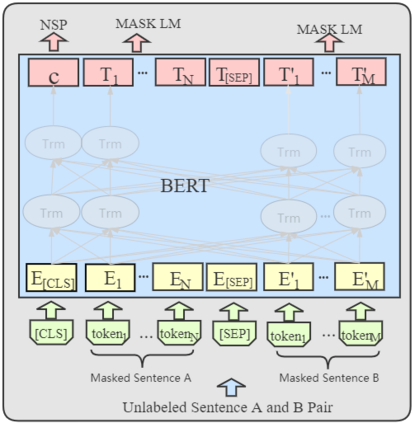
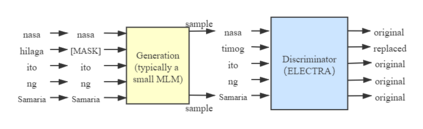
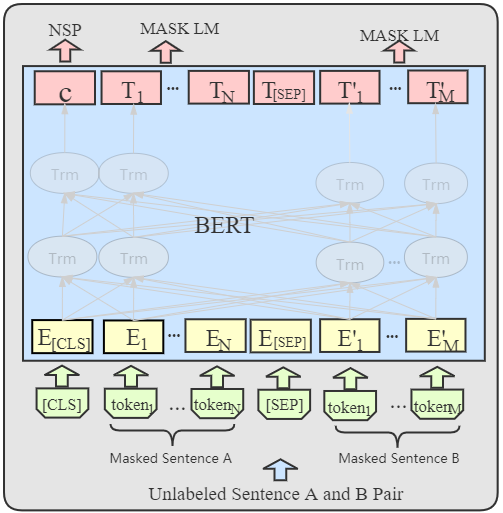
Trained on the large corpus, pre-trained language models (PLMs) can capture different levels of concepts in context and hence generate universal language representations. They can benefit multiple downstream natural language processing (NLP) tasks. Although PTMs have been widely used in most NLP applications, especially for high-resource languages such as English, it is under-represented in Lao NLP research. Previous work on Lao has been hampered by the lack of annotated datasets and the sparsity of language resources. In this work, we construct a text classification dataset to alleviate the resource-scare situation of the Lao language. We additionally present the first transformer-based PTMs for Lao with four versions: BERT-small, BERT-base, ELECTRA-small and ELECTRA-base, and evaluate it over two downstream tasks: part-of-speech tagging and text classification. Experiments demonstrate the effectiveness of our Lao models. We will release our models and datasets to the community, hoping to facilitate the future development of Lao NLP applications.
翻译:在大文版上受过培训的预先语言模型(PLM)能够从背景中捕捉不同层次的概念,从而产生通用语言代表,它们可以有利于多个下游自然语言处理(NLP)任务。虽然PTM在大多数NLP应用中被广泛使用,特别是英语等高资源语言,但在老挝国家语言平台的研究中却代表不足。老挝以往的工作由于缺乏附加说明的数据集和语言资源的广度而受到阻碍。在这项工作中,我们建立一个文本分类数据集,以缓解老挝语言的资源保护状况。我们另外为老挝提供了第一个基于变压器的PTM,有四个版本:BERT-Small、BERT-Base、ELECTRA-S-Small和ELECTRA-Base, 并评价了两个下游任务:语音标记和文字分类部分。实验显示了老挝模式的有效性。我们将向社区发布我们的模型和数据集,希望促进老挝国家语言应用程序的未来发展。