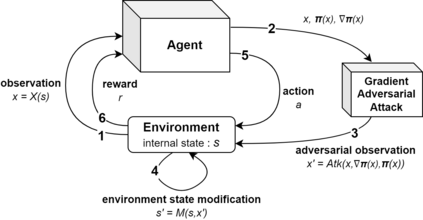
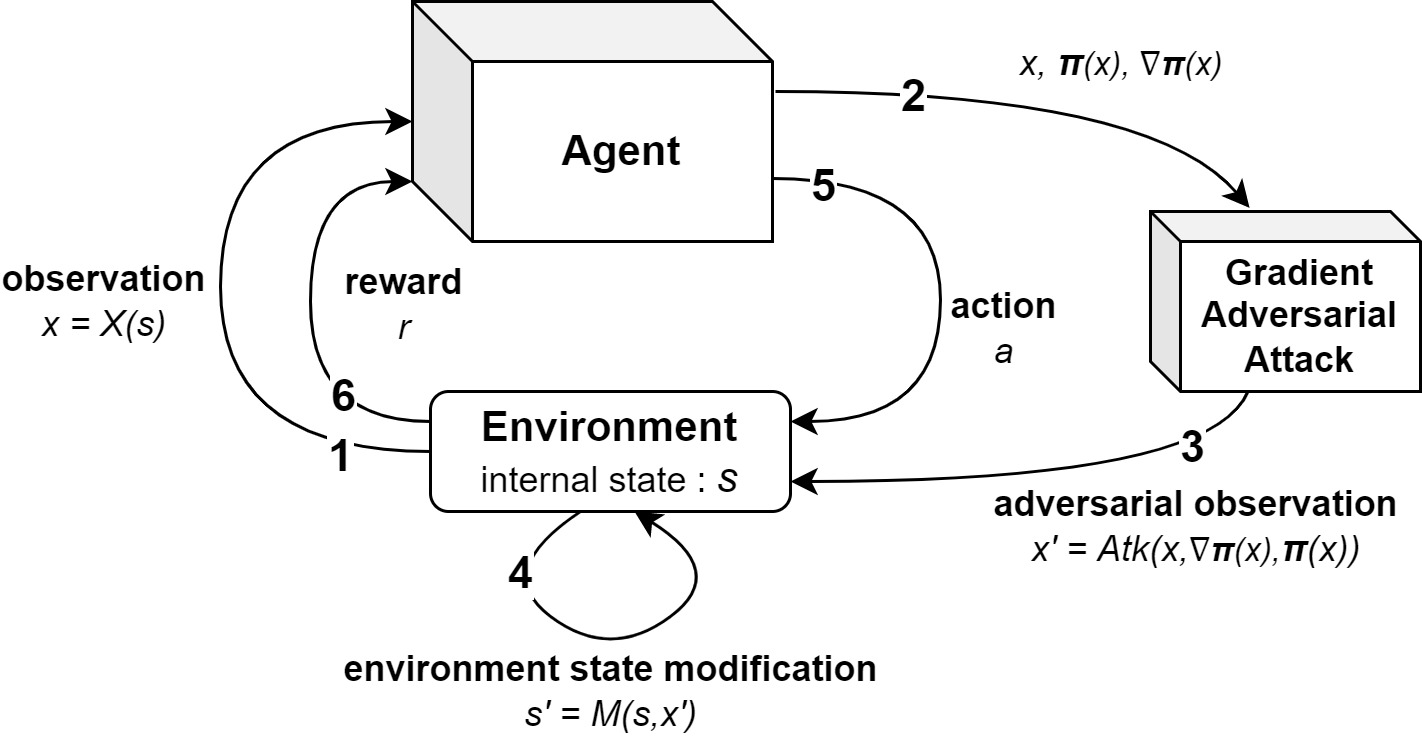
To improve policy robustness of deep reinforcement learning agents, a line of recent works focus on producing disturbances of the environment. Existing approaches of the literature to generate meaningful disturbances of the environment are adversarial reinforcement learning methods. These methods set the problem as a two-player game between the protagonist agent, which learns to perform a task in an environment, and the adversary agent, which learns to disturb the protagonist via modifications of the considered environment. Both protagonist and adversary are trained with deep reinforcement learning algorithms. Alternatively, we propose in this paper to build on gradient-based adversarial attacks, usually used for classification tasks for instance, that we apply on the critic network of the protagonist to identify efficient disturbances of the environment. Rather than learning an attacker policy, which usually reveals as very complex and unstable, we leverage the knowledge of the critic network of the protagonist, to dynamically complexify the task at each step of the learning process. We show that our method, while being faster and lighter, leads to significantly better improvements in policy robustness than existing methods of the literature.
翻译:为提高深层强化学习机构的政策稳健性,最近一行工作的重点是制造环境扰动。现有的文献文献中产生有意义的环境扰动的方法是对抗性强化学习方法。这些方法将问题设定为主角(学会在环境中执行任务)和对手(学会通过改变经过深思熟虑的环境来扰乱主角)之间的双玩游戏。无论是主角还是对手,都经过深思熟虑的学习算法的培训。或者,我们在本文件中提议,在基于梯度的对抗性攻击的基础上,通常用于分类等目的,我们应用于主角的批评者网络,以查明有效的环境扰动。我们不是学习通常非常复杂和不稳定的进攻者政策,而是利用主角批评者网络的知识,在学习过程的每一阶段都动态地使任务复杂化。我们表明,我们的方法虽然速度更快、较轻,但比现有的文献方法在政策稳健性方面有了显著的改进。