embedding进行addition操作,然后对所有的上下文词求和取平均,這样就完成了word 和 character的结合,对于目标词所有的radical也是一样的求和取平均的操作,然后word+character与radical再次求和取平均,這样就完成了h_的隐层表示,至于word和character结合的时候,中间的那个操作符号,可以是addition,也可以是concatenation,這篇论文采用的是addition操作。
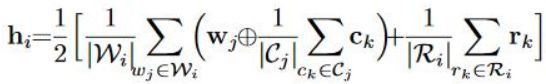
也和CWE模型存在一样的问题,一字多义,音译词等character没有意义的词,follow了CWE的做法,提出了MGE+P模型,目的和CWE一样,增加其位置信息,Begin,Middle,End。
Experiment Result
在 Word Similarity 和 Analogical Reasoning 上验证了其有效性。
Word Similarity同样采用的评测文件是wordsim-240,wordsim-296,但是对其进行了一定的删减,把两份评测文件中没有在训练语料中出现的词进行了删减,分别删减了一个词和三个词,得到了两份新的评测文件,wordsim-239,wordsim-293 ,具体的实验结果如下图。
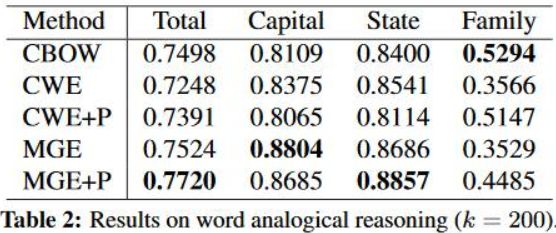
Analogical Reasoning采用的是Chen 2015年构造的评测文件,由于所有的词都包含在训练语料中,没有对這个数据进行删减,具体的实验结果如下图。
[1] Improve Chinese Word Embeddings by Exploiting Internal Structure
[2] Multi-Granularity Chinese Word Embedding


推荐阅读
基础 | TreeLSTM Sentiment Classification
原创 | Simple Recurrent Unit For Sentence Classification
原创 | Attention Modeling for Targeted Sentiment
 欢迎关注交流
欢迎关注交流



