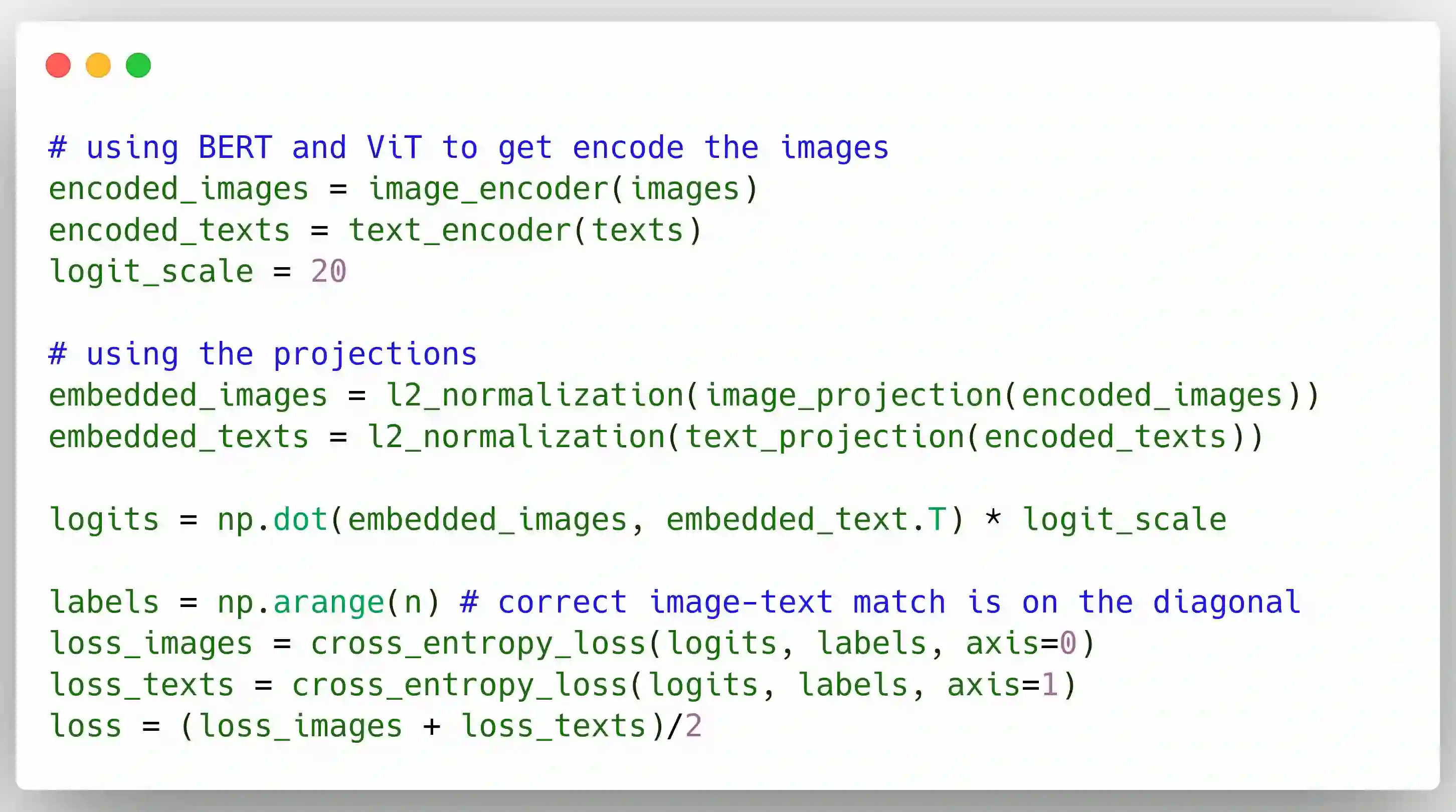
CLIP (Contrastive Language-Image Pre-training) is a very recent multi-modal model that jointly learns representations of images and texts. The model is trained on a massive amount of English data and shows impressive performance on zero-shot classification tasks. Training the same model on a different language is not trivial, since data in other languages might be not enough and the model needs high-quality translations of the texts to guarantee a good performance. In this paper, we present the first CLIP model for the Italian Language (CLIP-Italian), trained on more than 1.4 million image-text pairs. Results show that CLIP-Italian outperforms the multilingual CLIP model on the tasks of image retrieval and zero-shot classification.
翻译:CLIP(培训前语言图像控制)是一个非常近期的多模式模型,共同学习图像和文本的表现形式,该模型在大量英文数据上接受培训,并展示了在零发分级任务上令人印象深刻的成绩;对同一模型进行不同语言的培训并非微不足道,因为其他语言的数据可能不够,模型需要高质量的文本翻译,以保证良好的表现;在本文件中,我们介绍了意大利语(意大利语-意大利语)的第一个CLIP模型,该模型经过140多万对图像-文本的培训;结果显示,CLIP-意大利语在图像检索和零发分级任务上超过了多语种的CLIP模型。